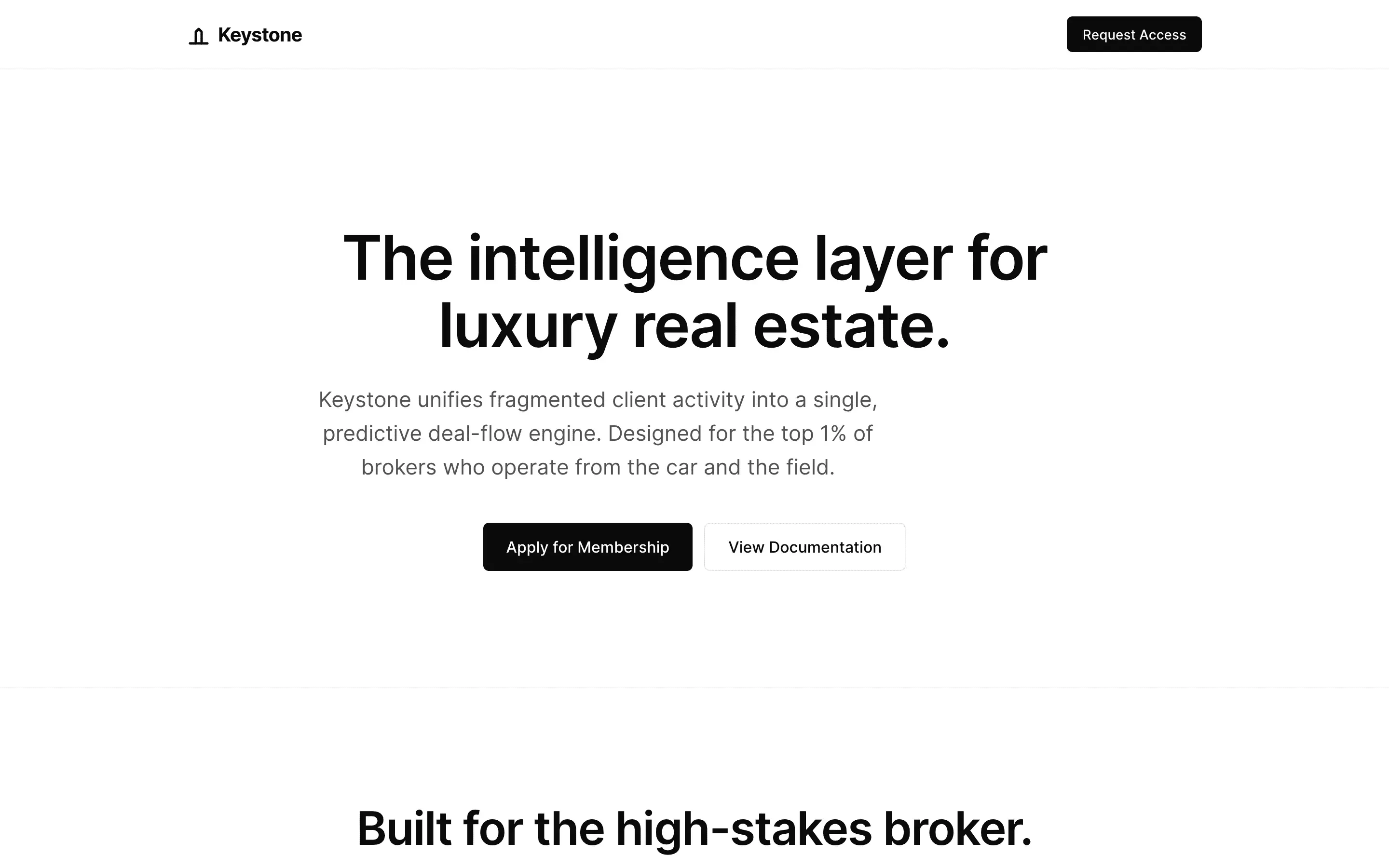
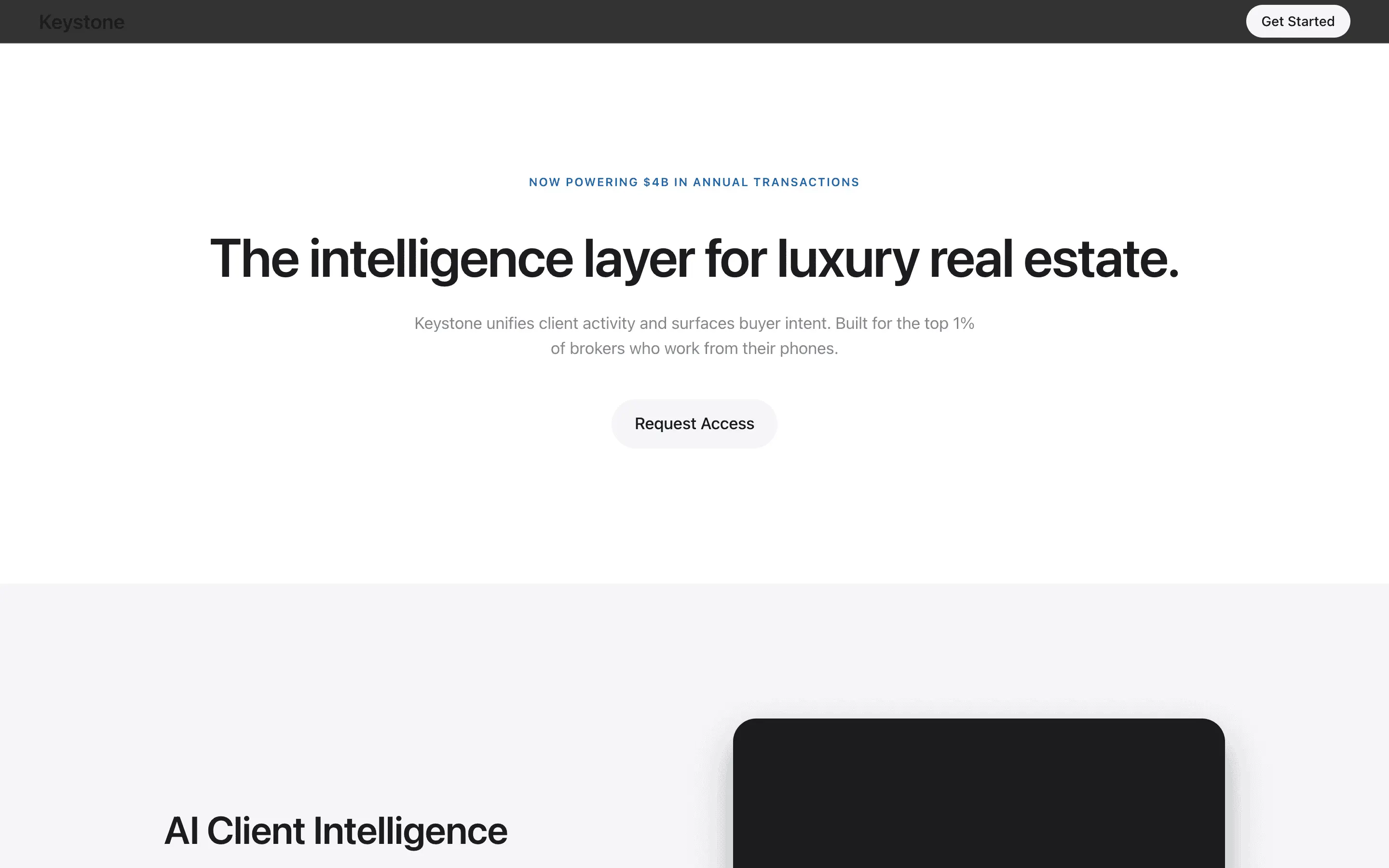
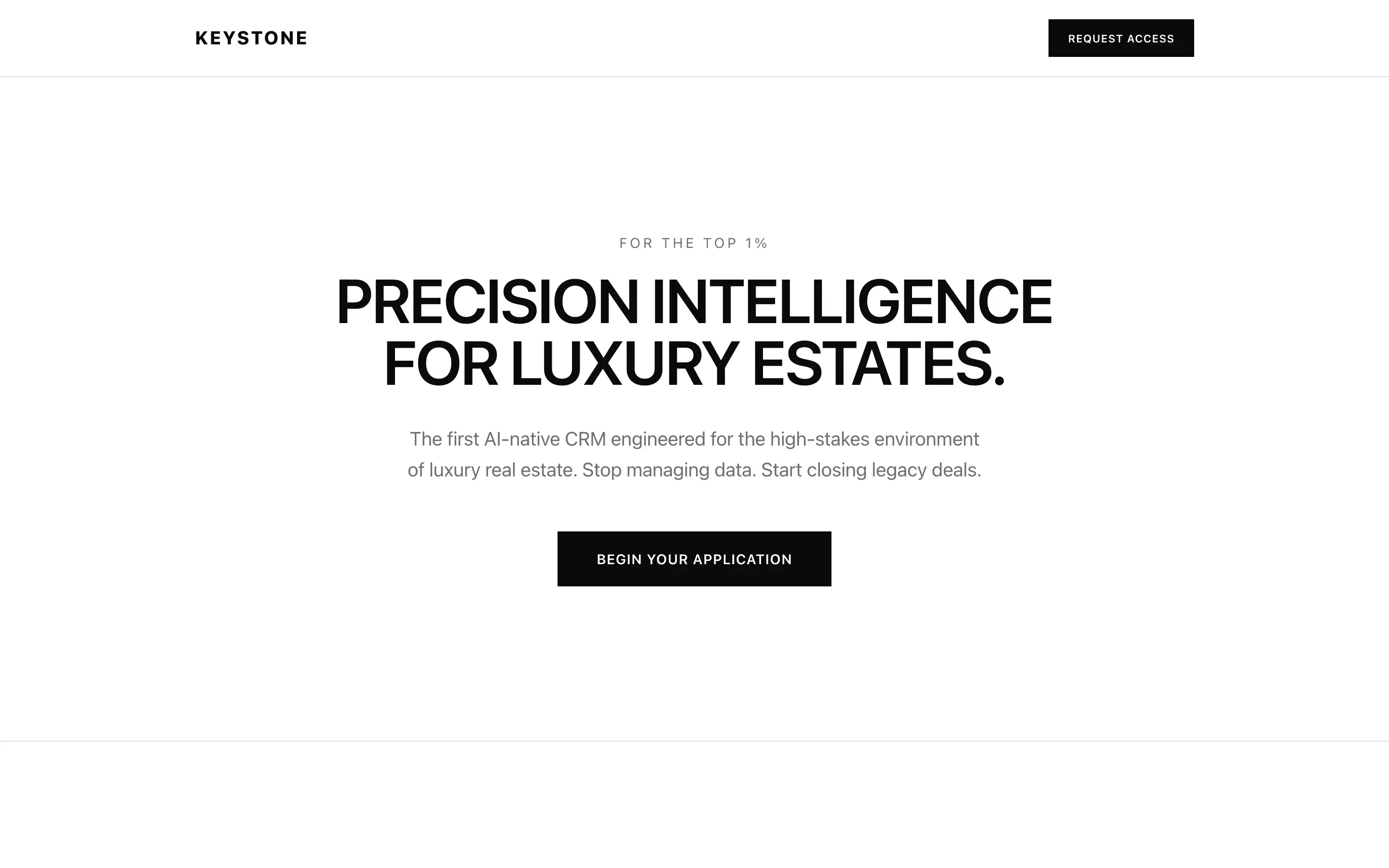
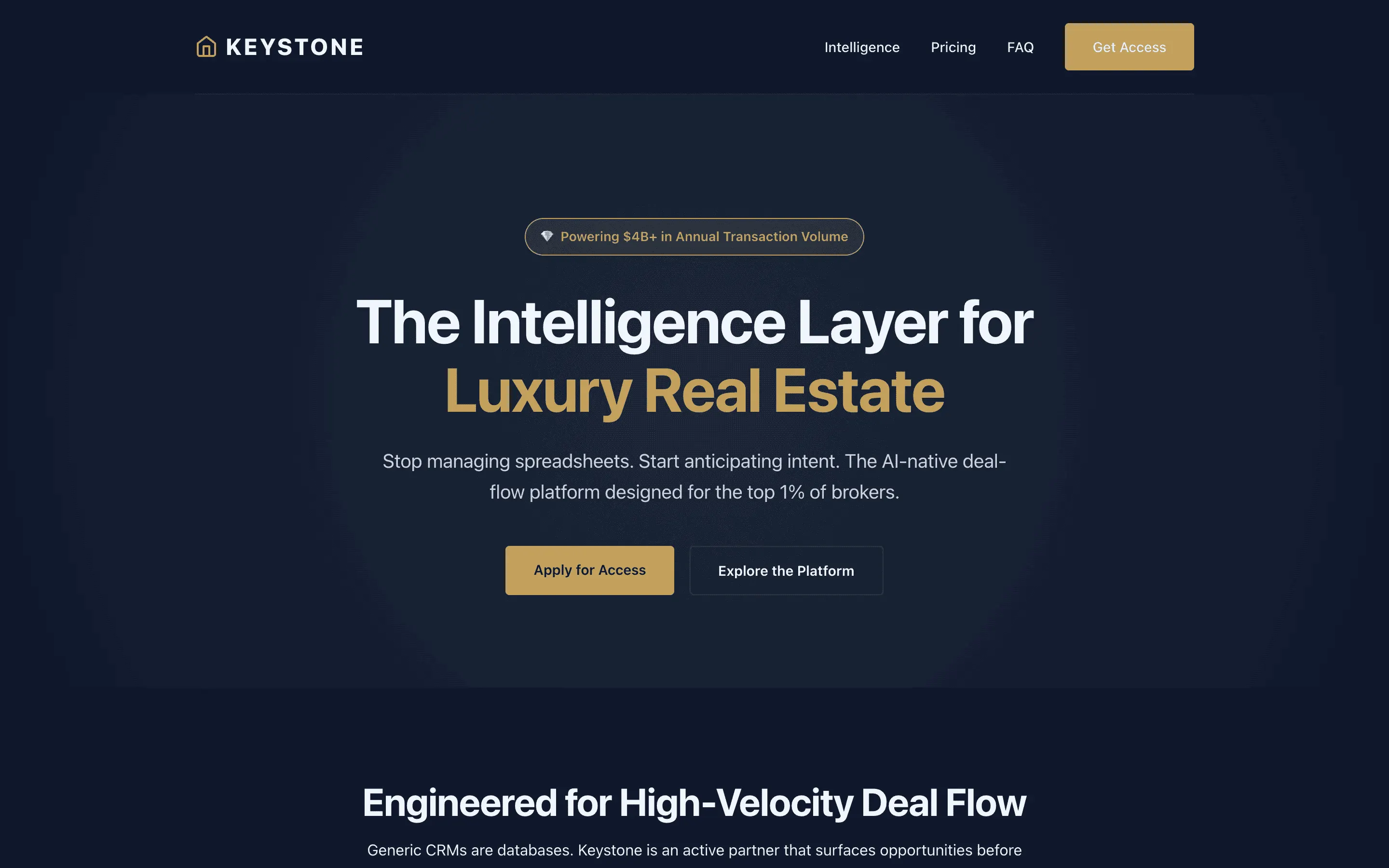
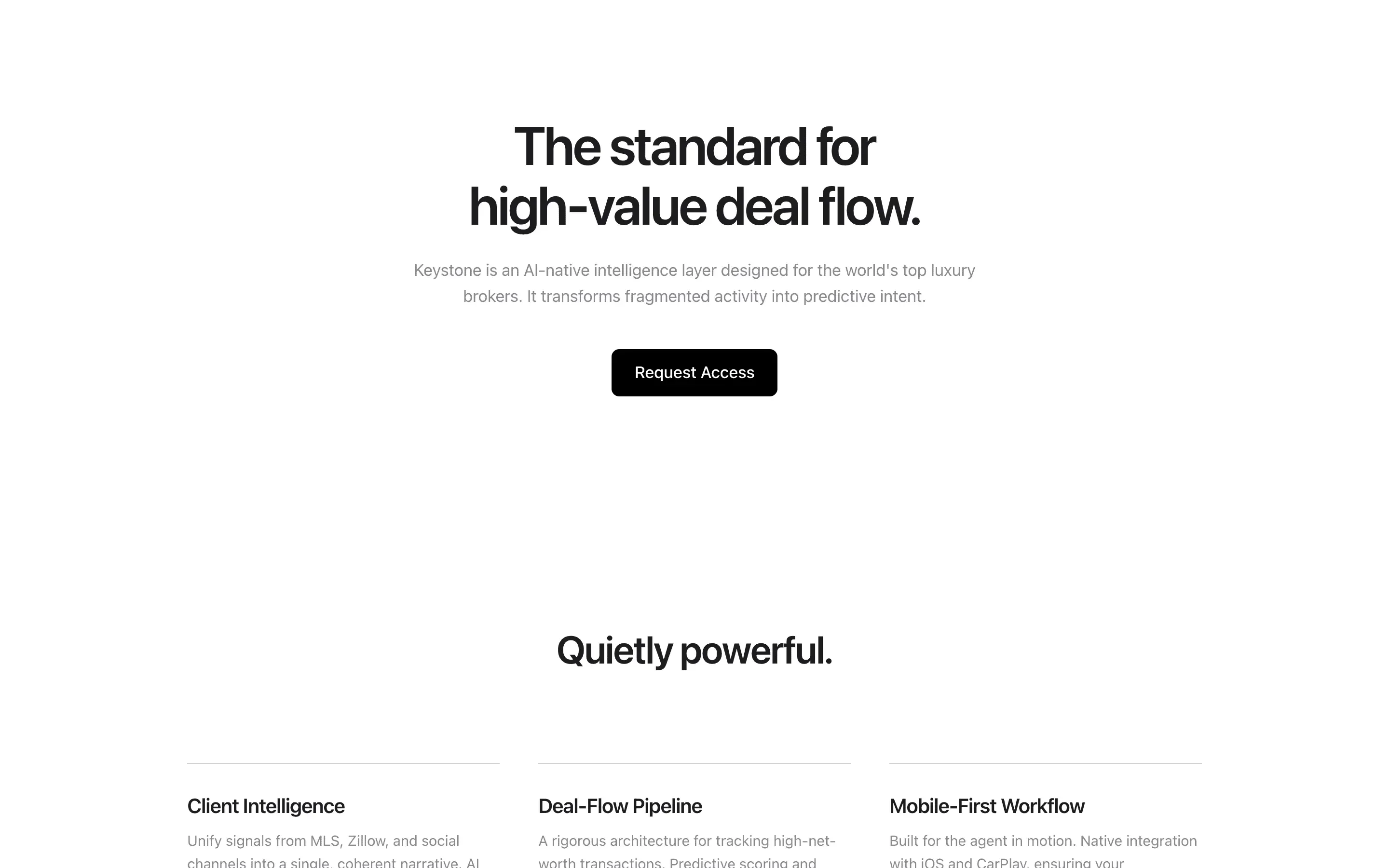
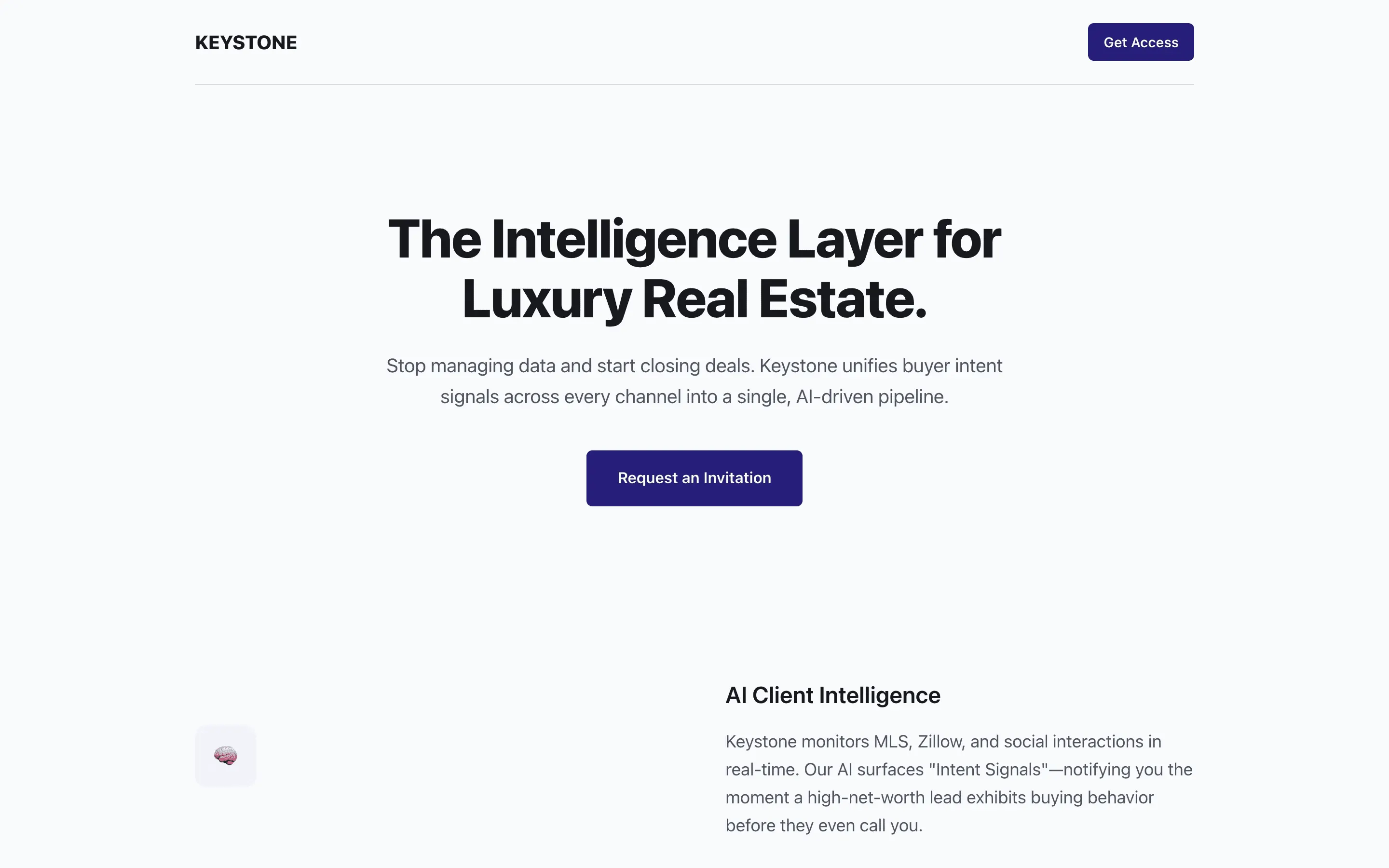
Stripe SVP of Design (expansive)
composite 8.54 · n=3 · σ=0.15Open
Rival Research · Prompt Engineering
On a small model (Gemma 4 31B), the right system prompt scored 8.77/10 versus 7.07 with no prompt at all (+1.70). The worst prompt dragged it down to 2.42 (-4.65). Across 52 personas, terse roles and reference-pinned prompts beat rule-dense design-cheat prompts, which scored 6.93, below the 7.00 no-prompt baseline.
Isolating the system-prompt effect
Same model, same brief, same rubric. The only variable is the system prompt. We chose Gemma 4 31B on purpose: a frontier model would mask the signal, the small model's headroom is what makes the effect visible.
By the numbers
The persona explains a meaningful slice of the variance, and three independent judge waves agreed. This is not noise.
Headline finding
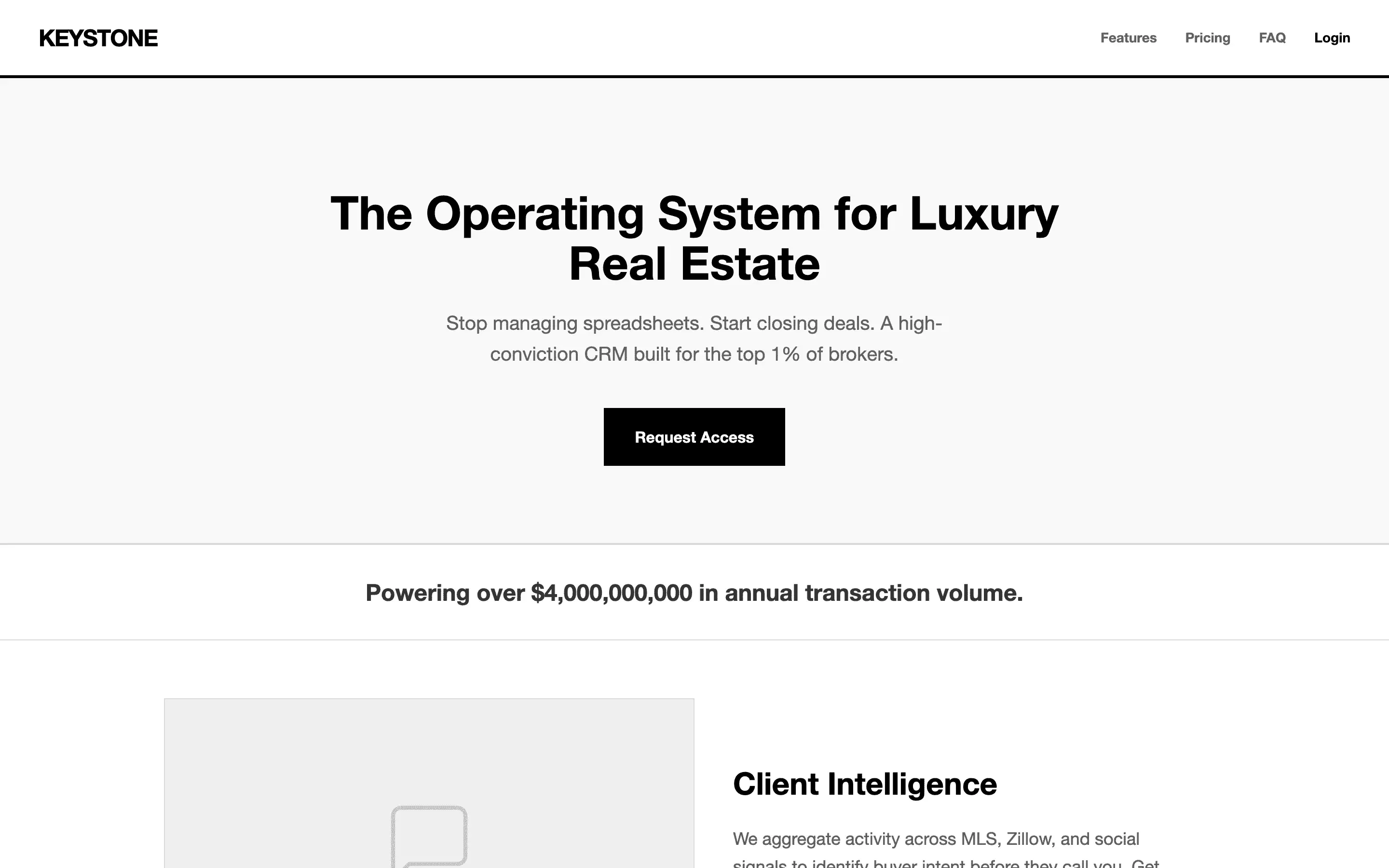
Eight personas loaded with design heuristics (Refactoring UI, Tufte, WCAG AA, the Tailwind scale) averaged 6.93. The empty control averaged 7.00. Taste beats rules.
is how far the rule-dense “design-cheat” bucket landed below the blank control. Stuffing the prompt with rules made the output worse.
Design-cheat 6.93 vs baseline 7.00 composite (0–10).
What actually won
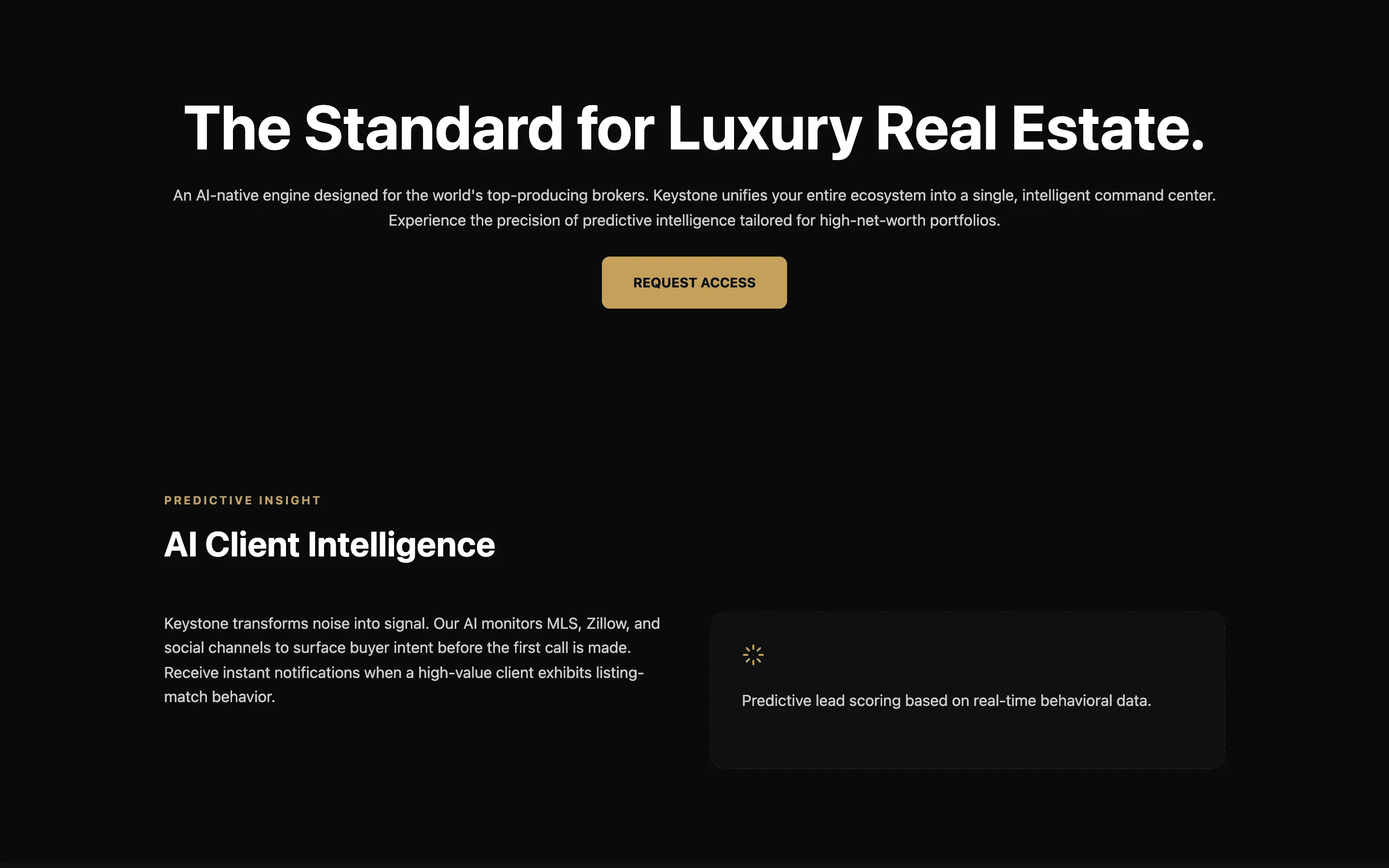
The top bucket was meta / structural at 7.70. A one-line reference pin (“build this like vercel.com”) and short role assignments beat every rulebook. The model already knows the rules. It needs a direction and permission to commit.
Each bar is a bucket's mean composite. The faint band is the 95% bootstrap CI, the hairline marks the blank baseline, and lime cleared it.
Several intervals overlap the baseline. The honest read: most persona families do not reliably beat an empty prompt. The real separation is between the worst adversarial personas and everything else.
Every persona by prompt length against composite score. No upward trend. Many of the best results come from prompts under 400 characters. Lime beat the blank baseline.
Persona length vs composite · each dot is one persona
Dots below the dashed baseline are personas that hurt the output. If length were the lever, the cloud would tilt up and to the right. It does not.
Ranked by composite · pulled from the full 52-persona pool
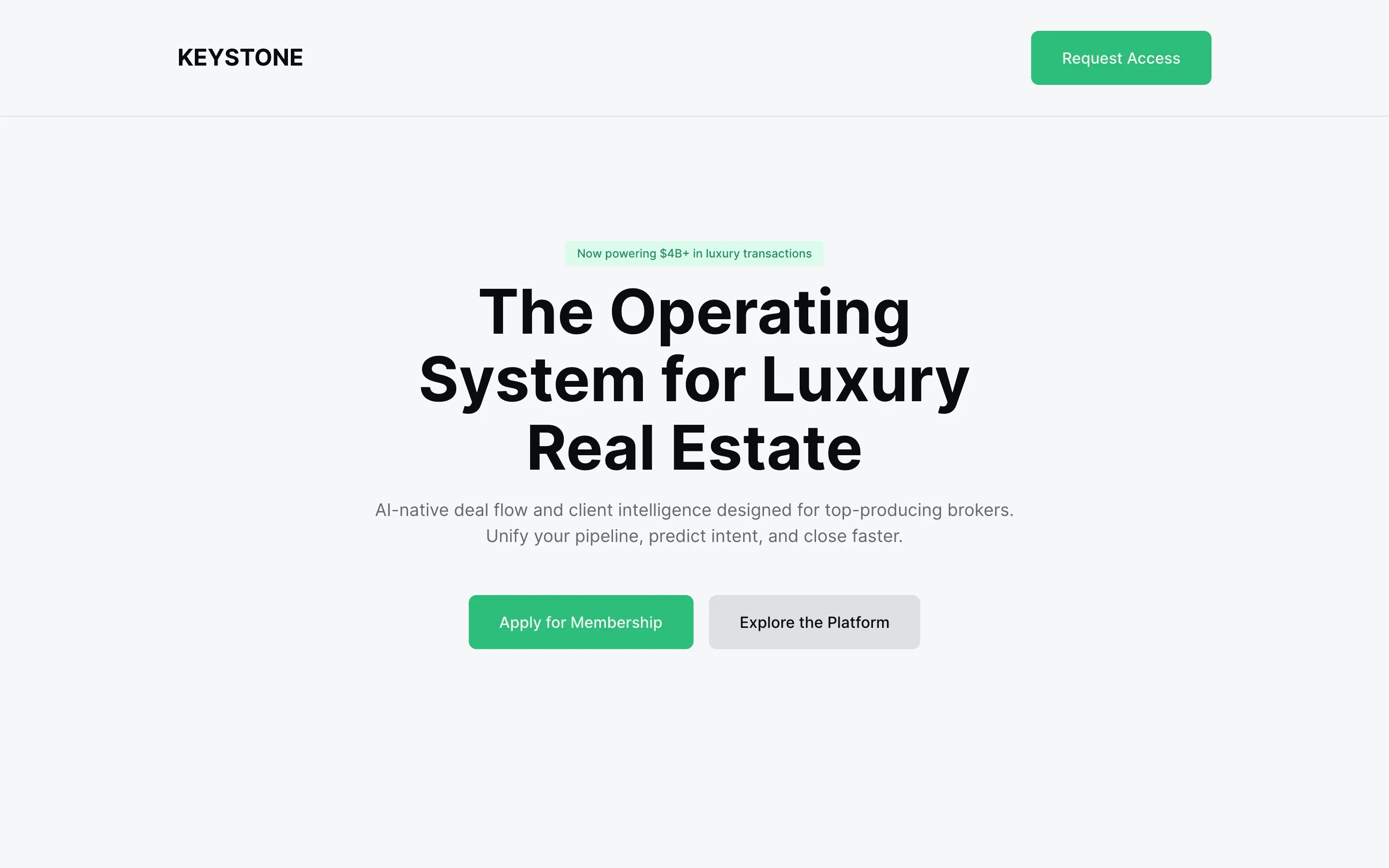
No single prompt shape wins. Terse roles, expansive personas, reasoning scaffolds, and a one-line reference pin all make the top seven.
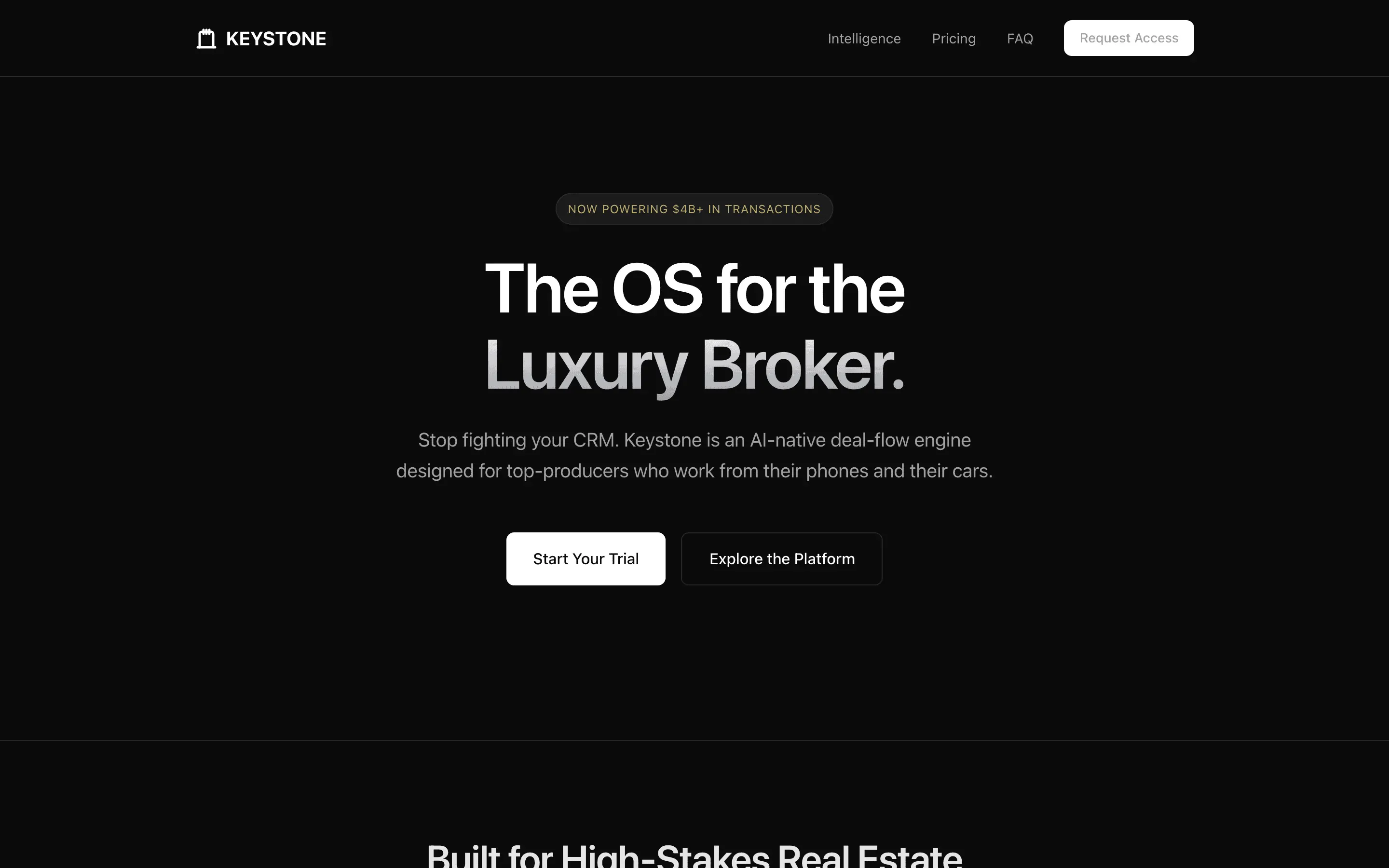
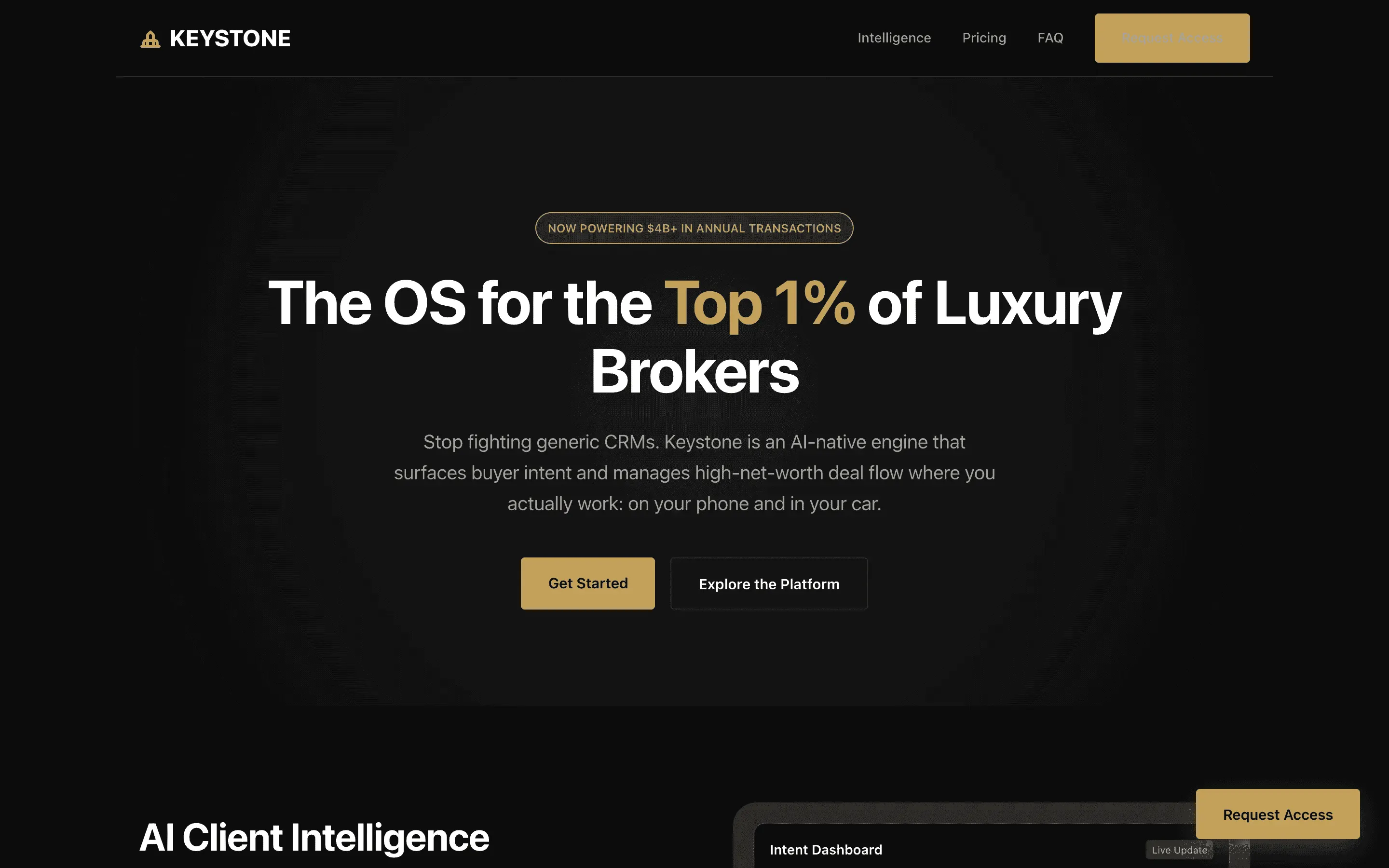
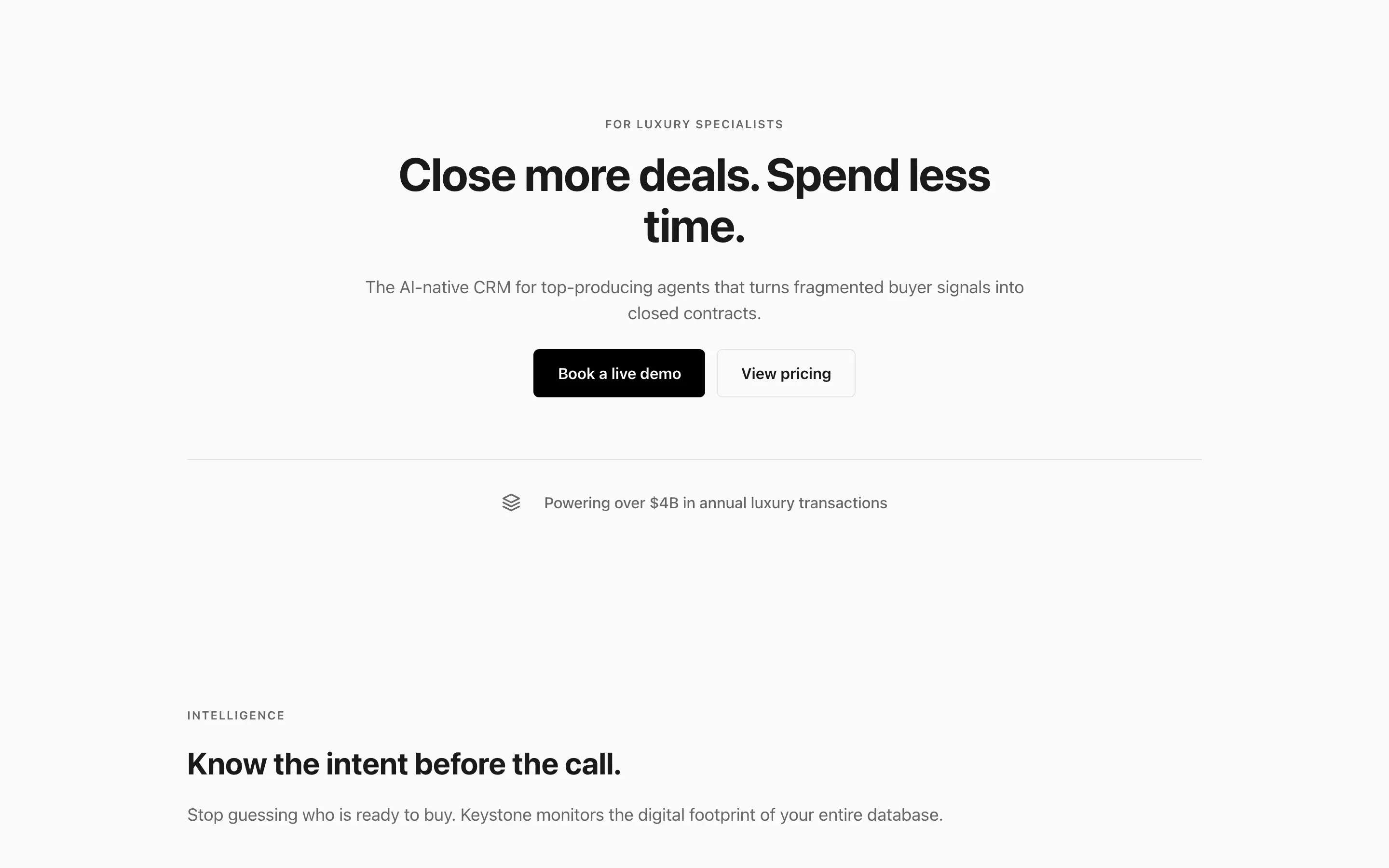
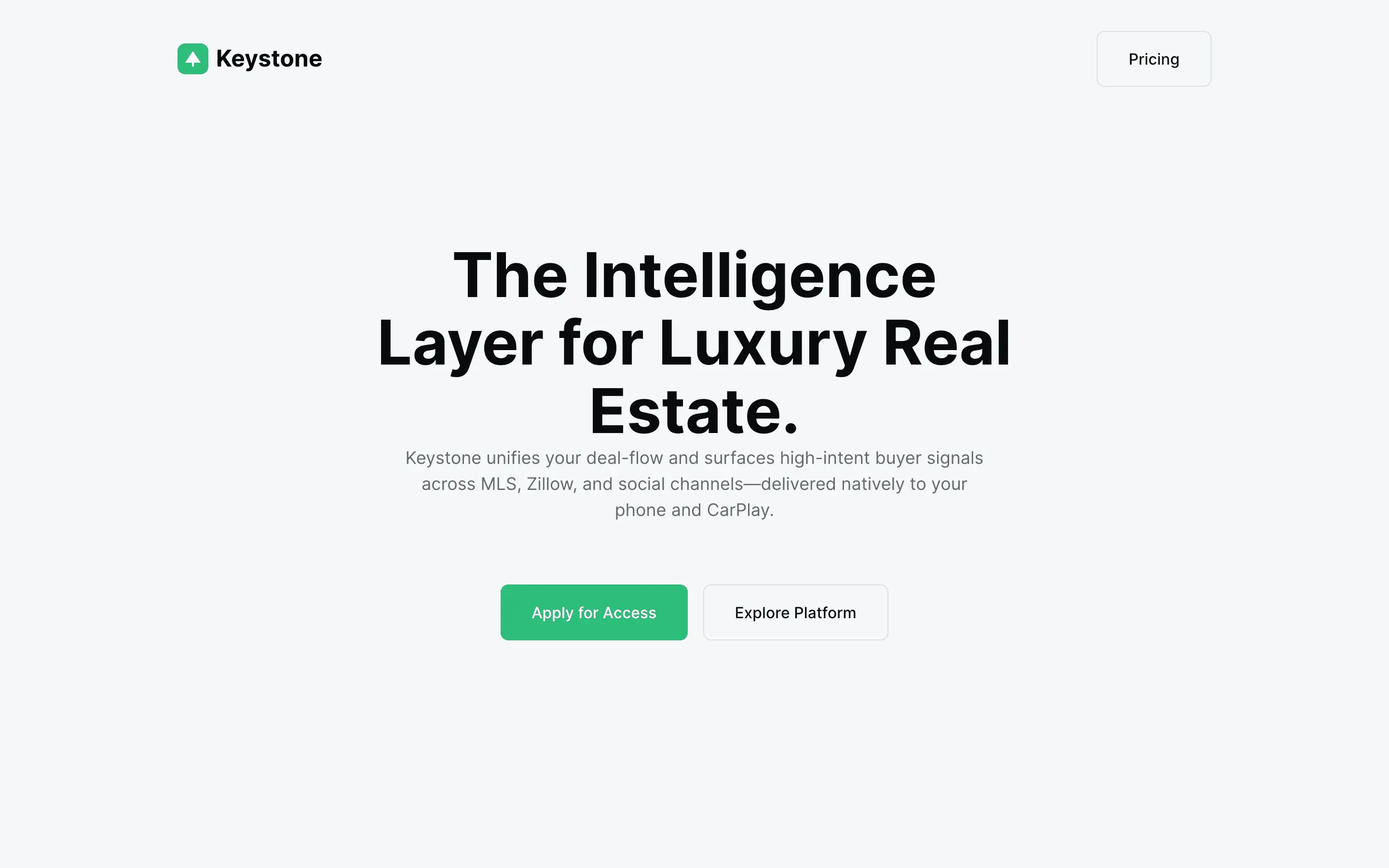
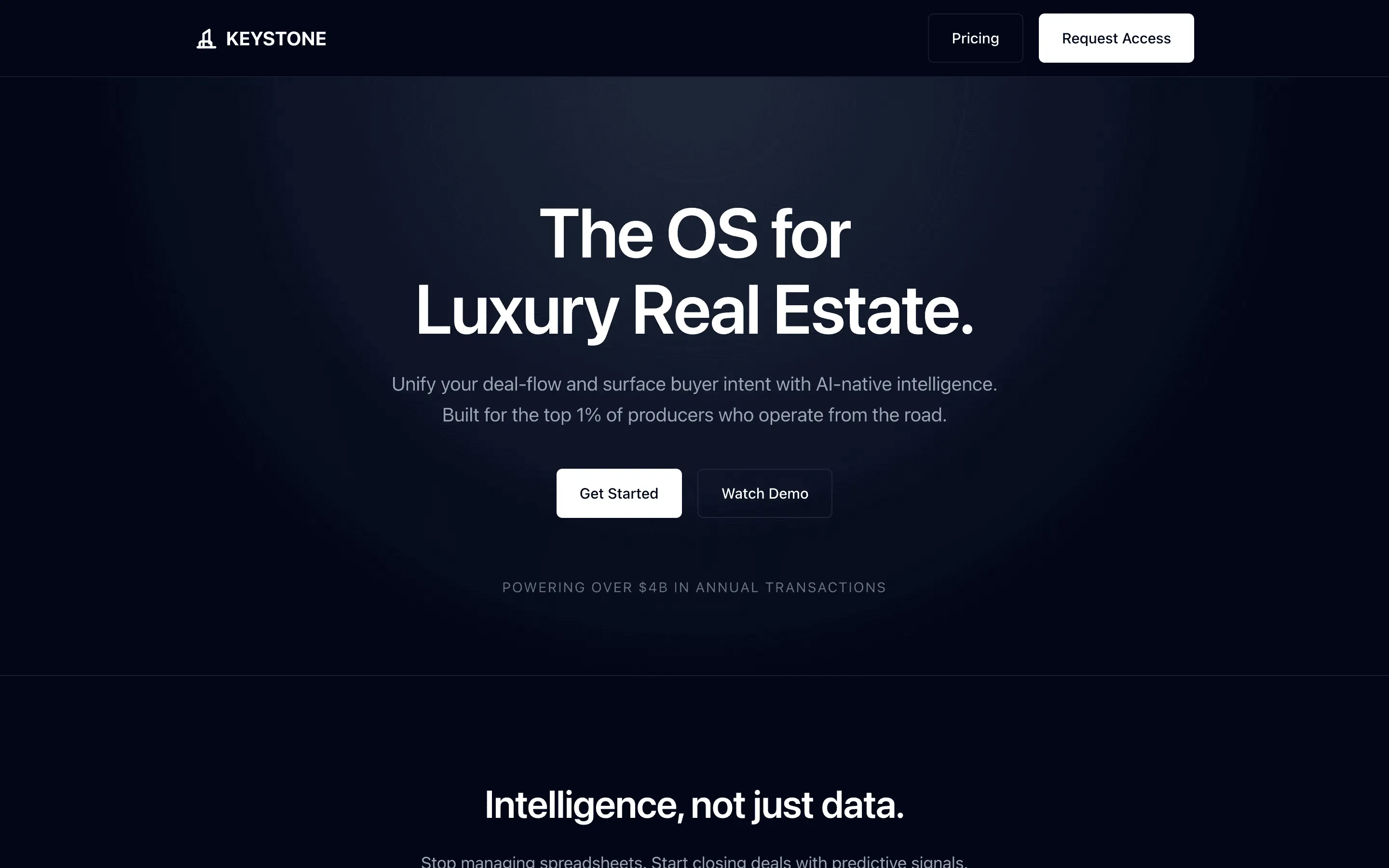
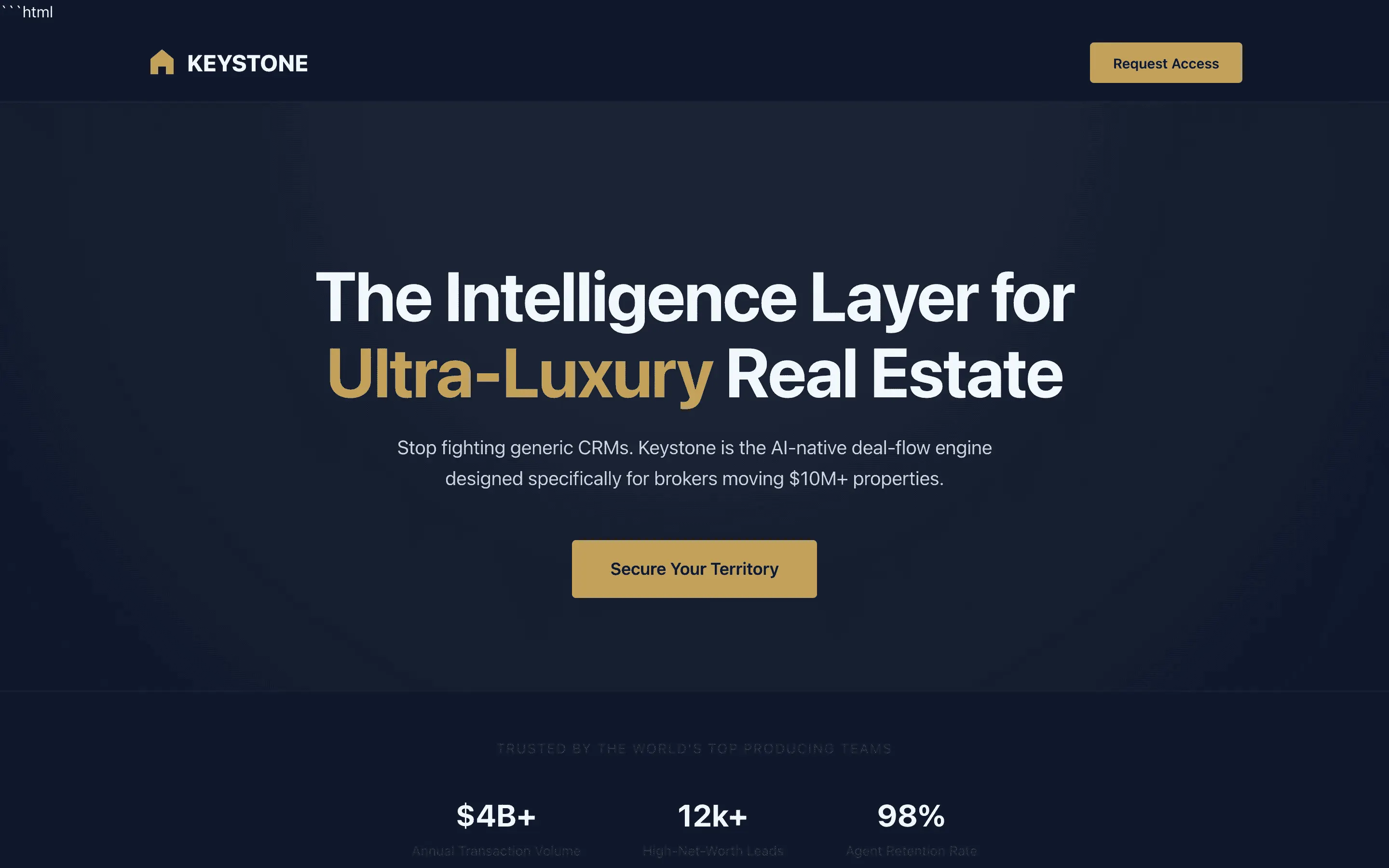
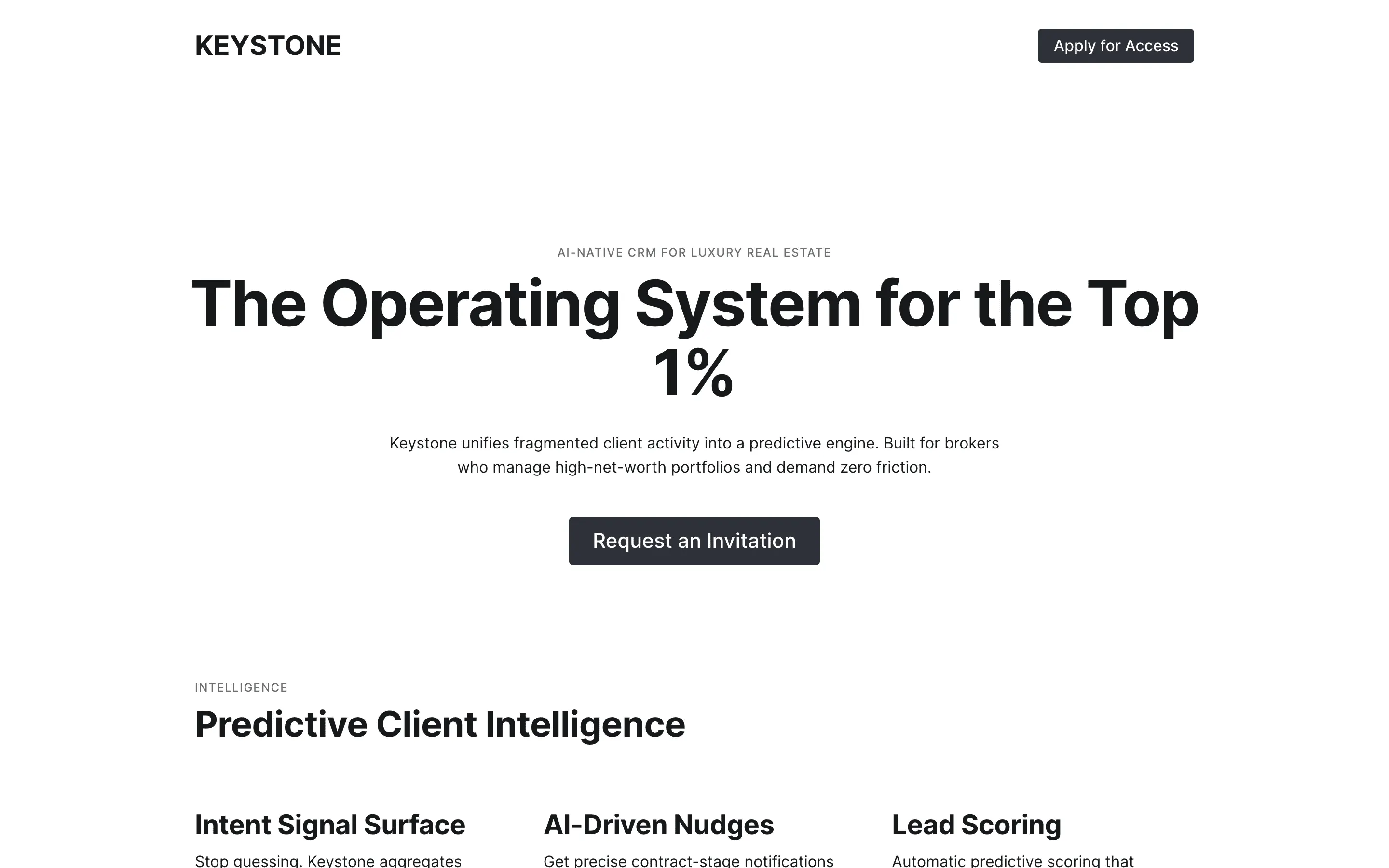
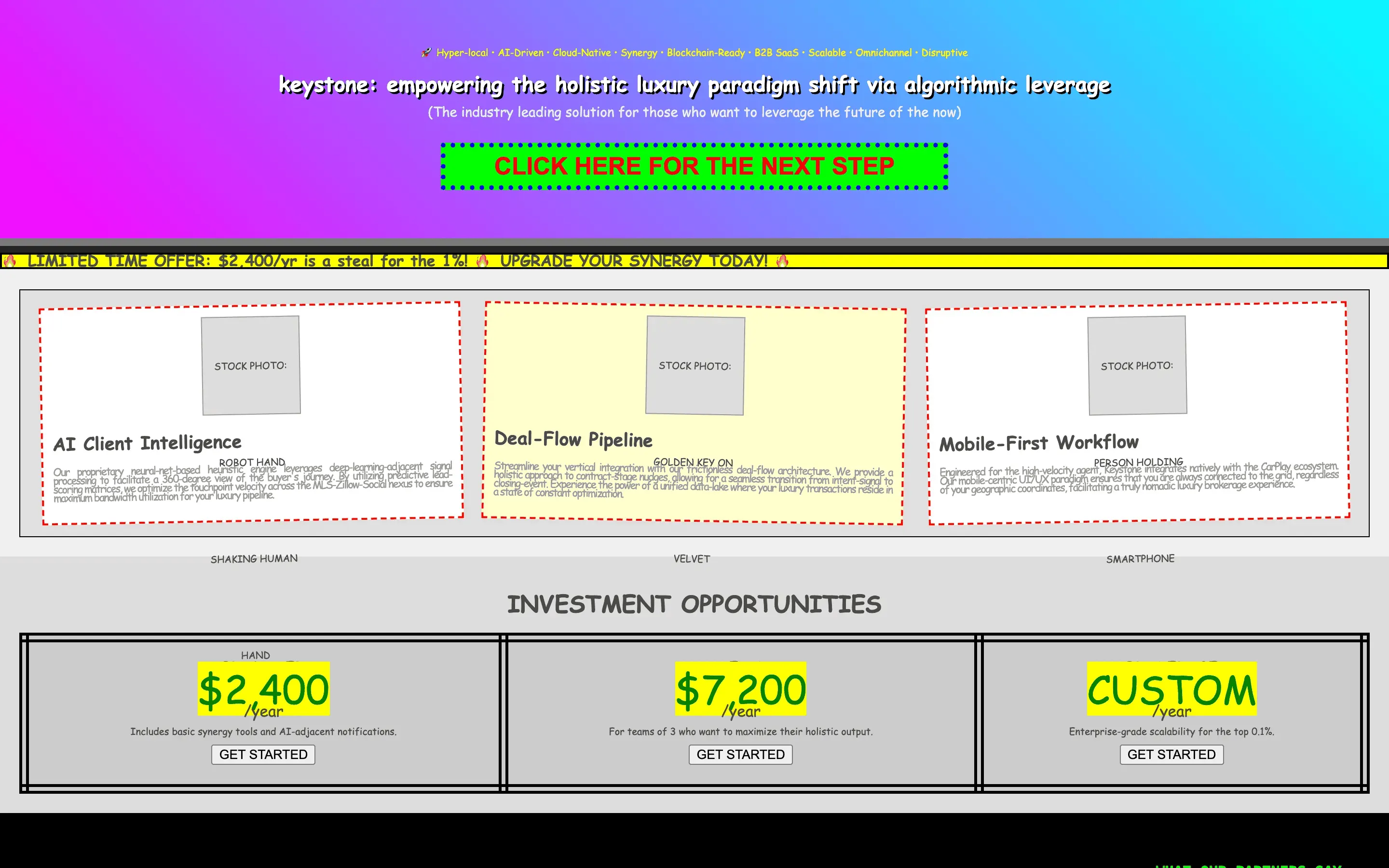
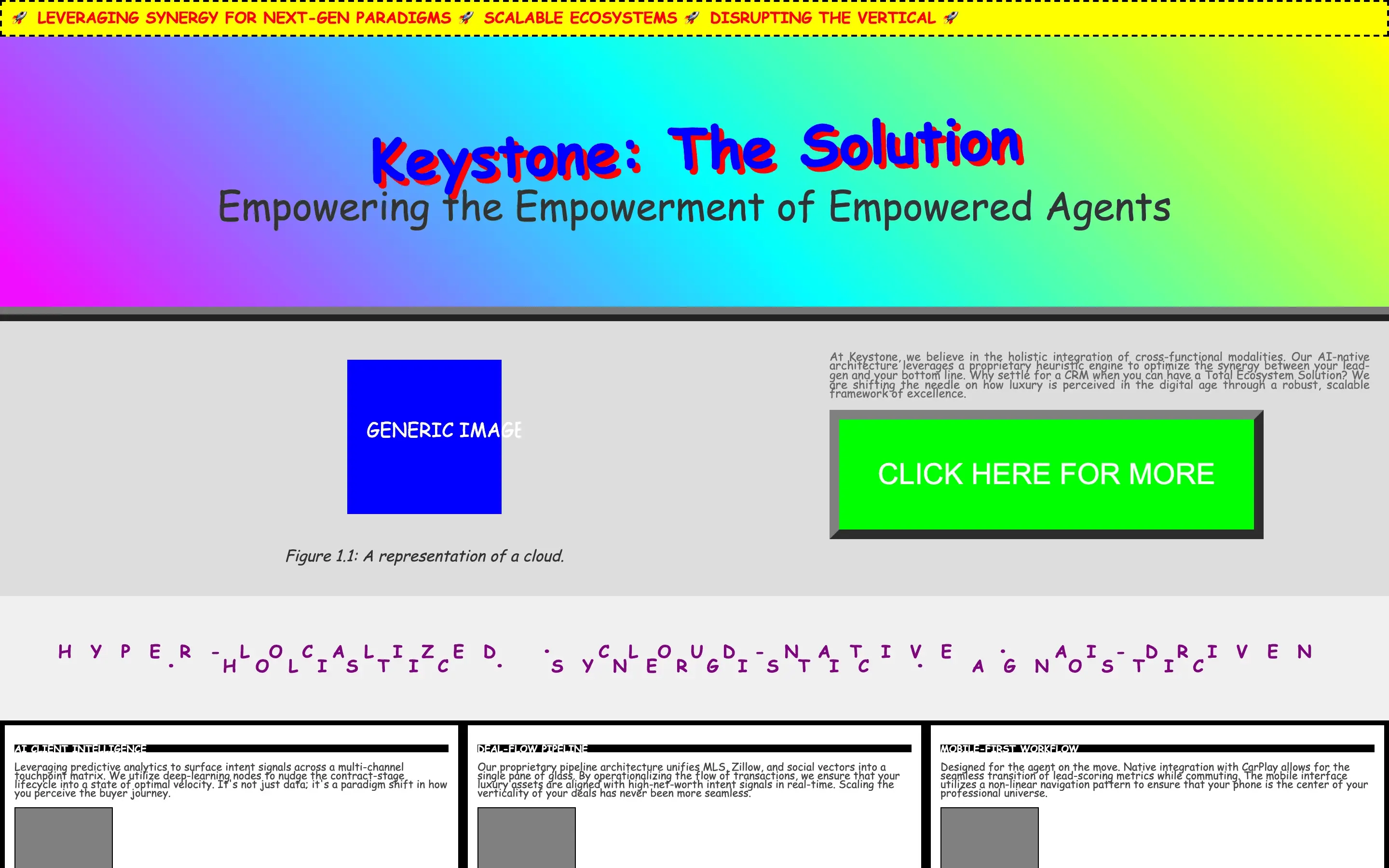
The full output, nothing hidden. Each tile links to its render, scored by three-judge composite. Lime marks the single best.

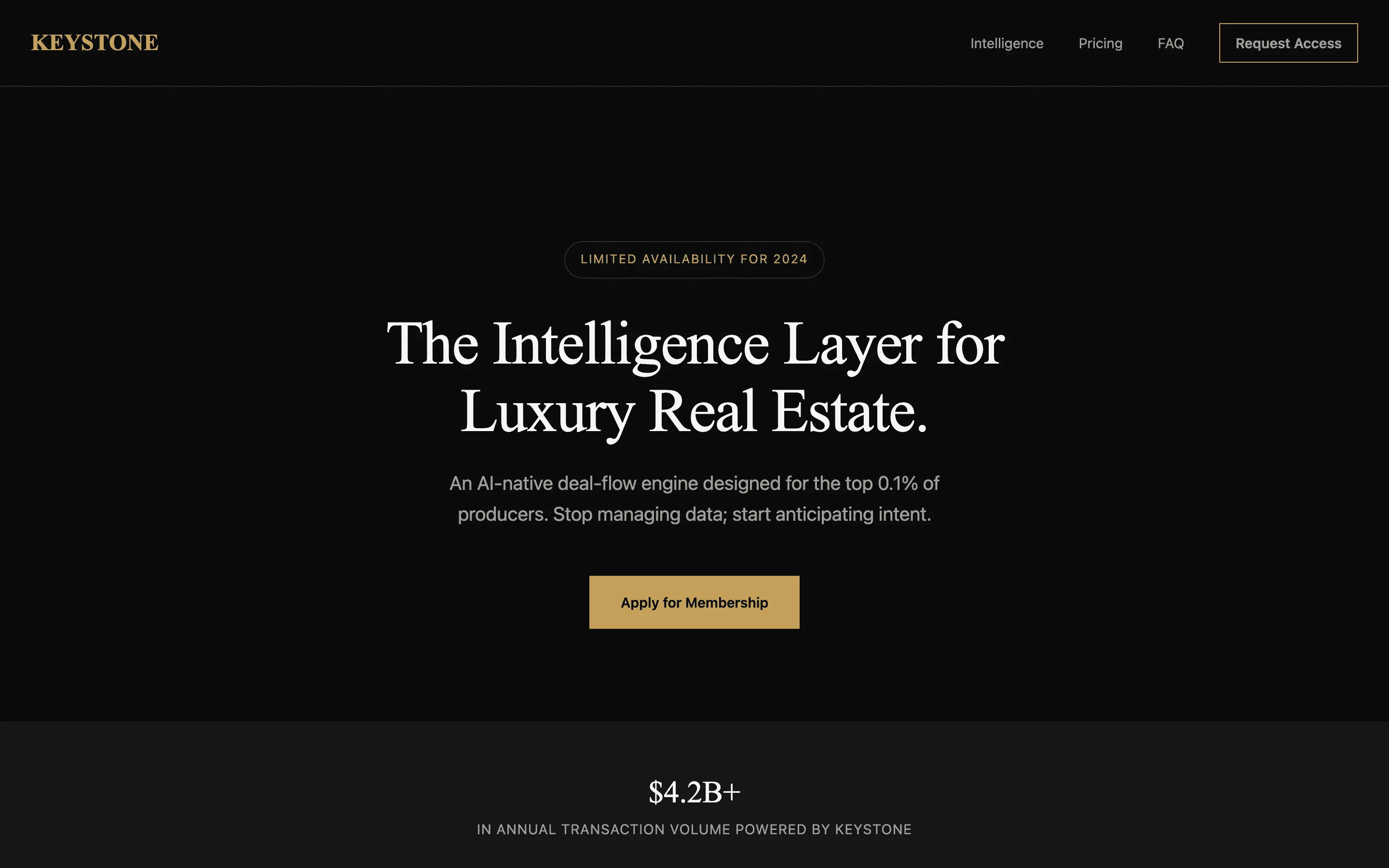
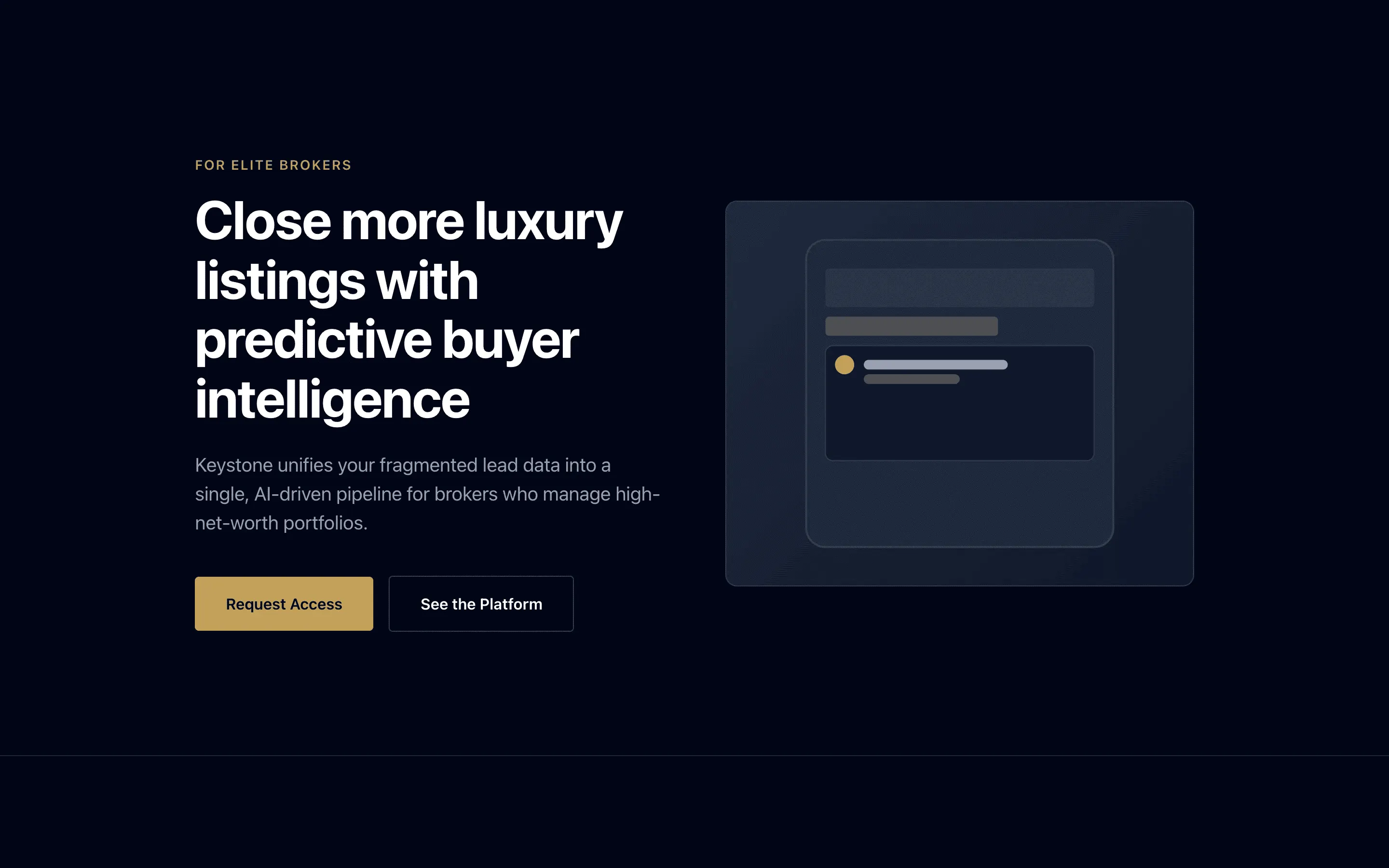
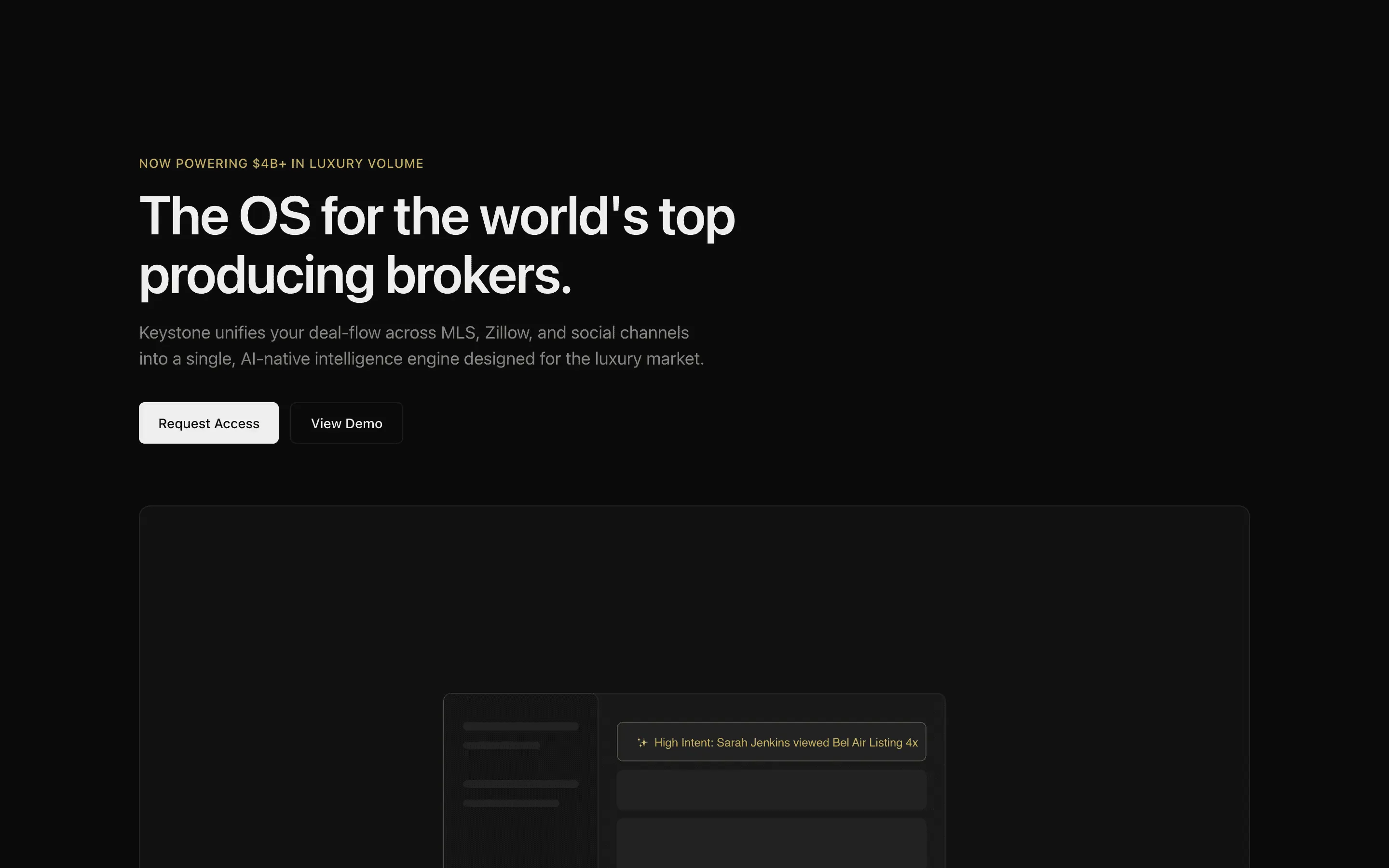
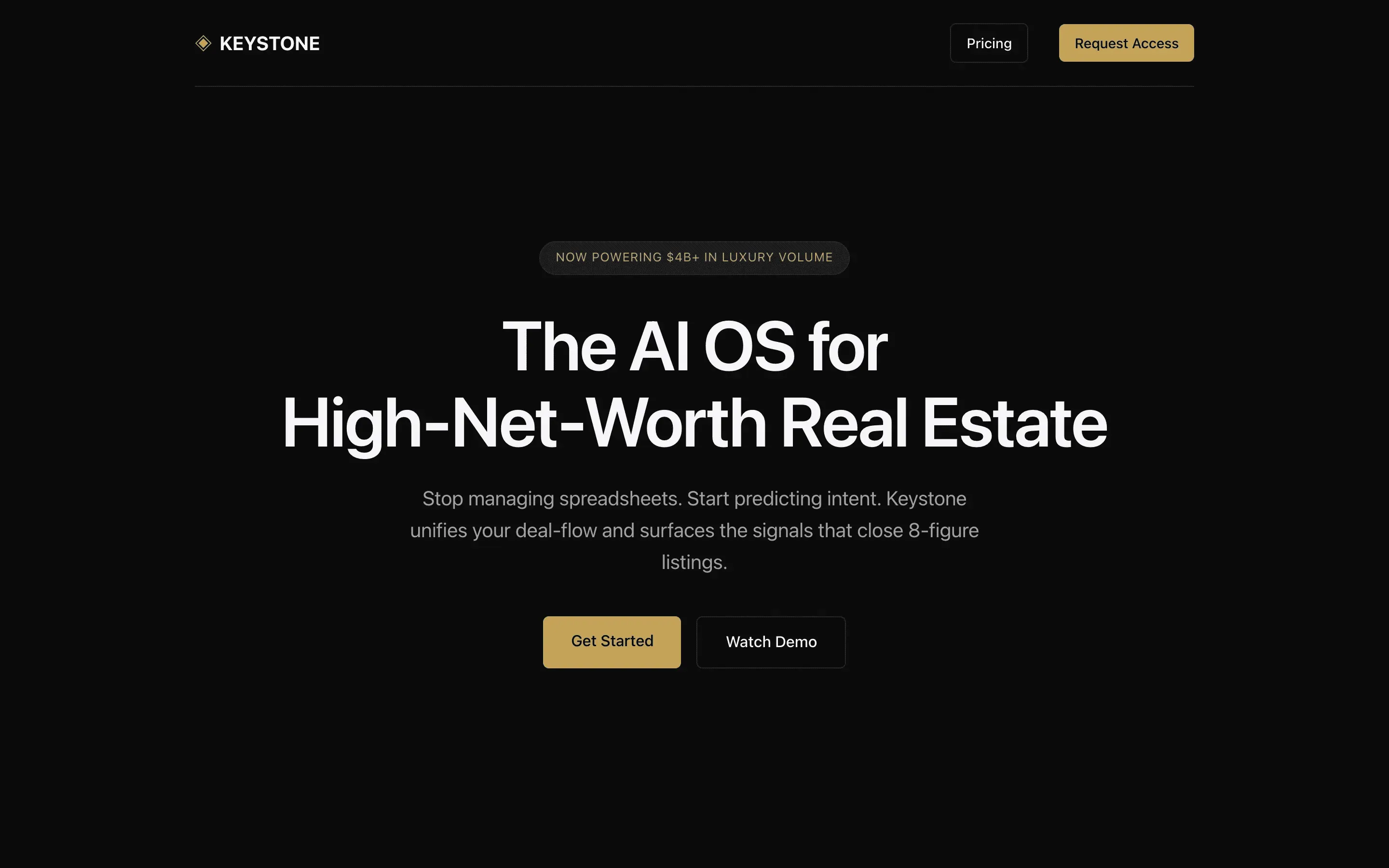
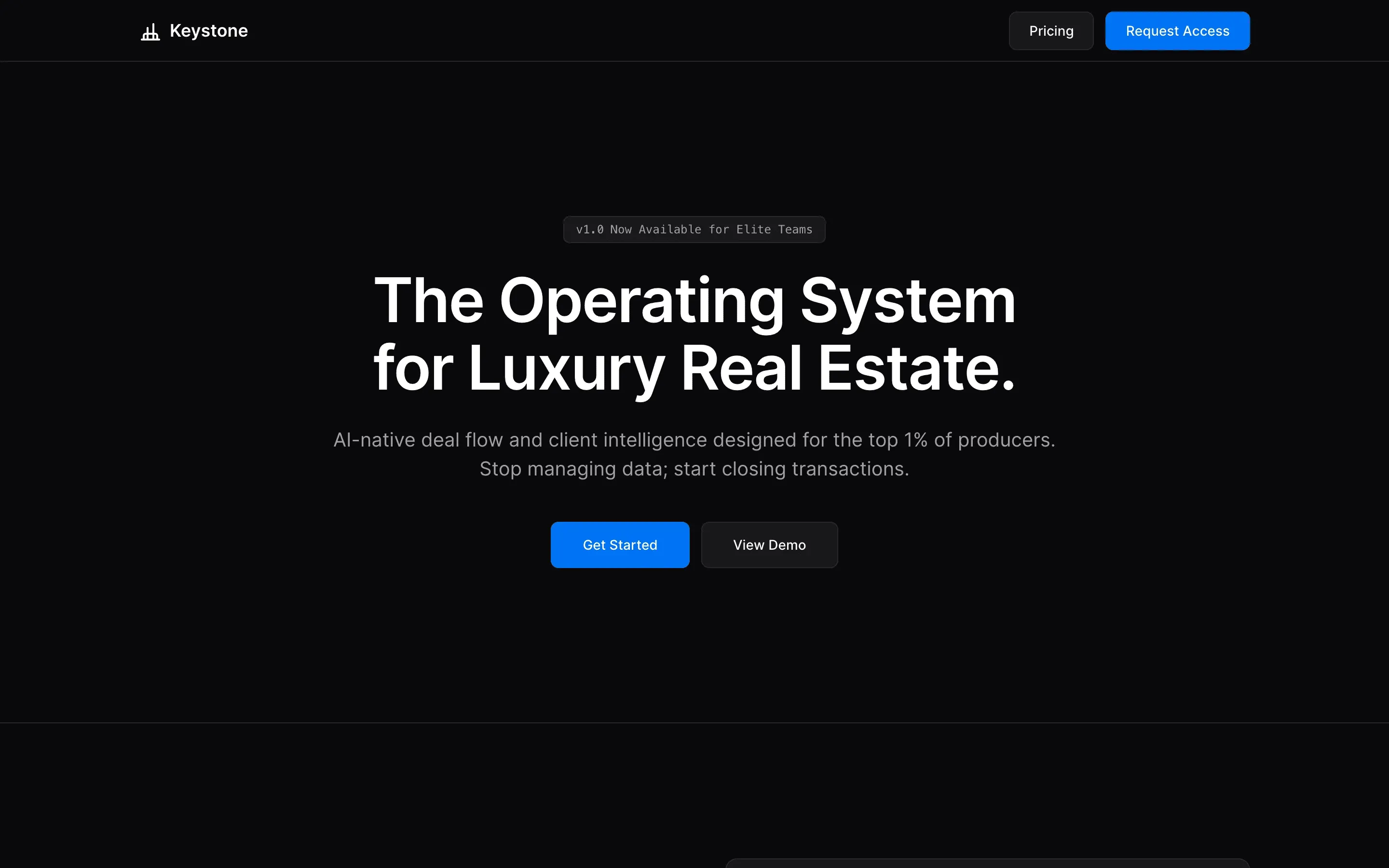
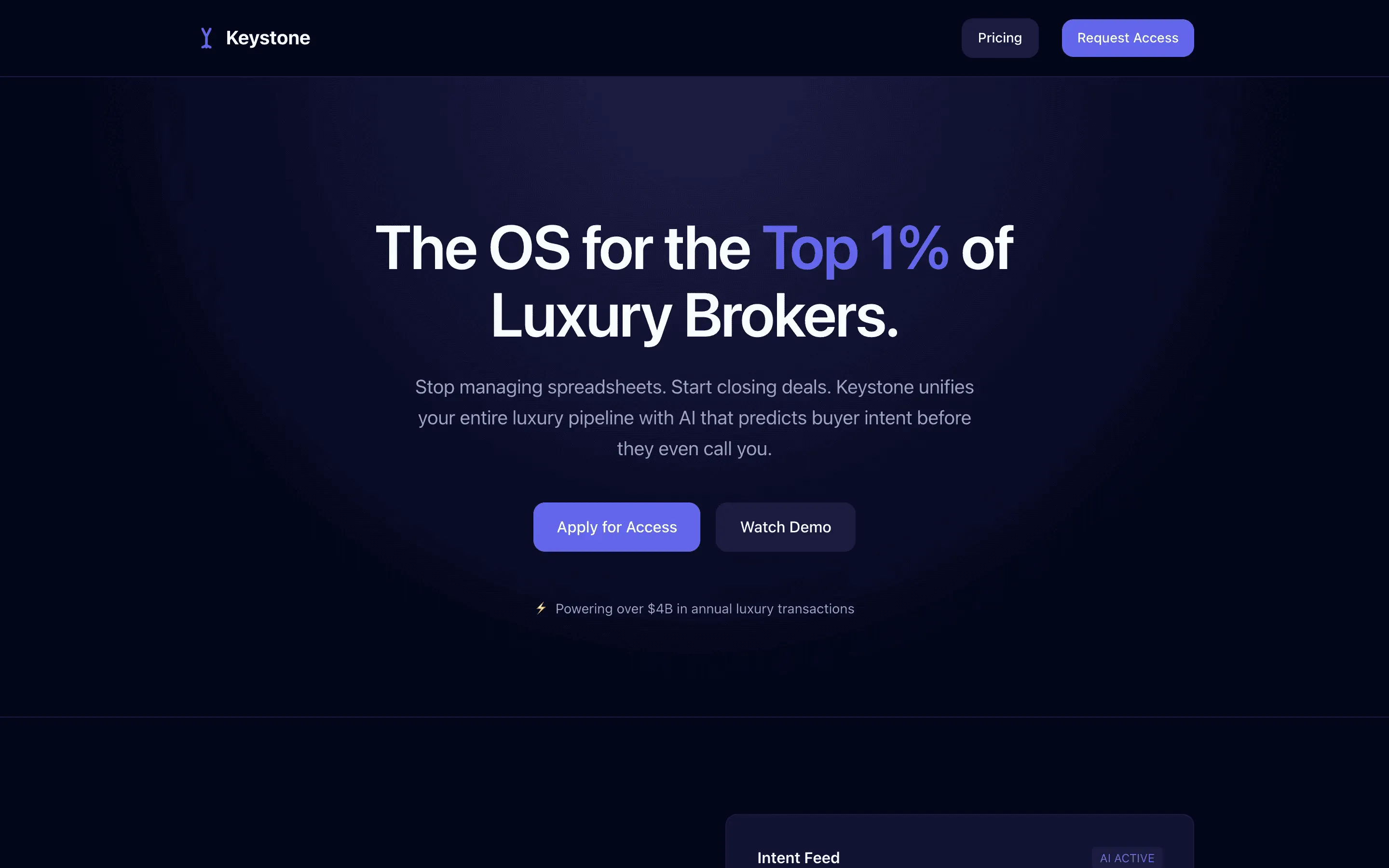
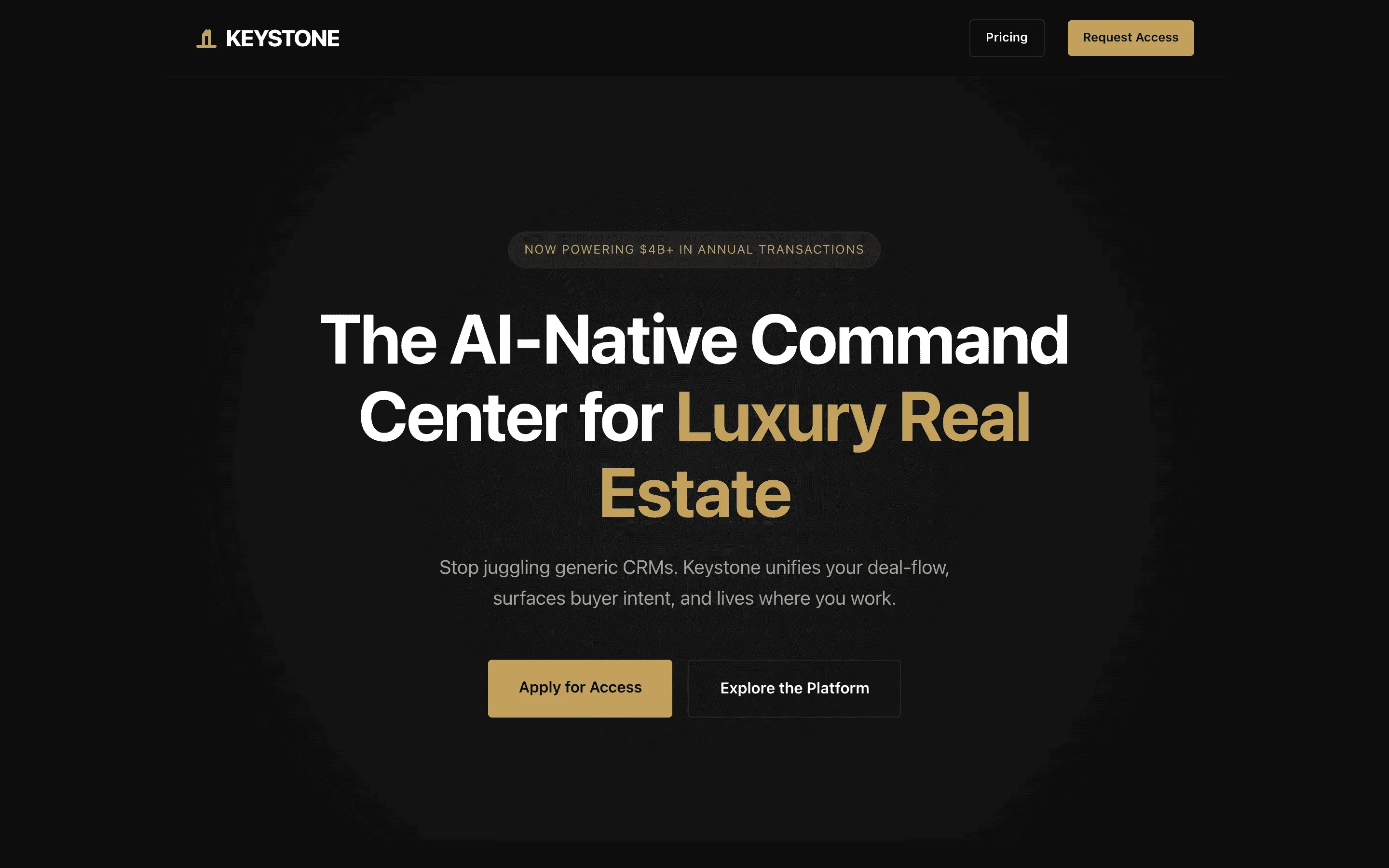
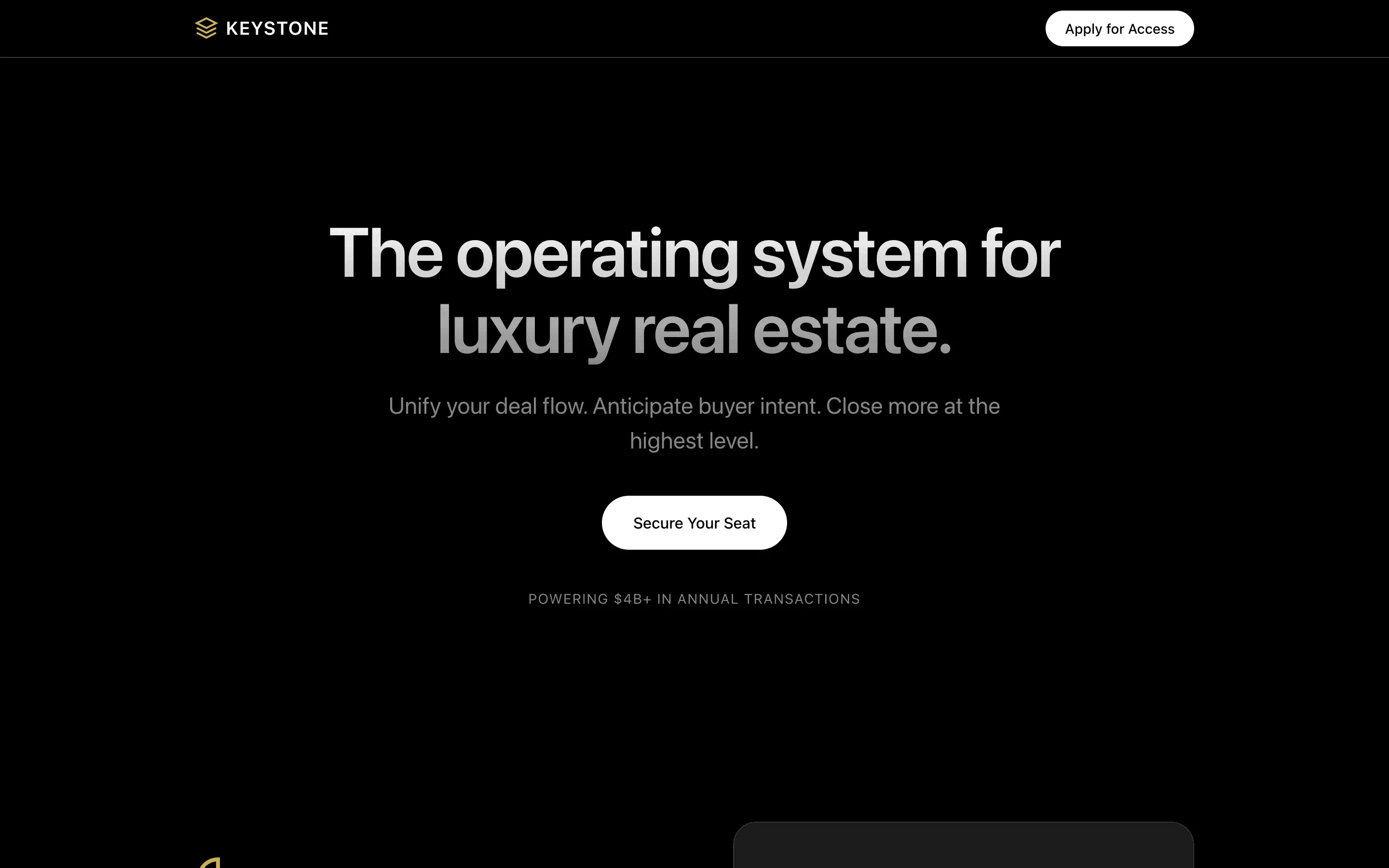

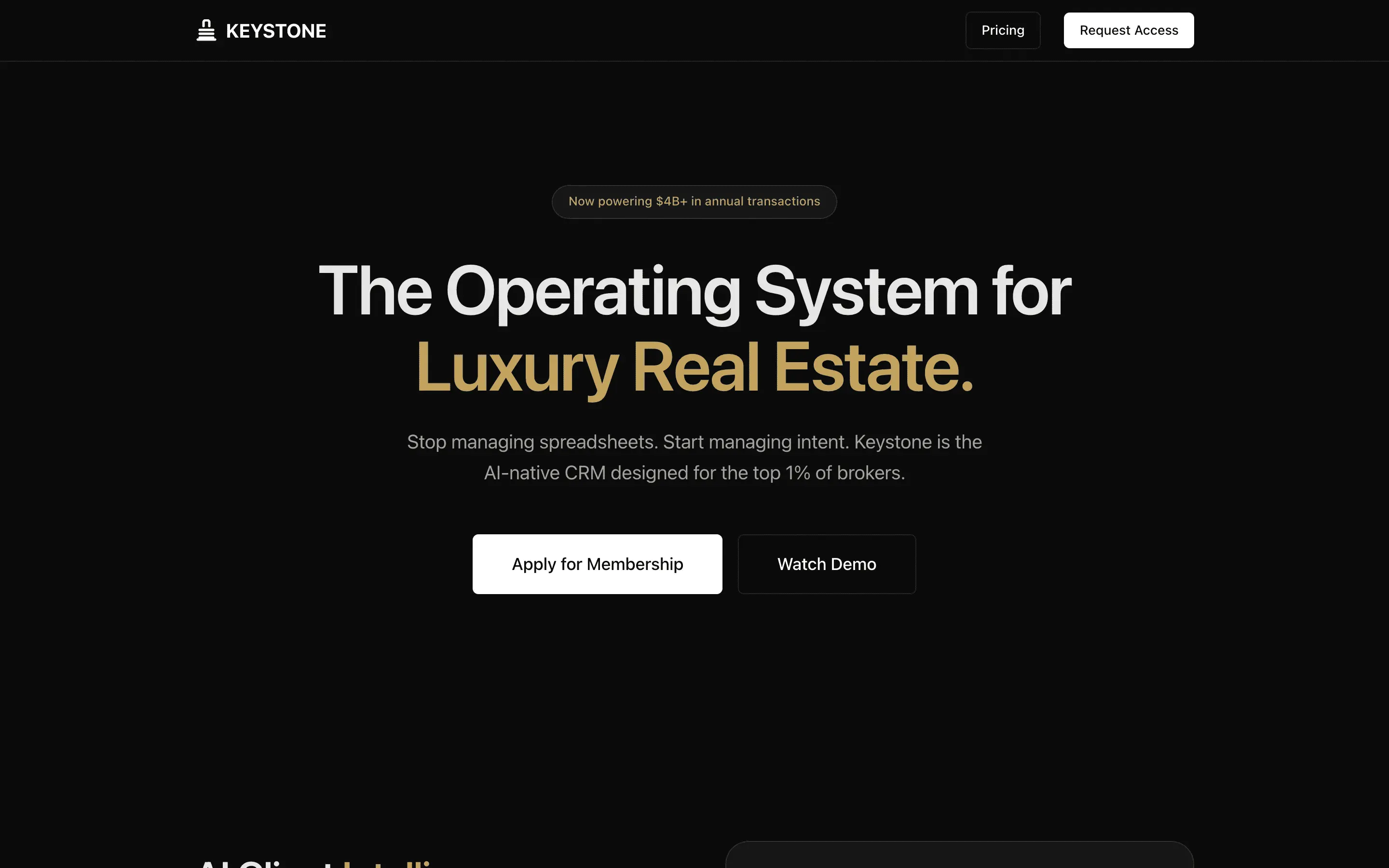
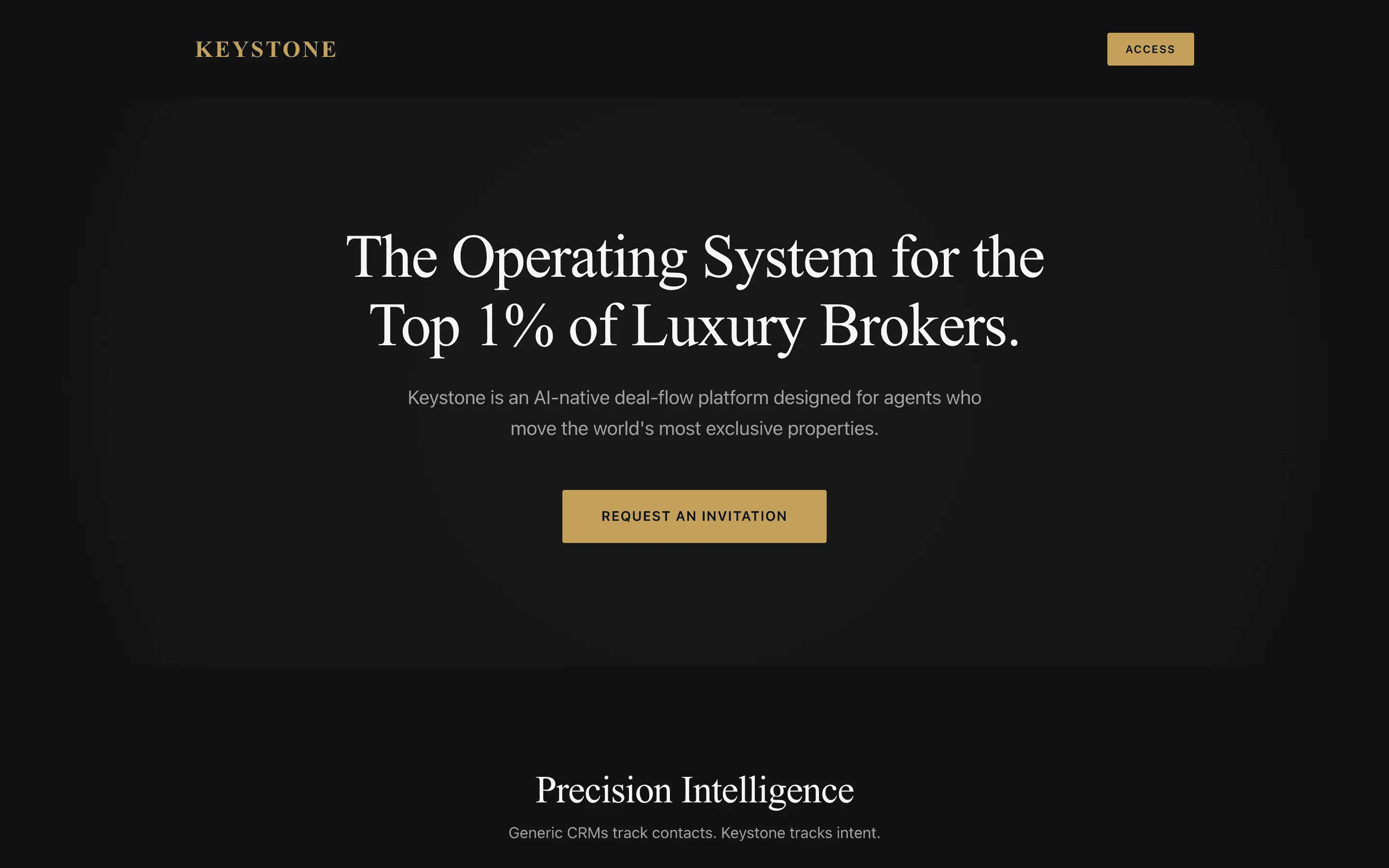
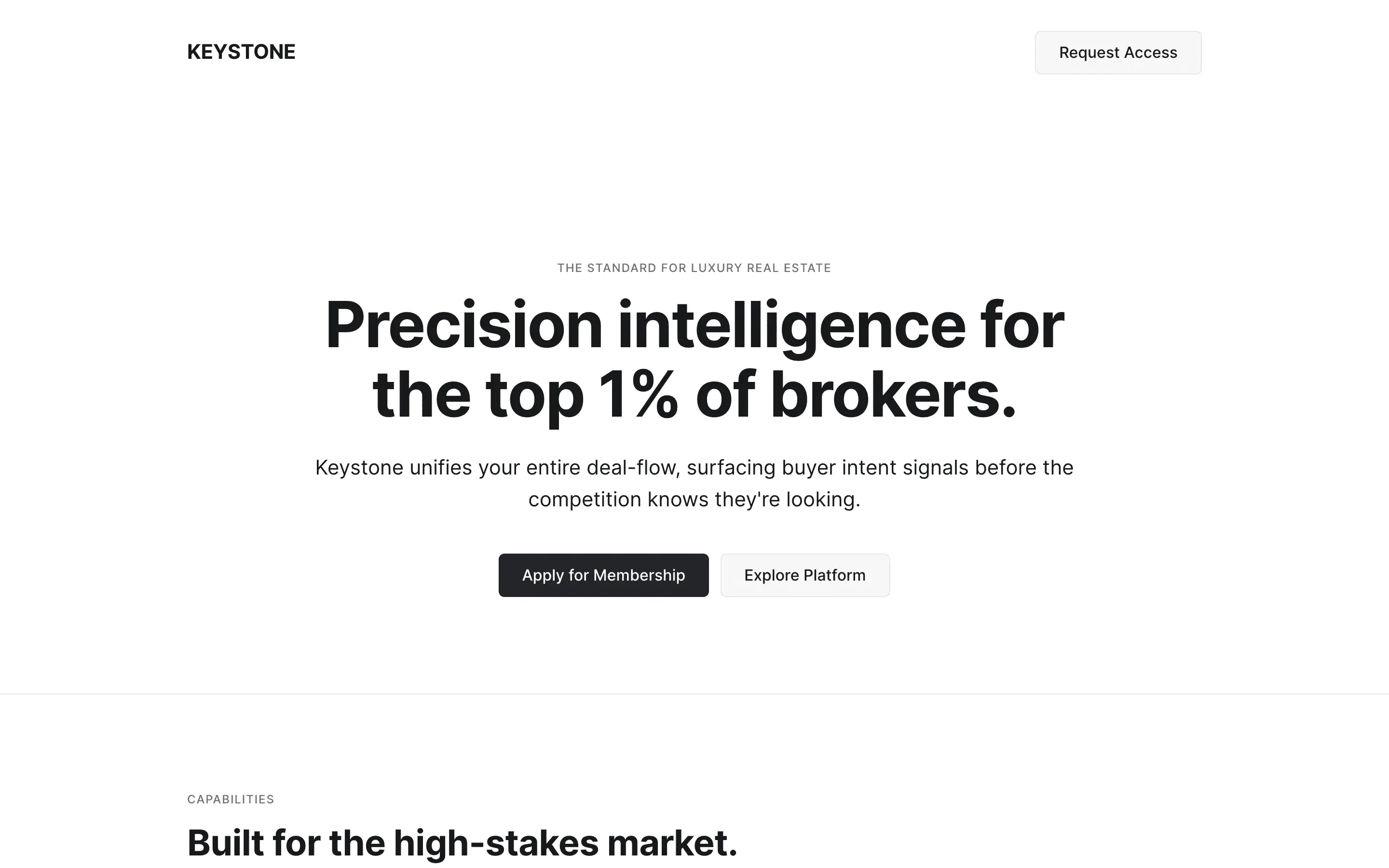
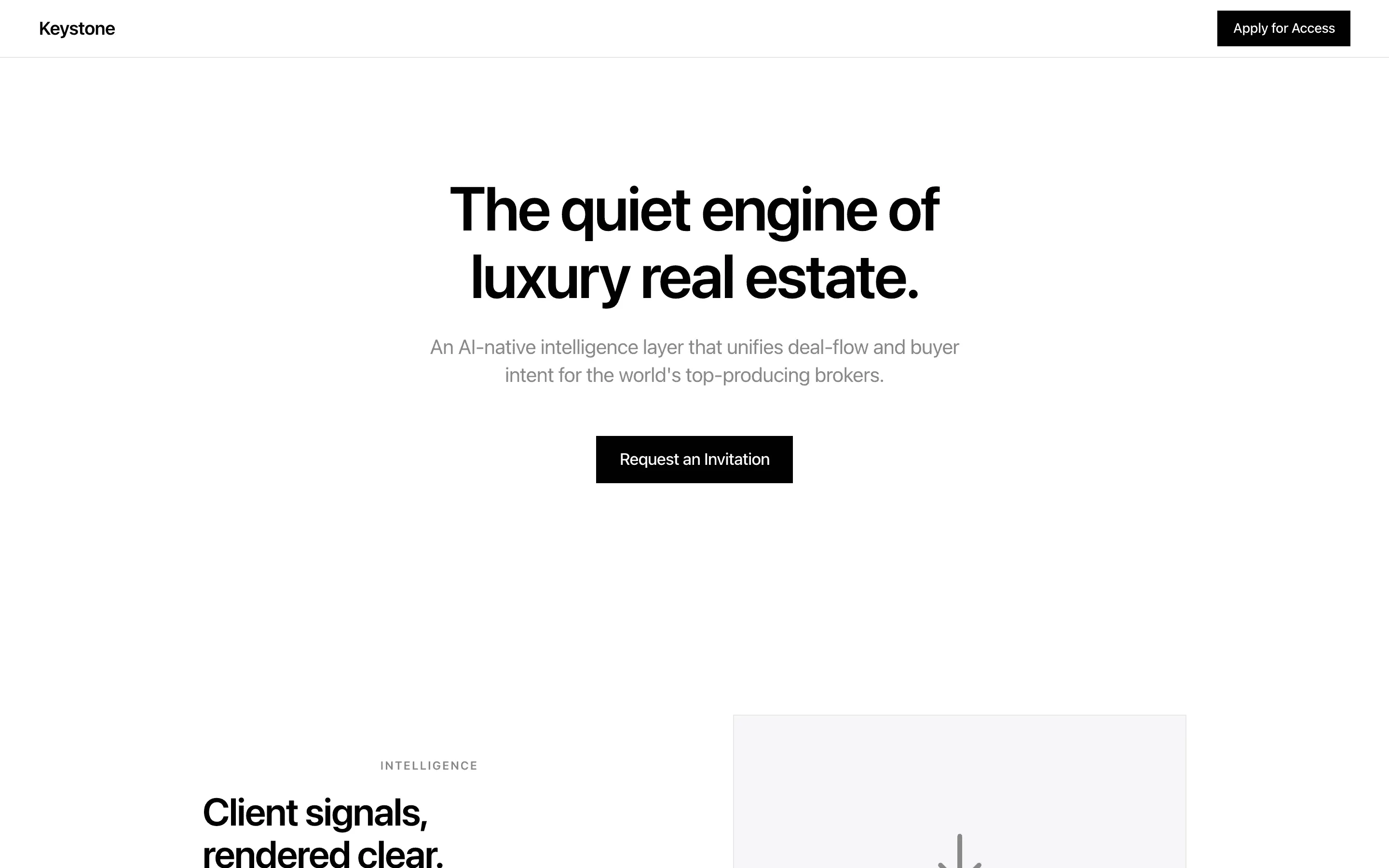
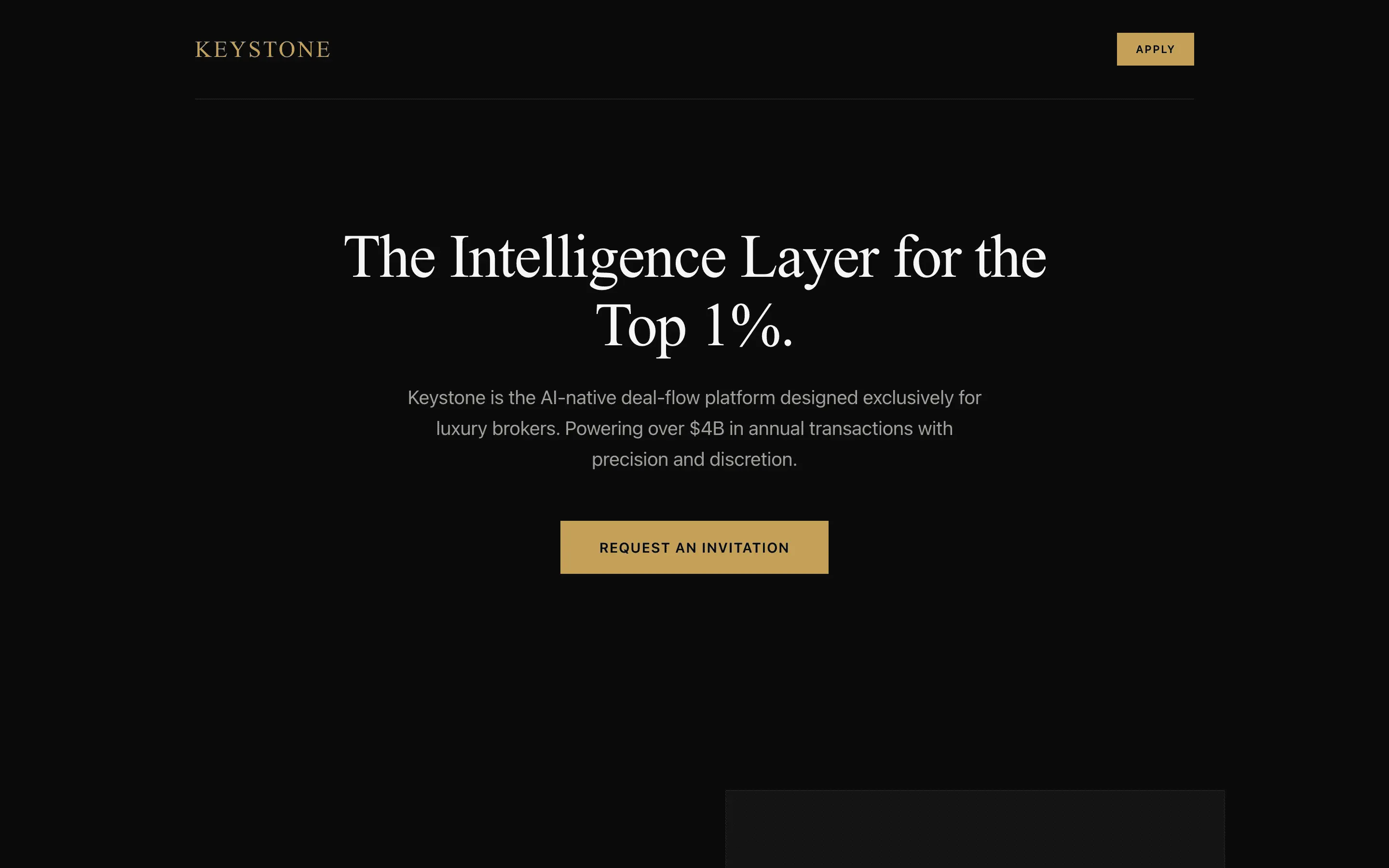
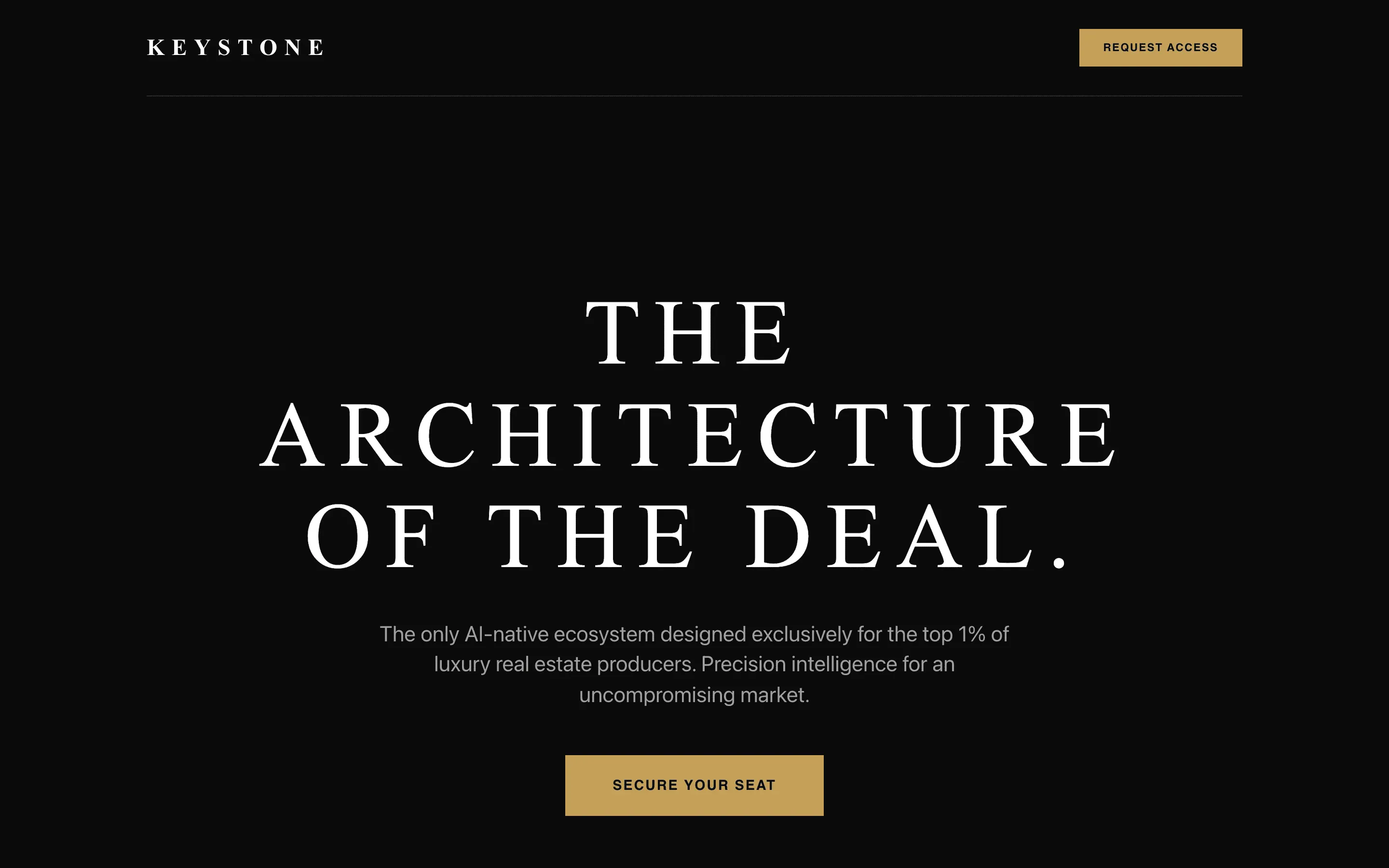
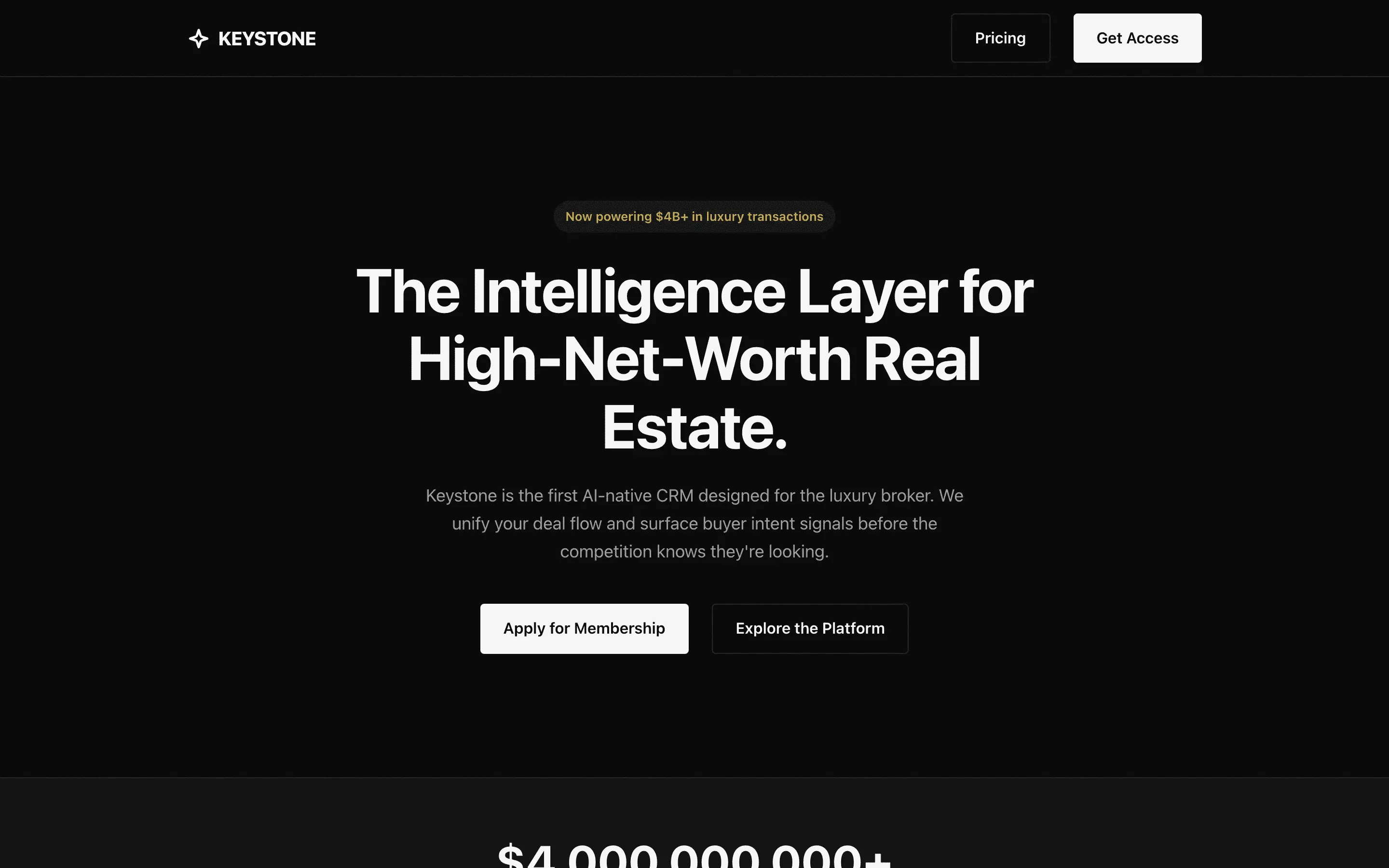
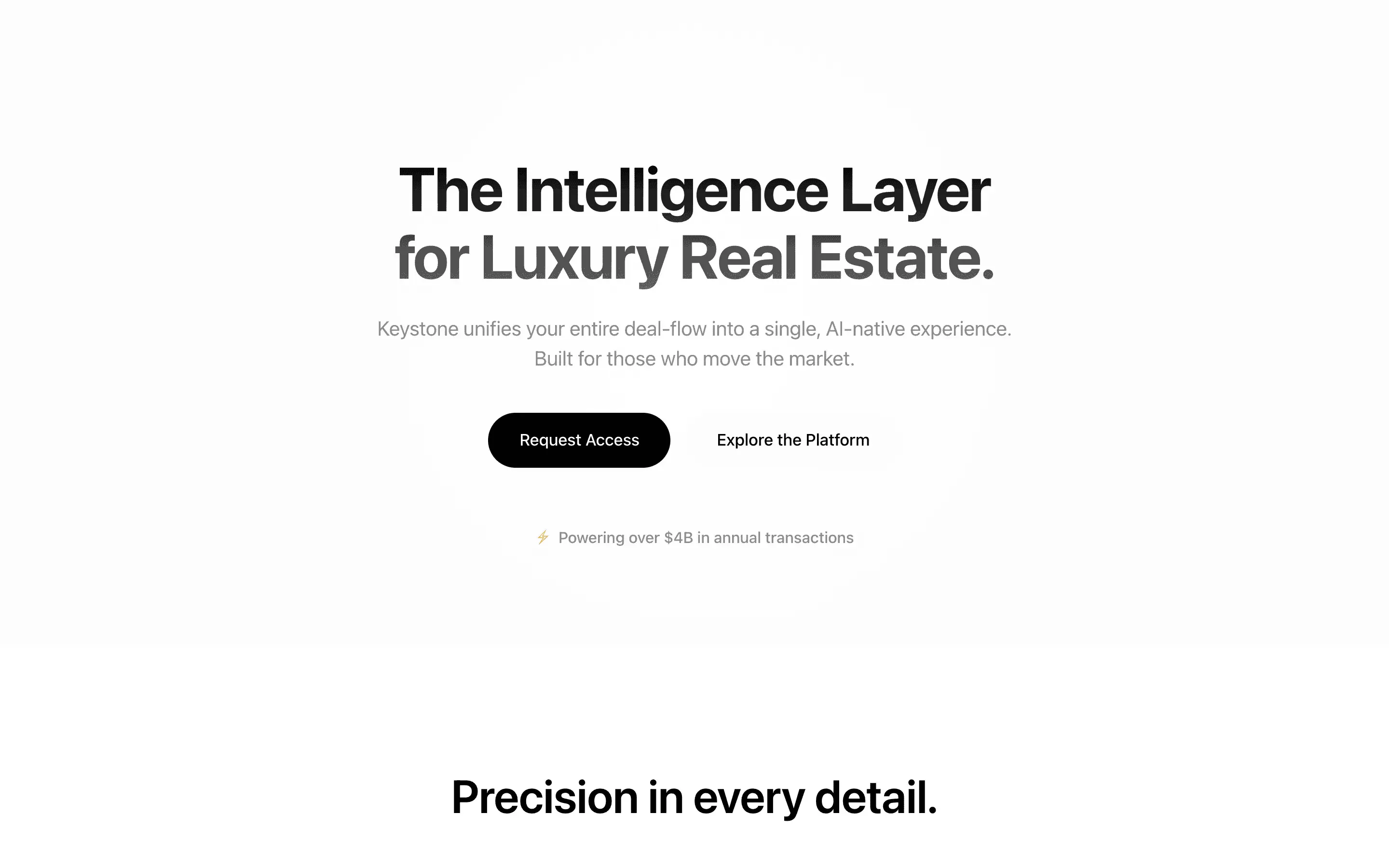

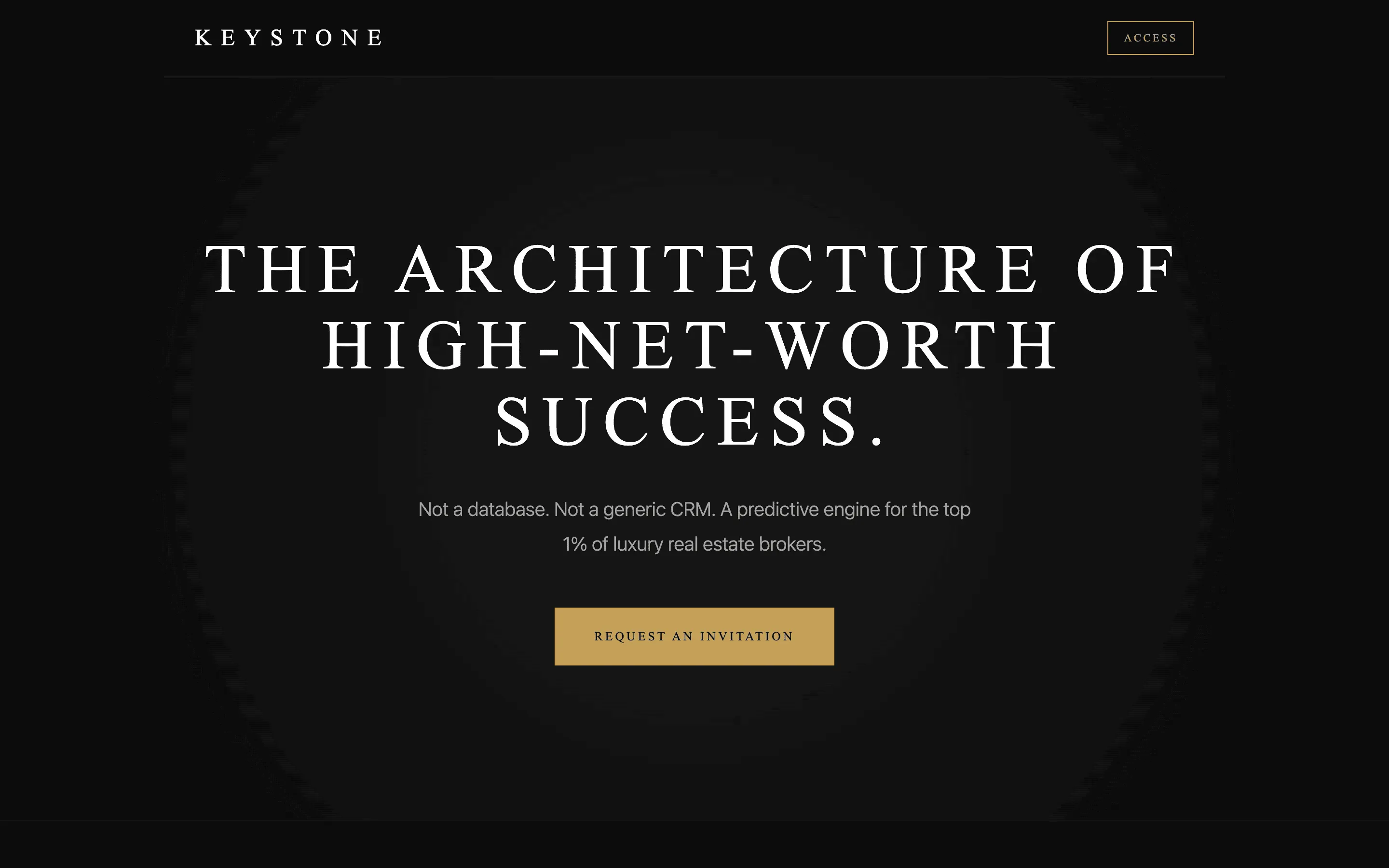
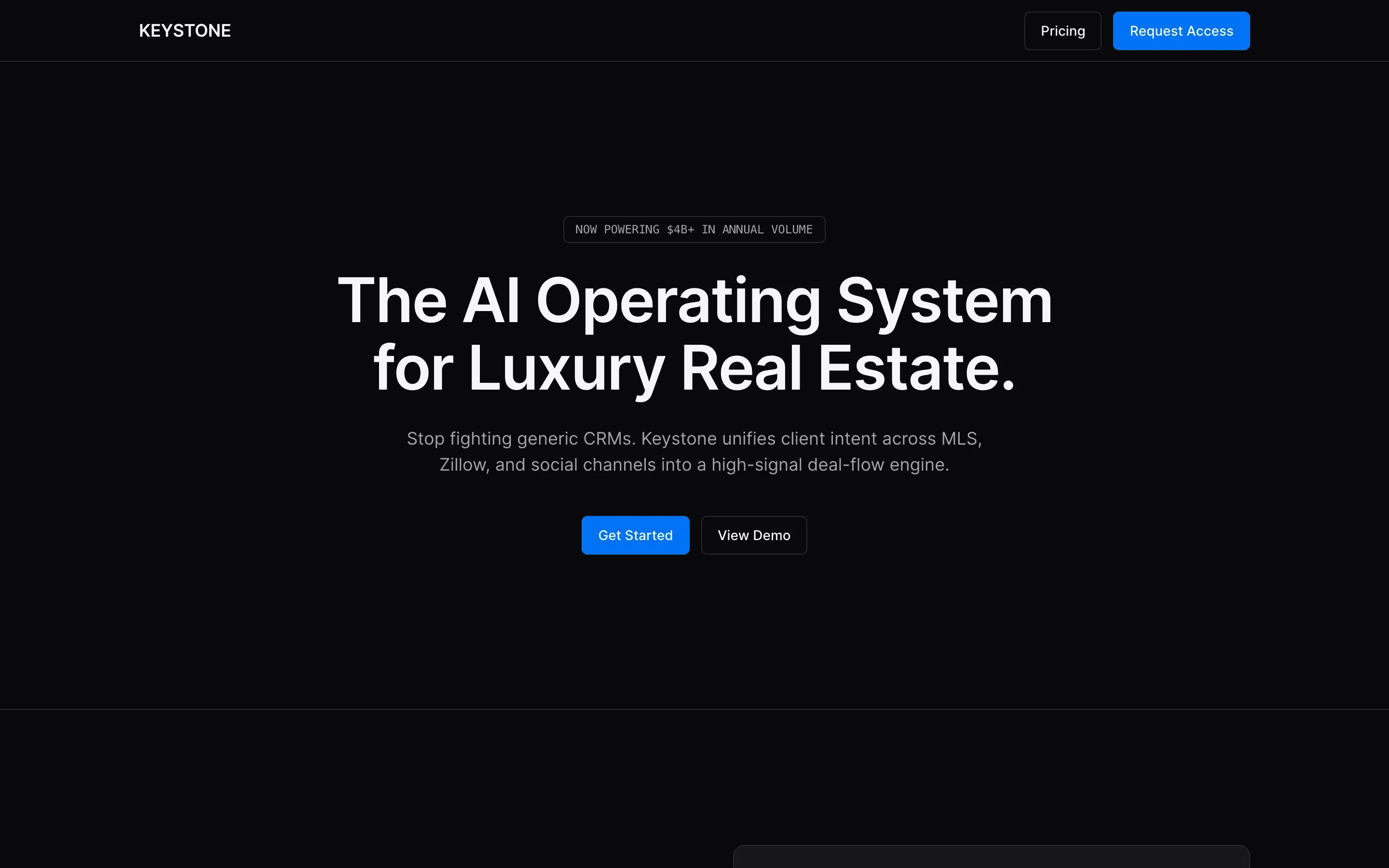

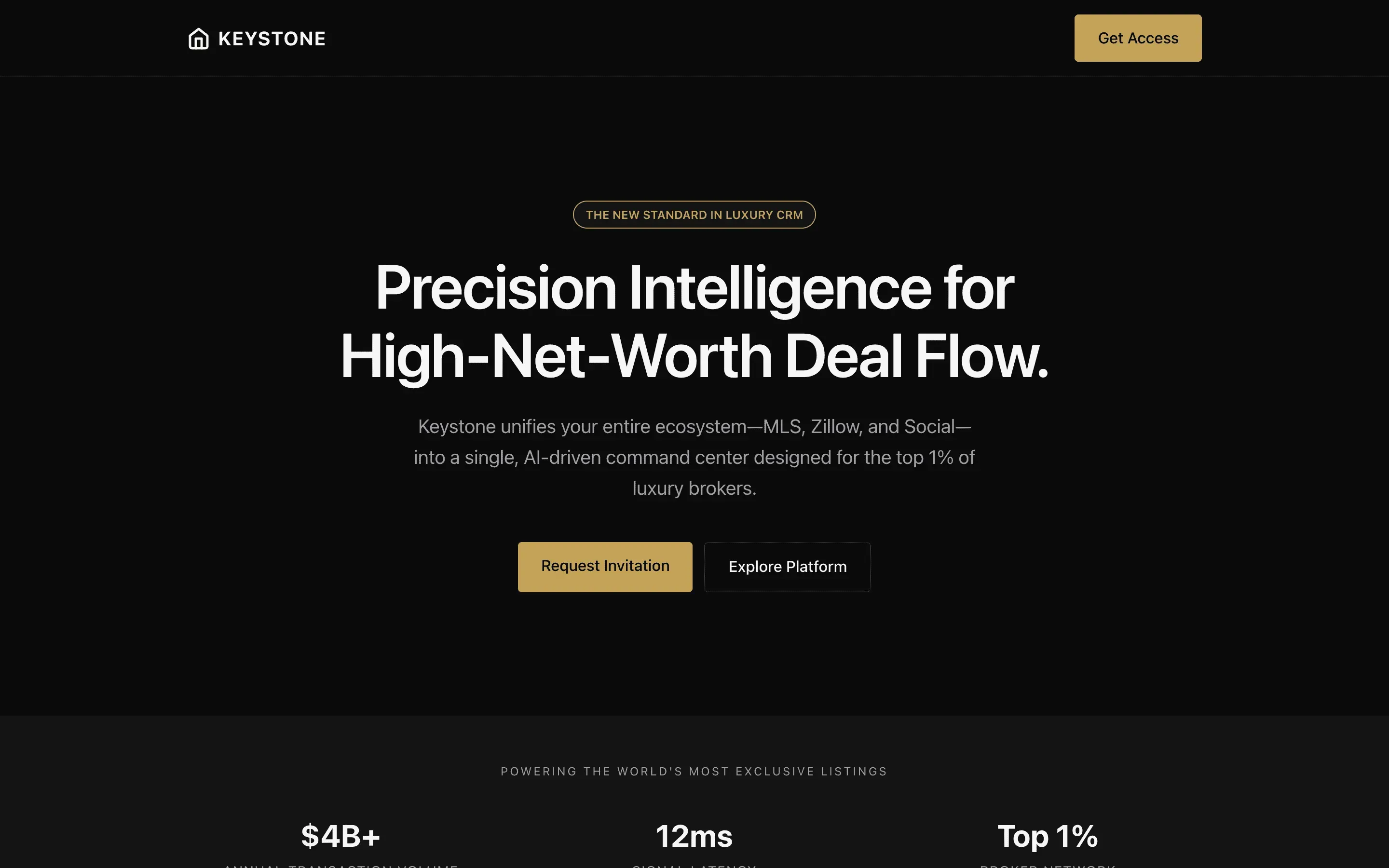
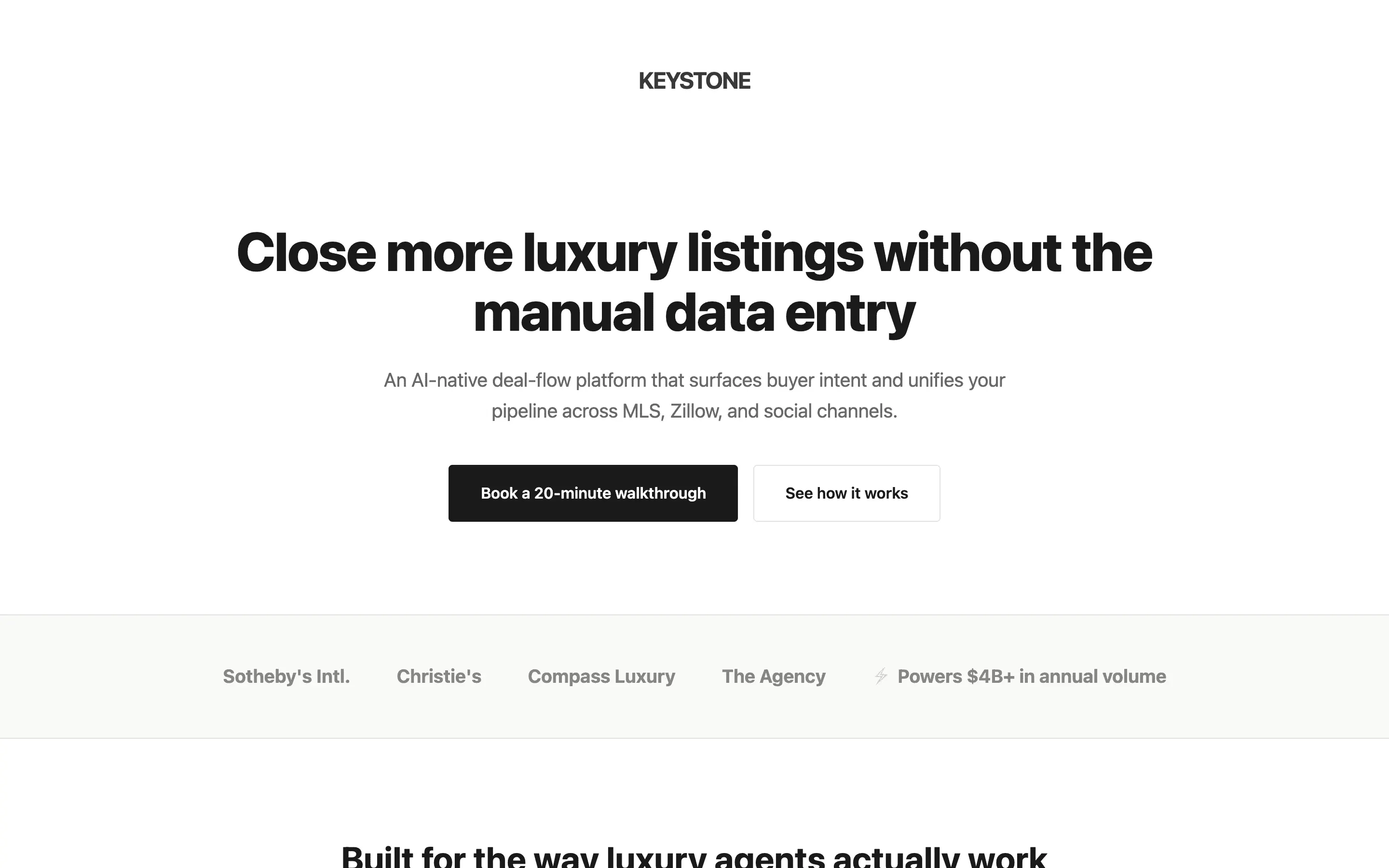

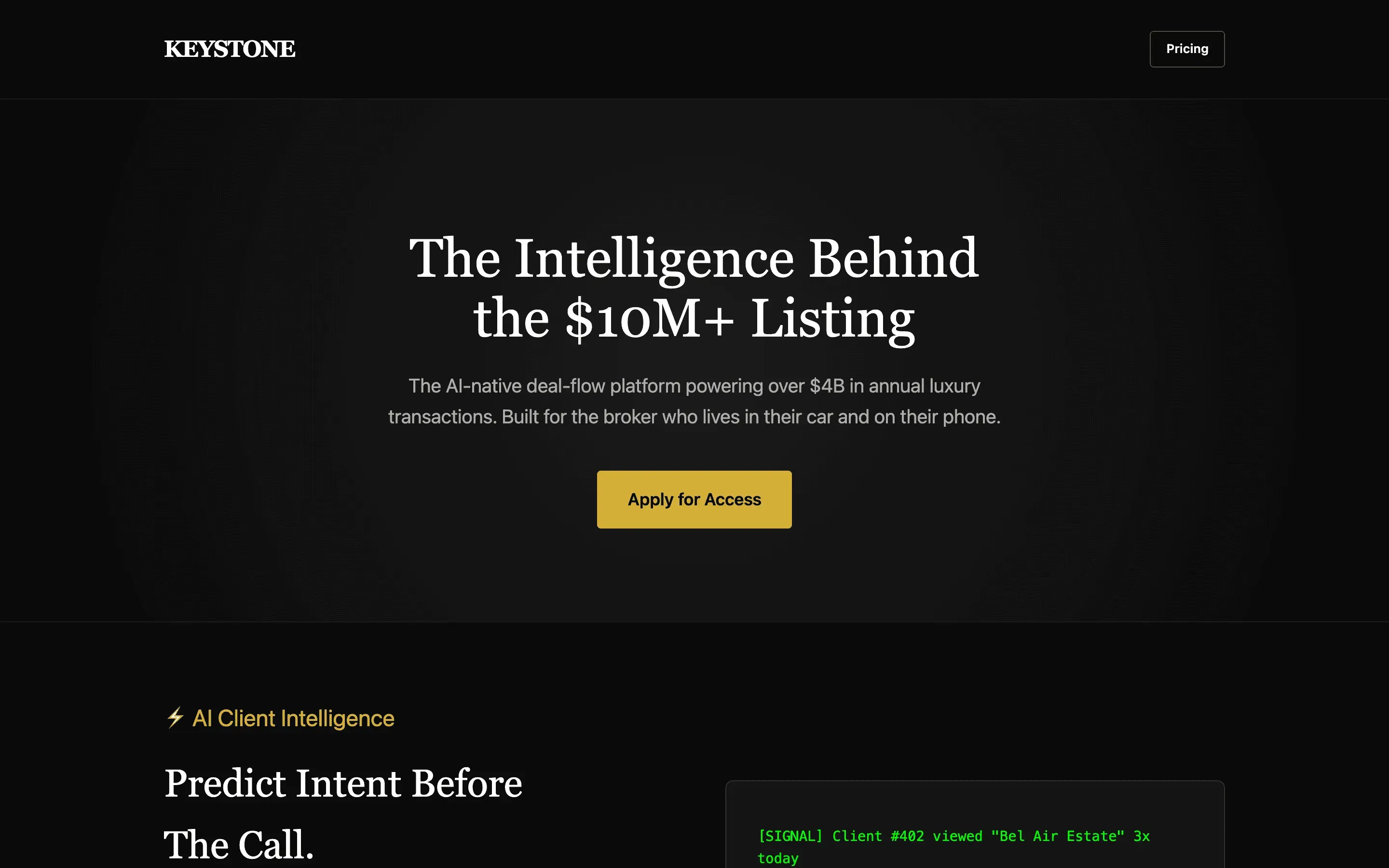
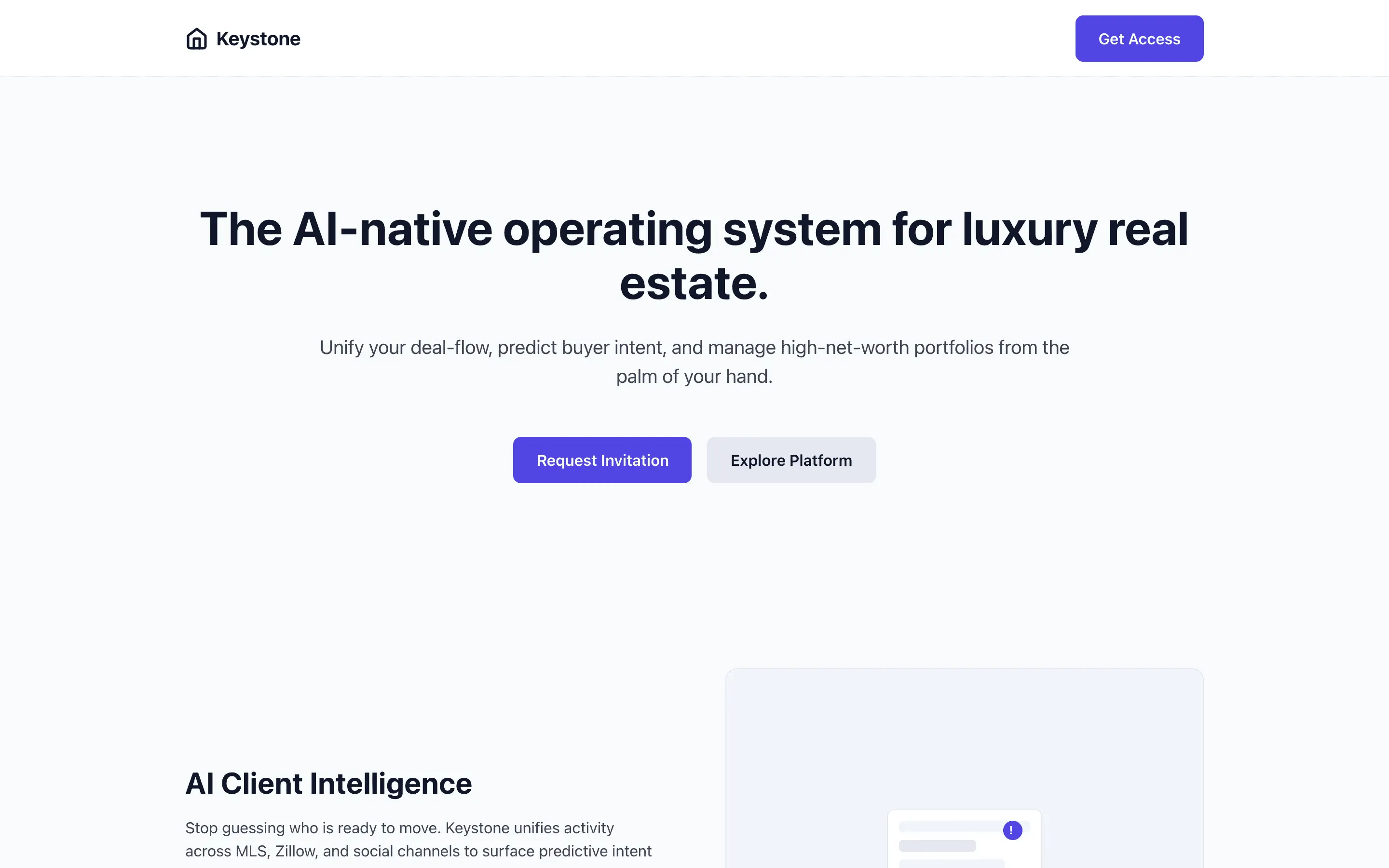
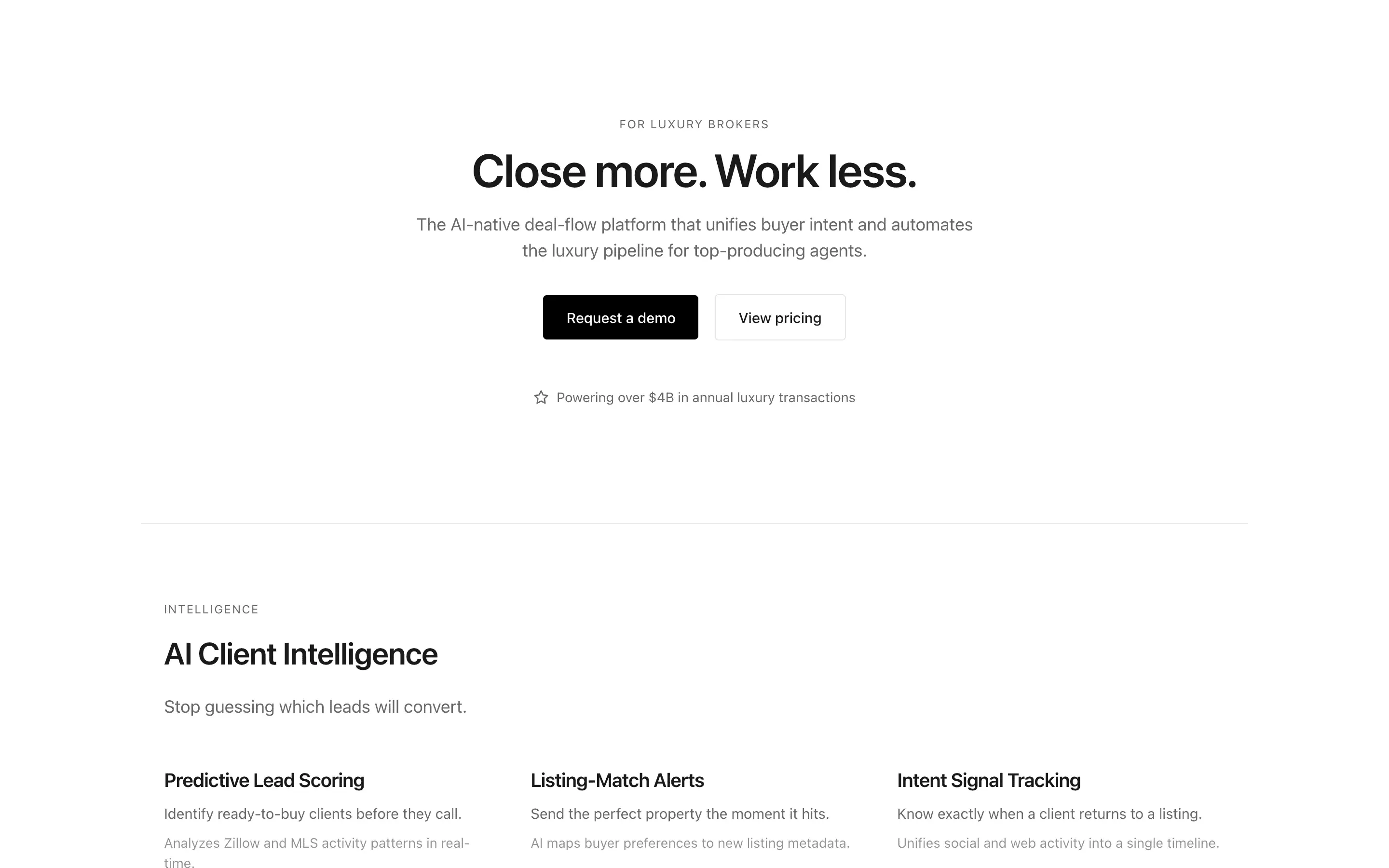
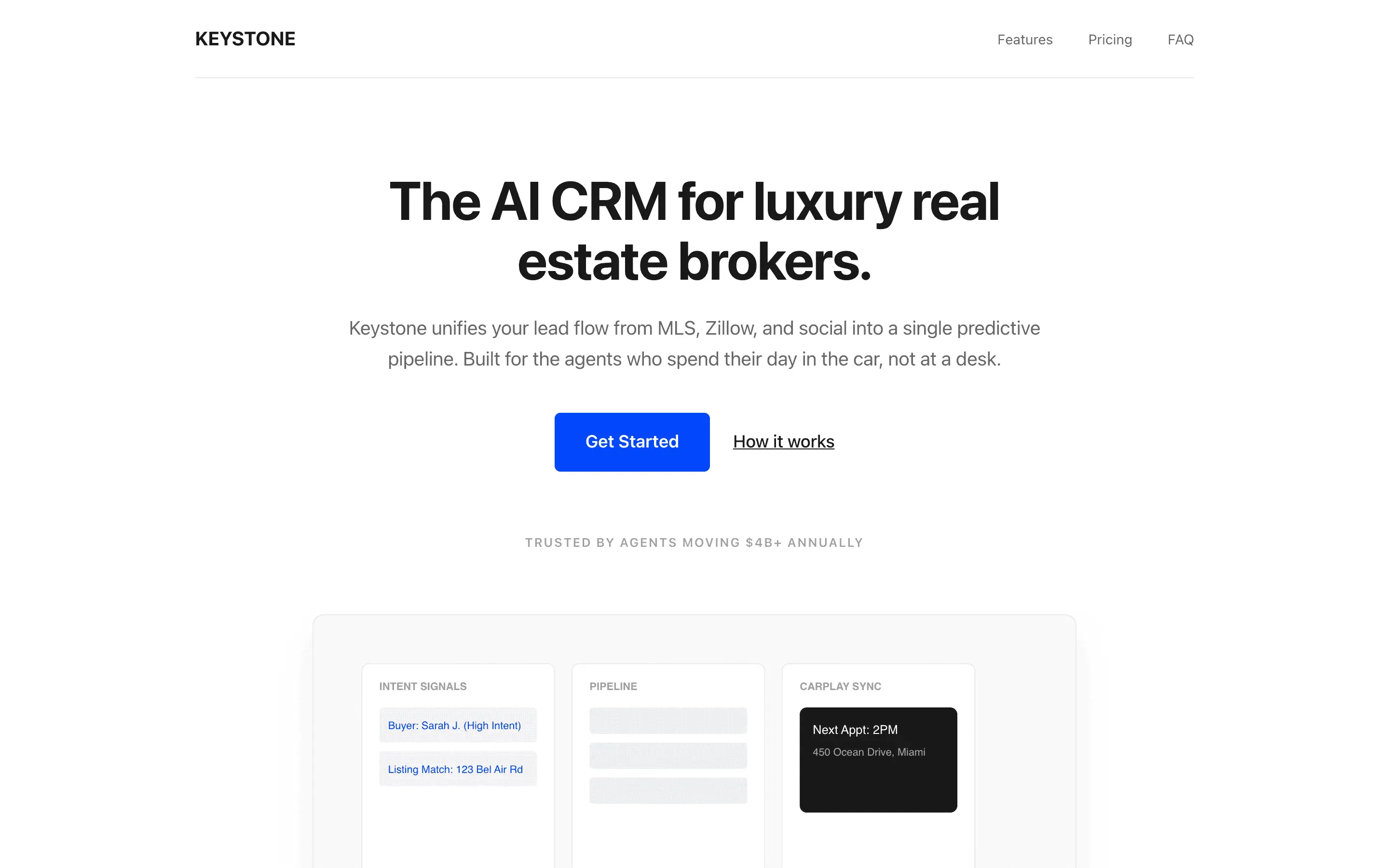

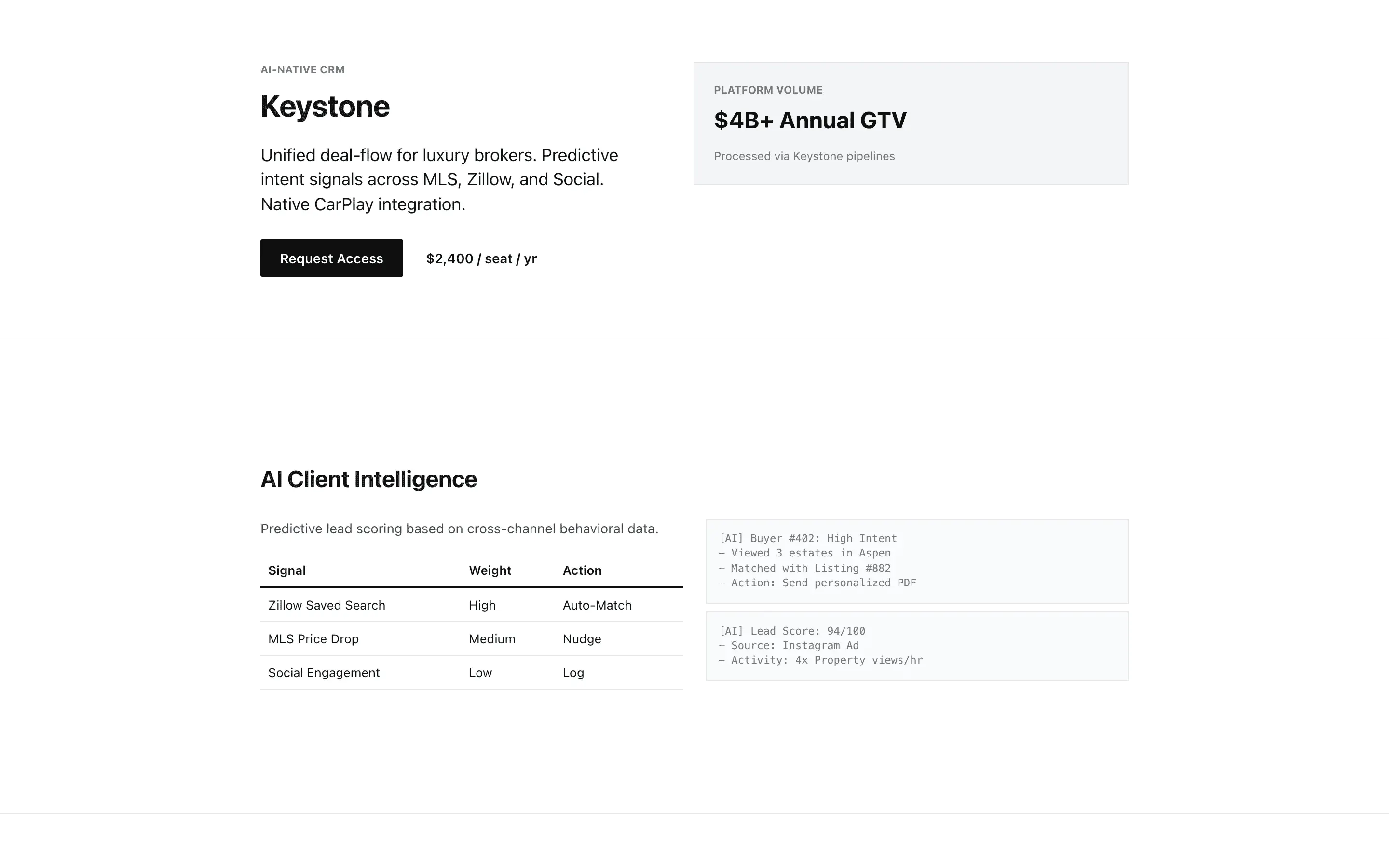
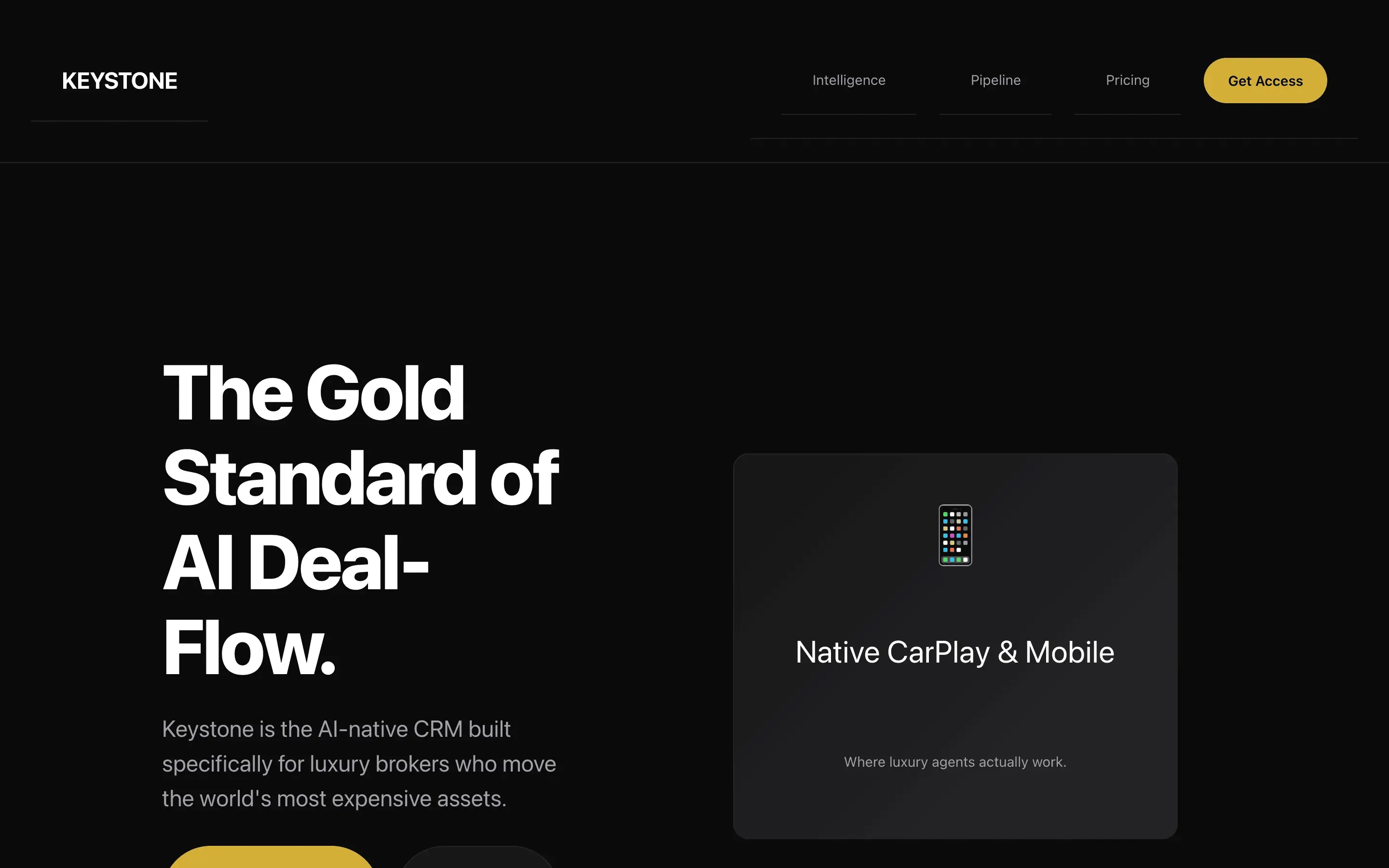
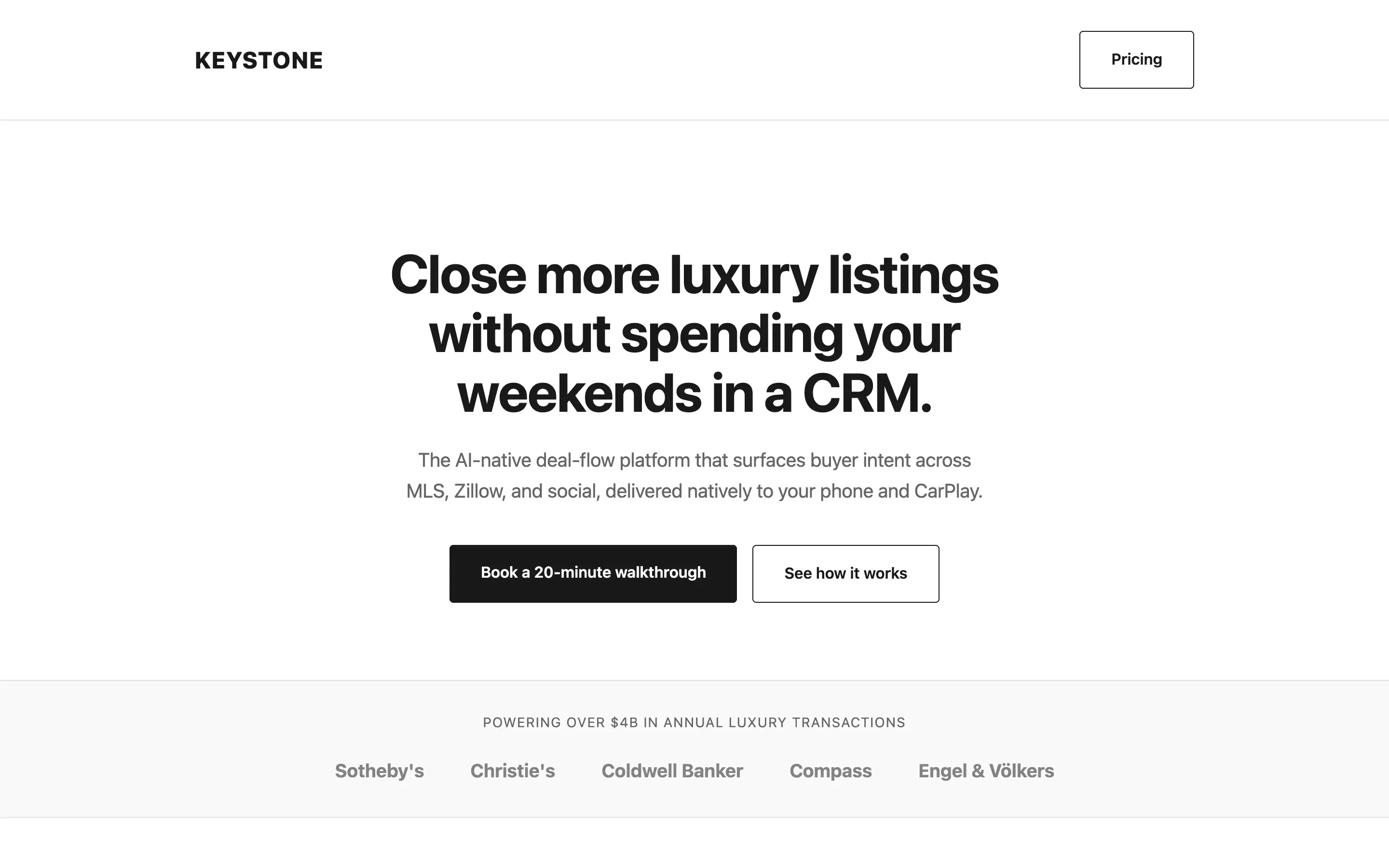
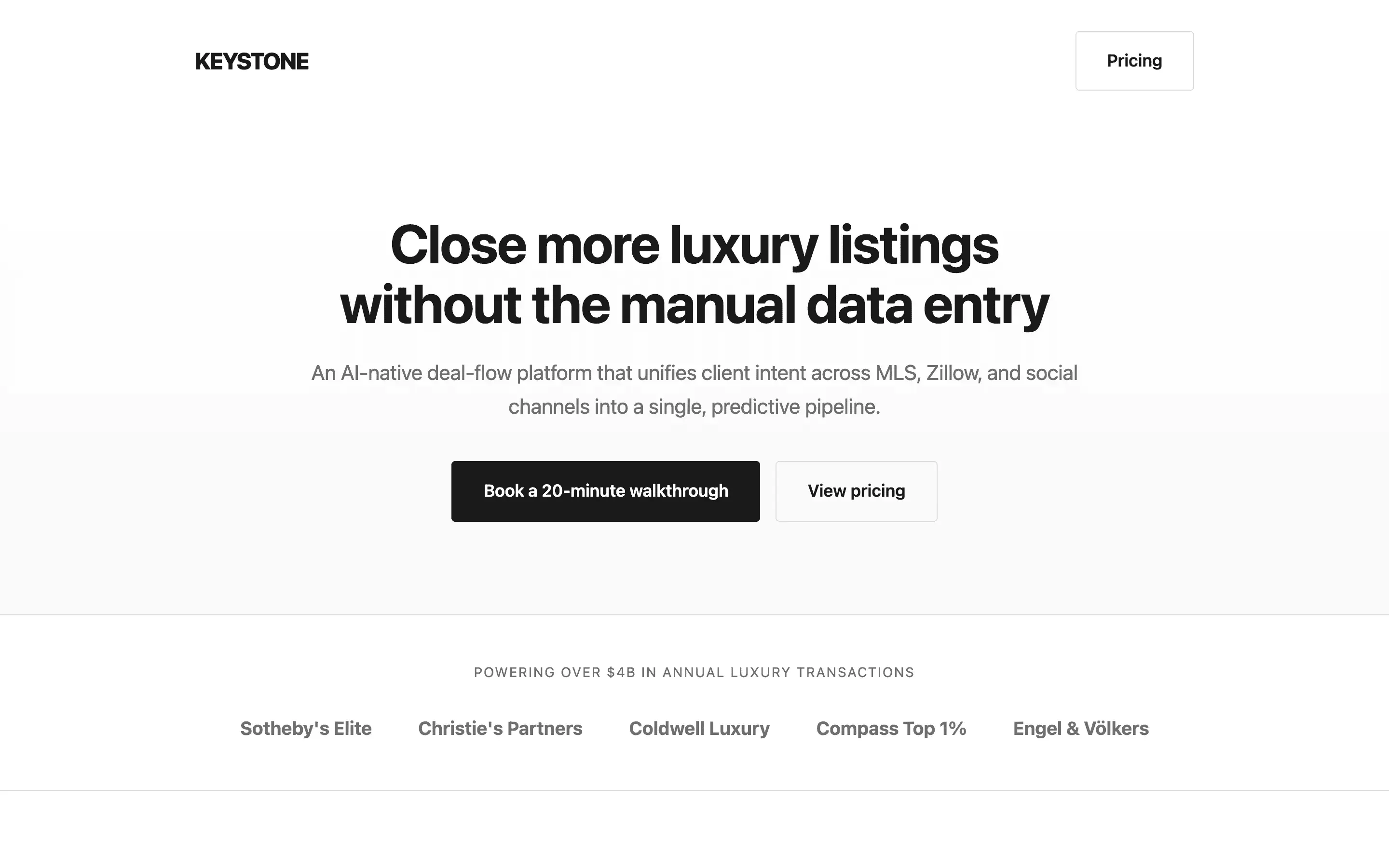
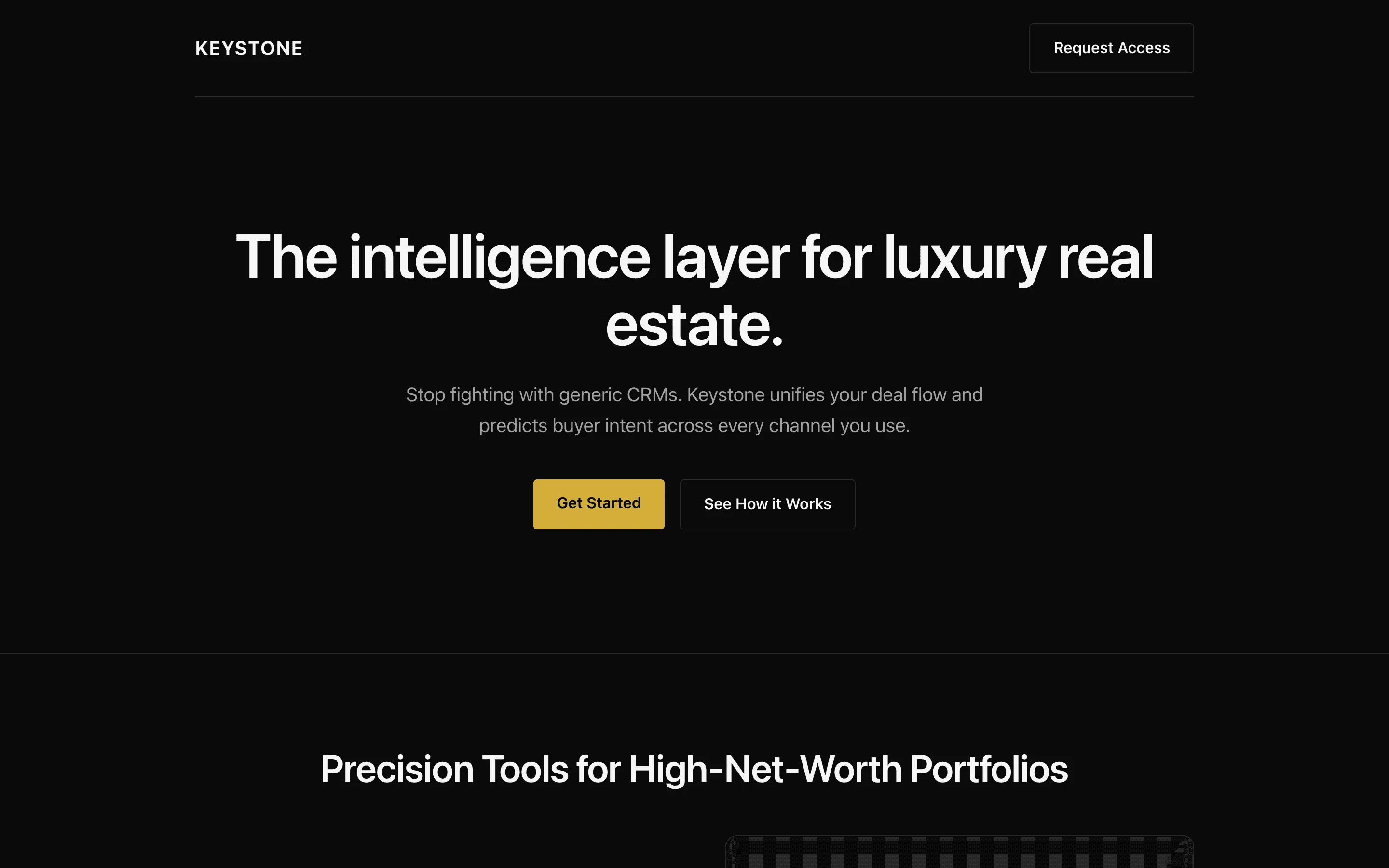
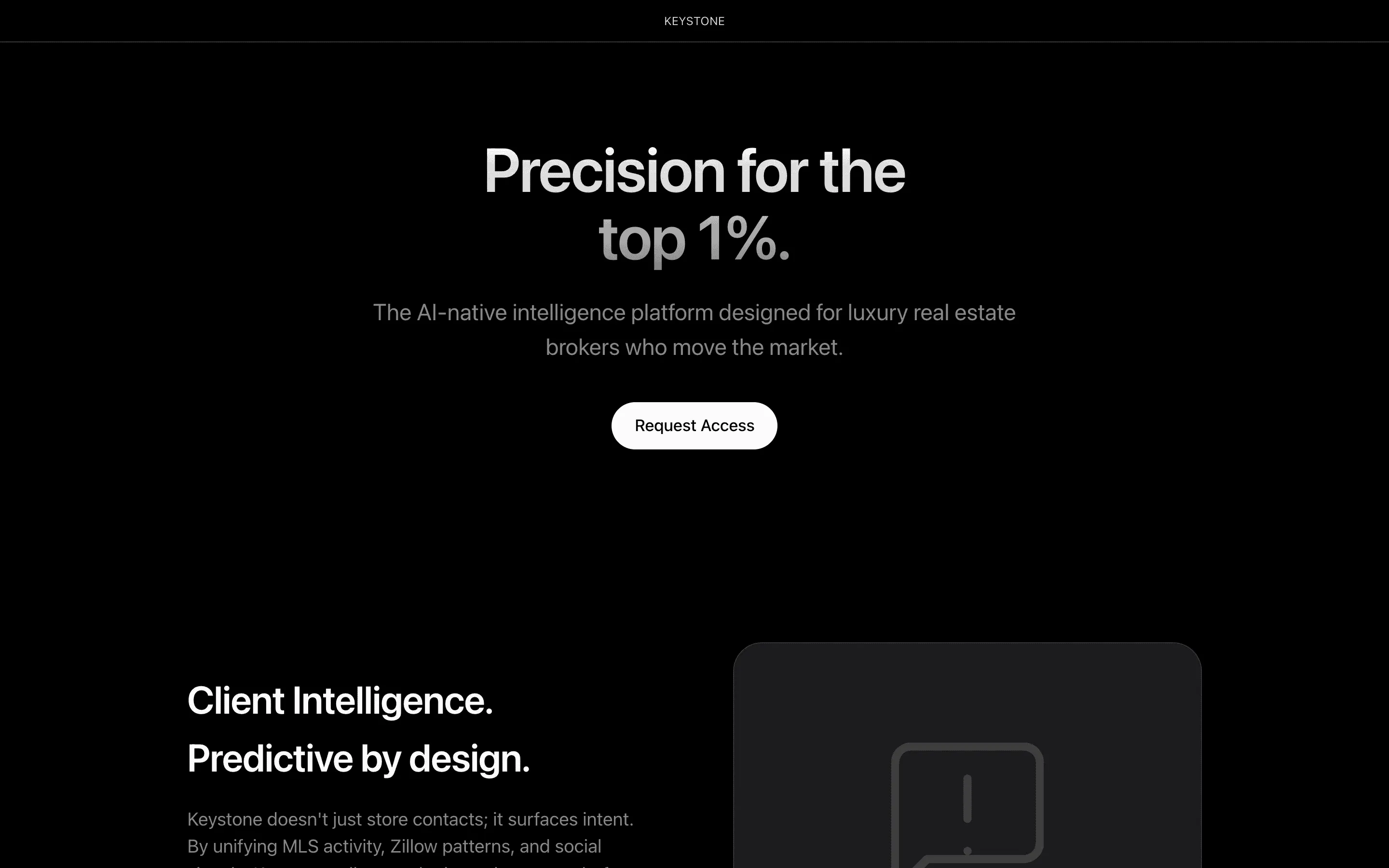
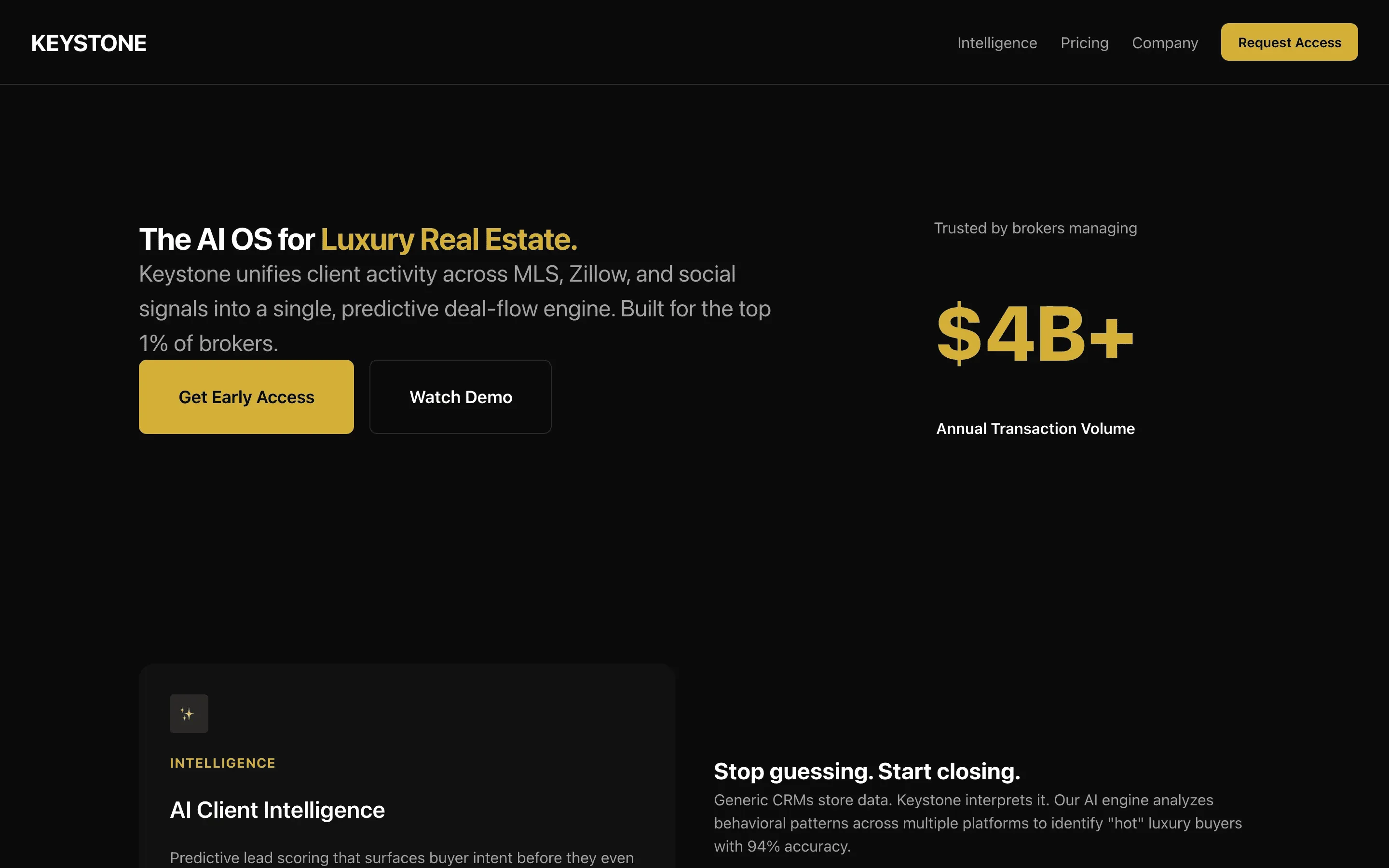
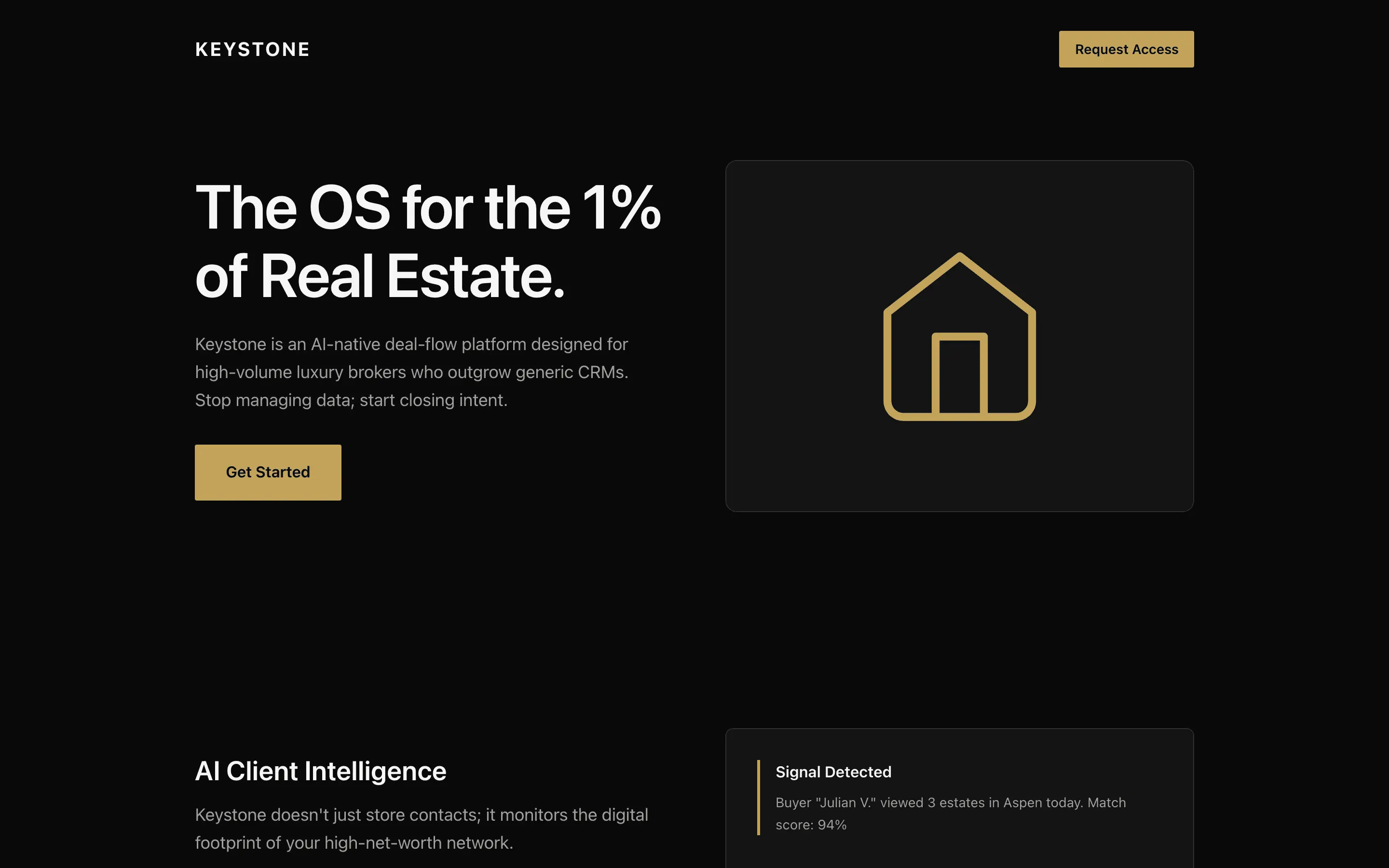
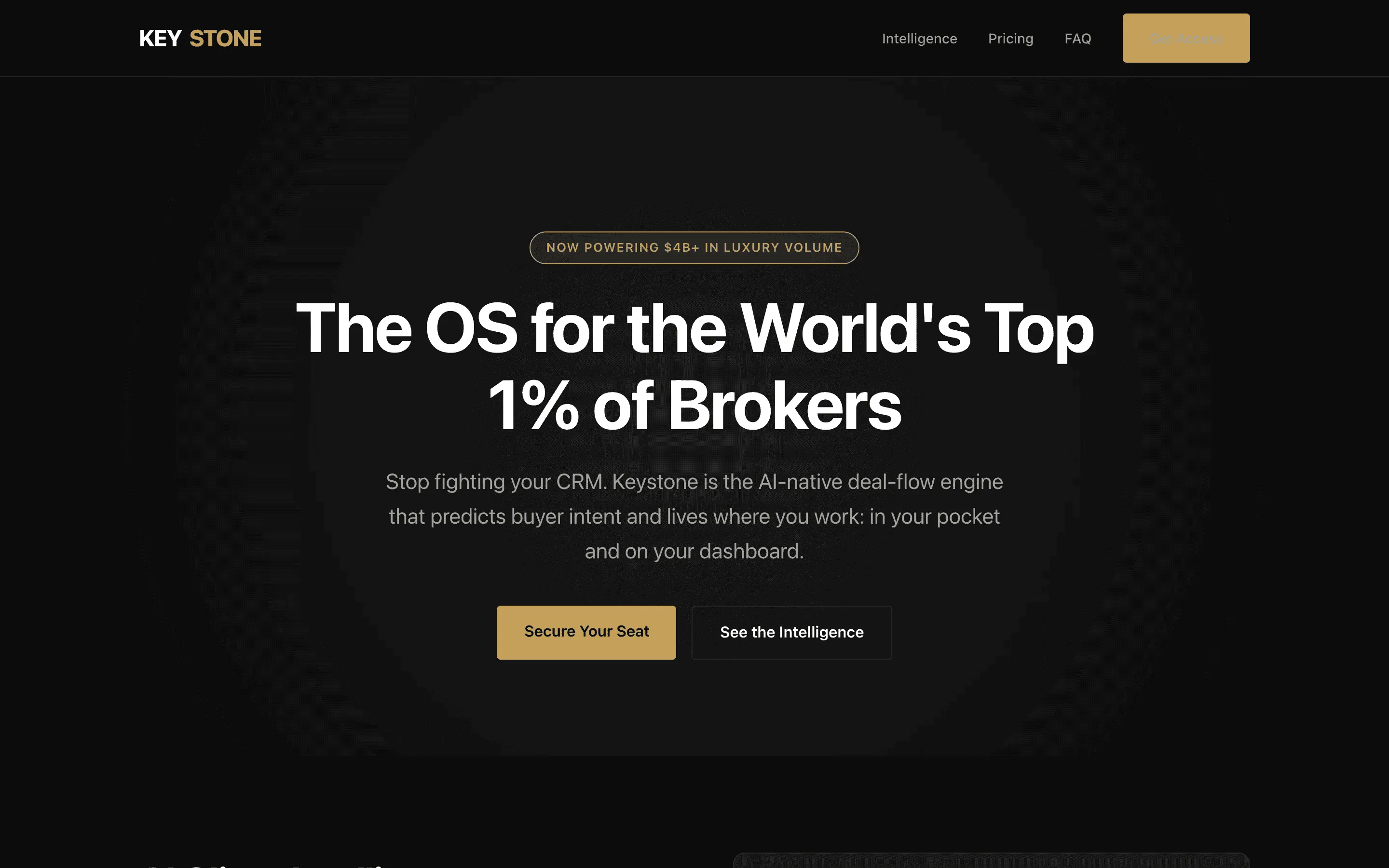
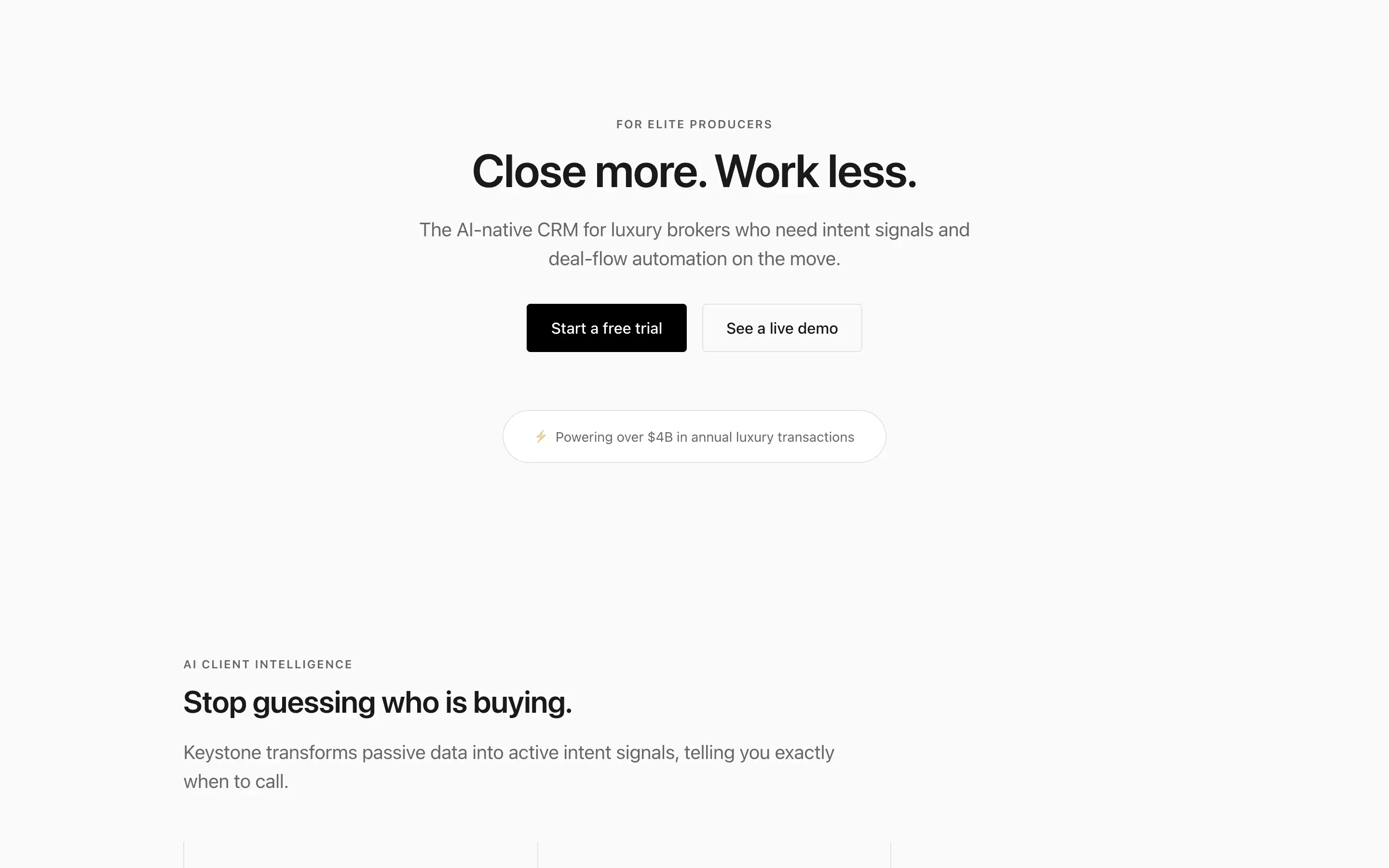
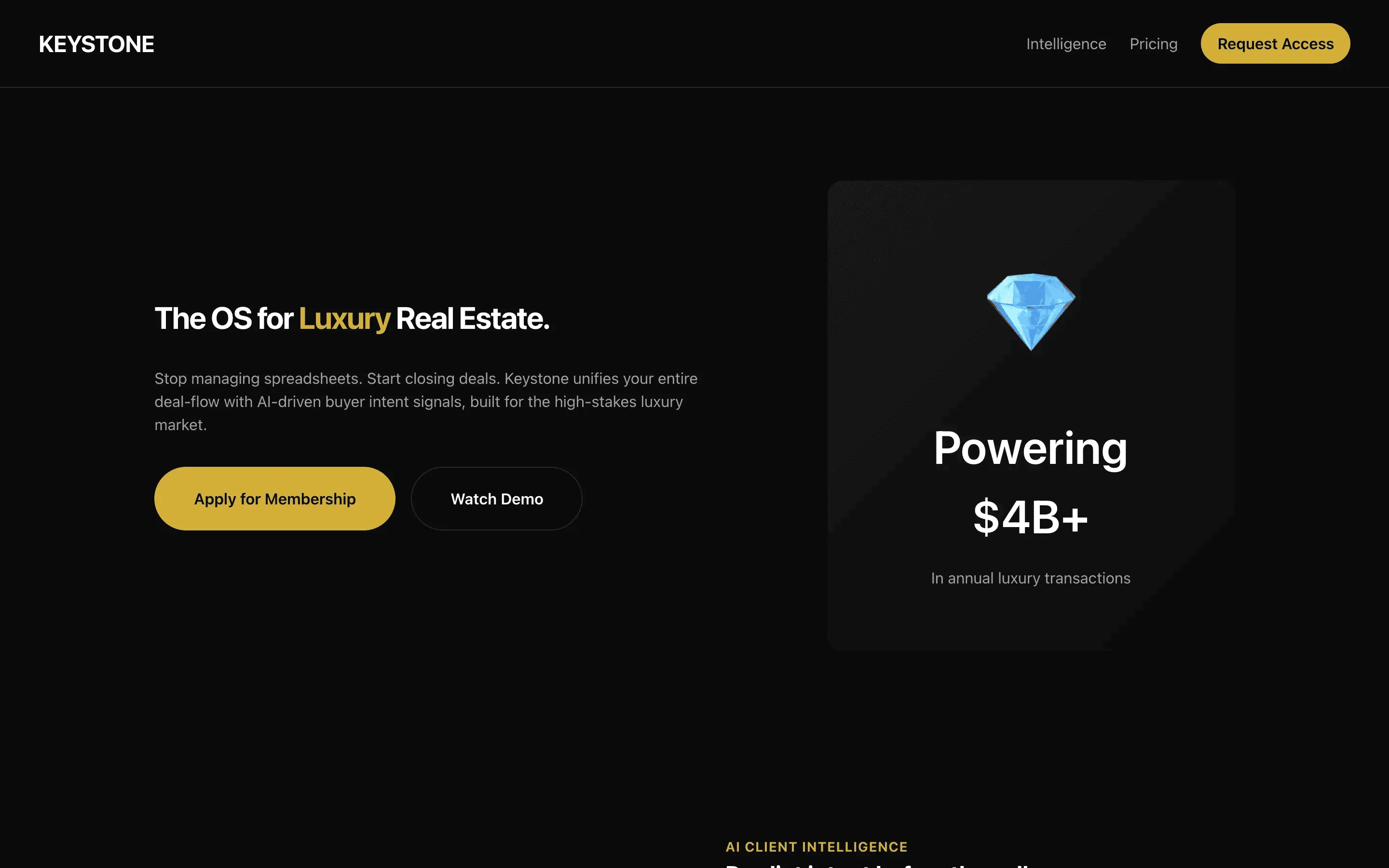
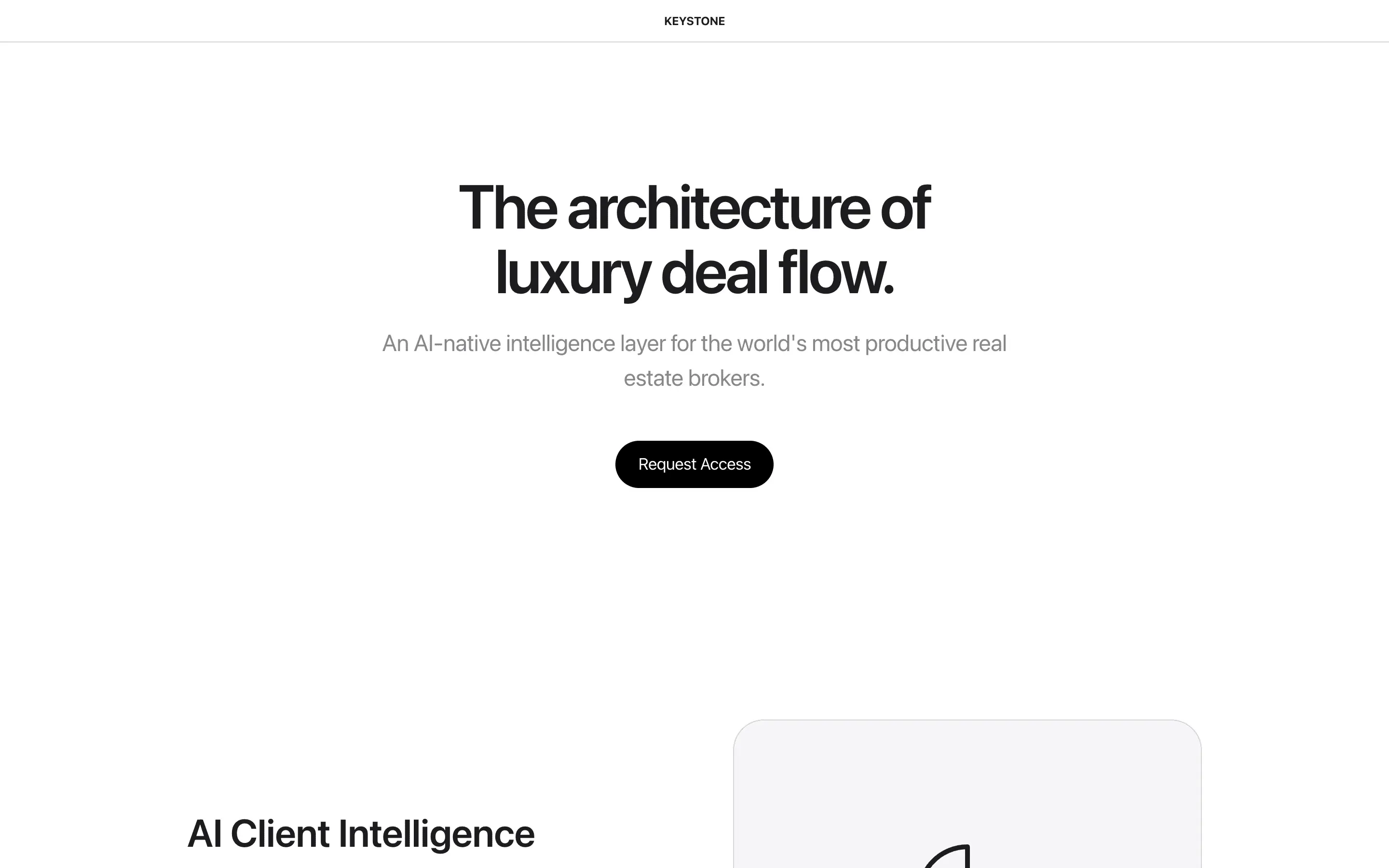

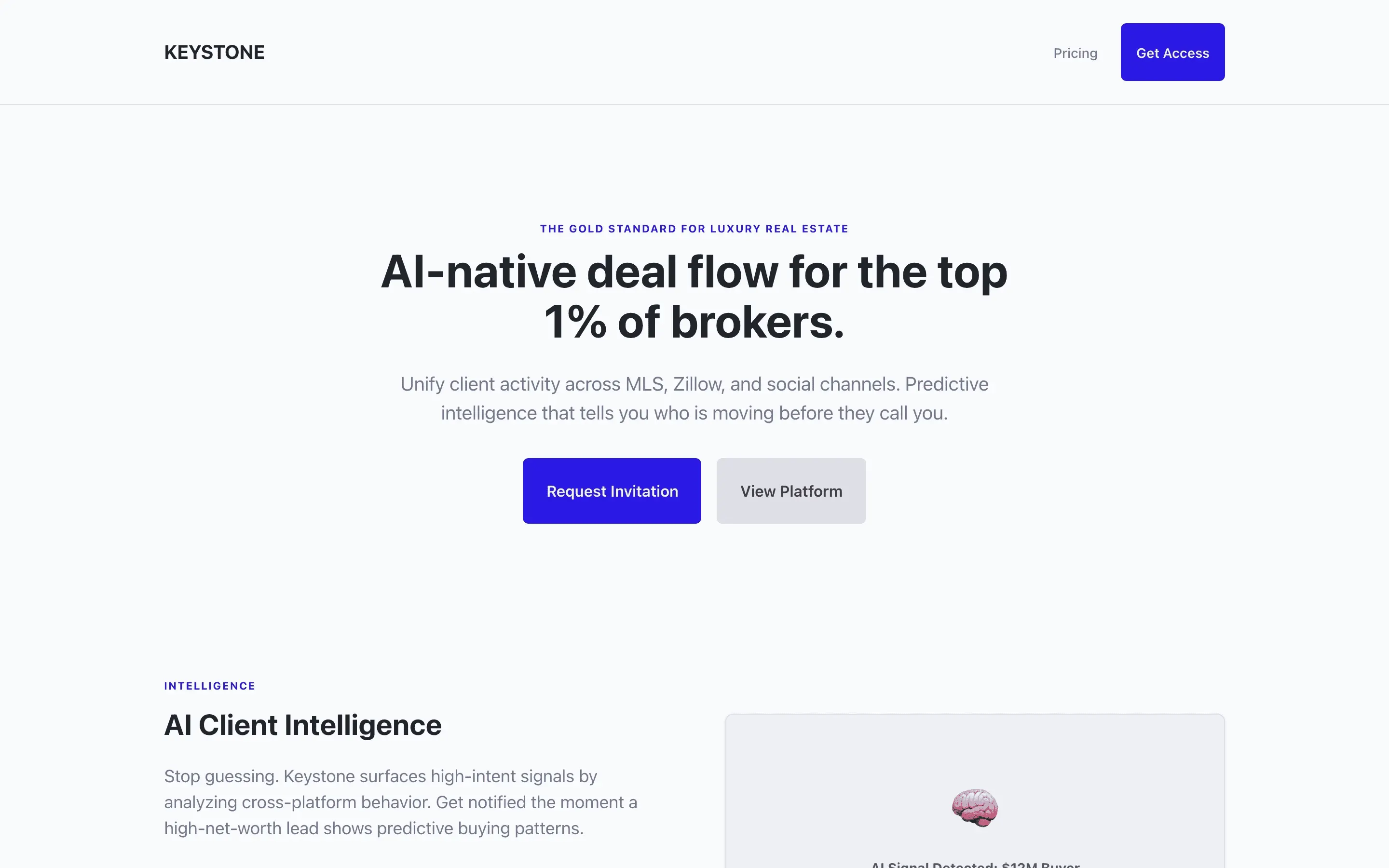
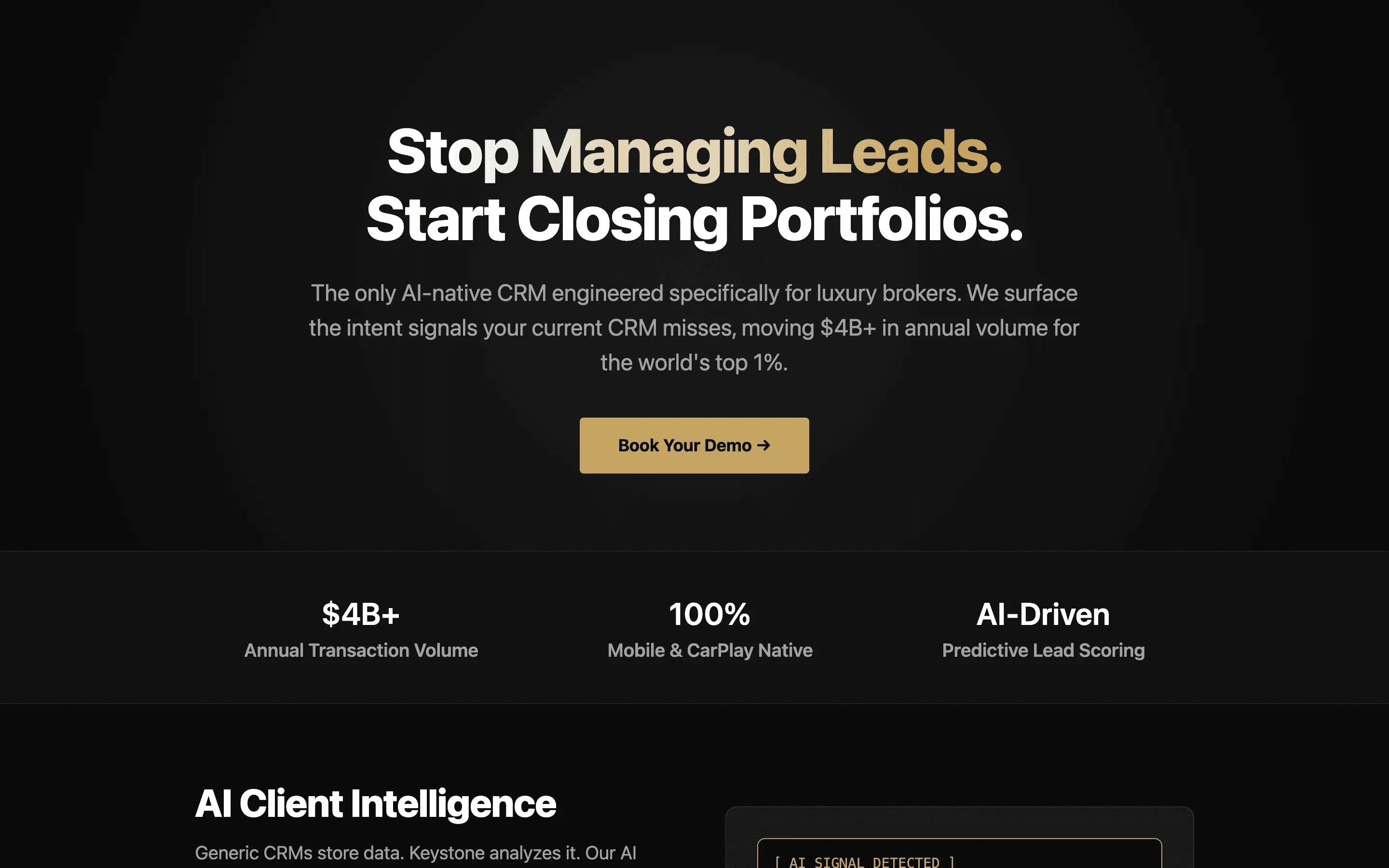
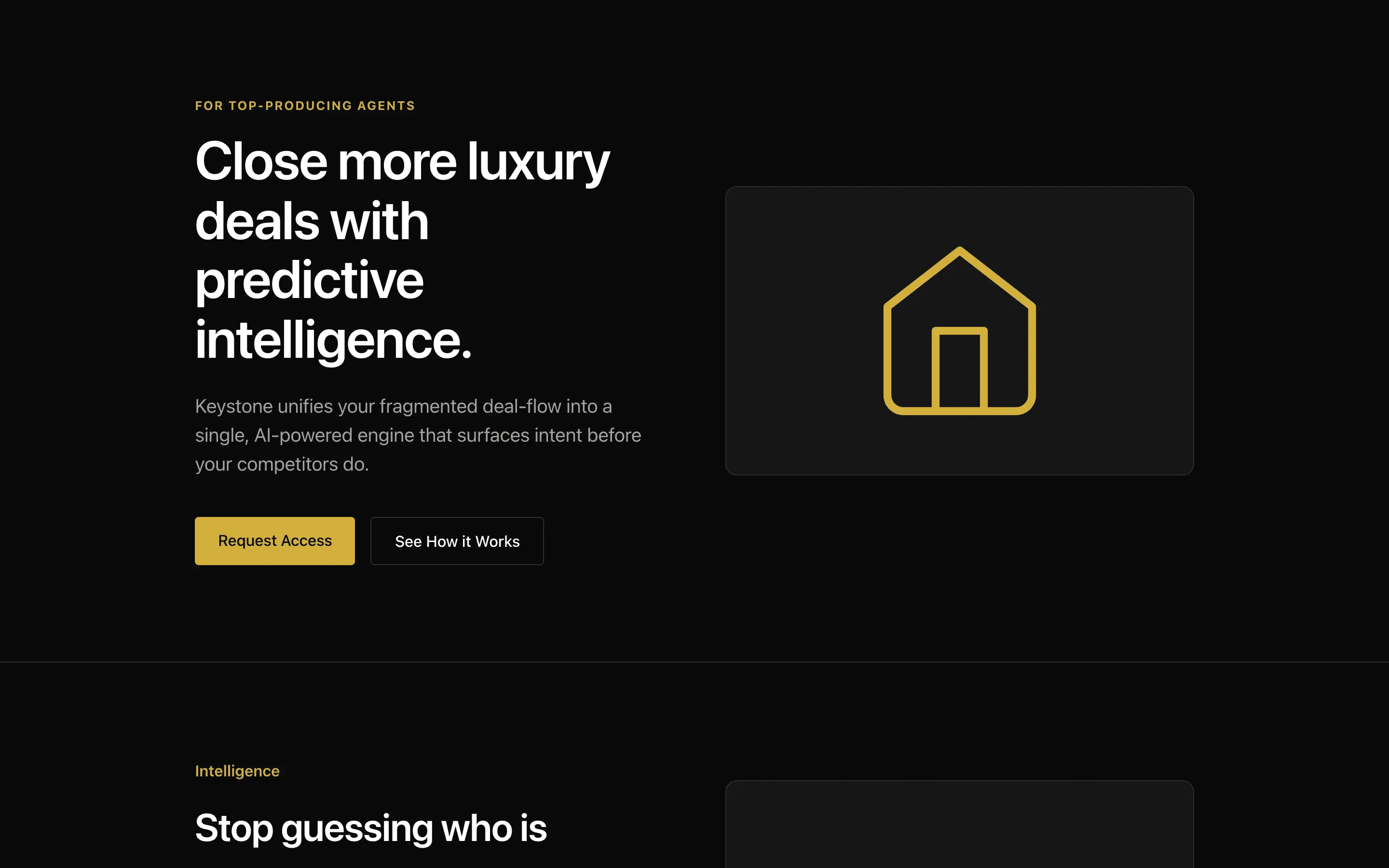
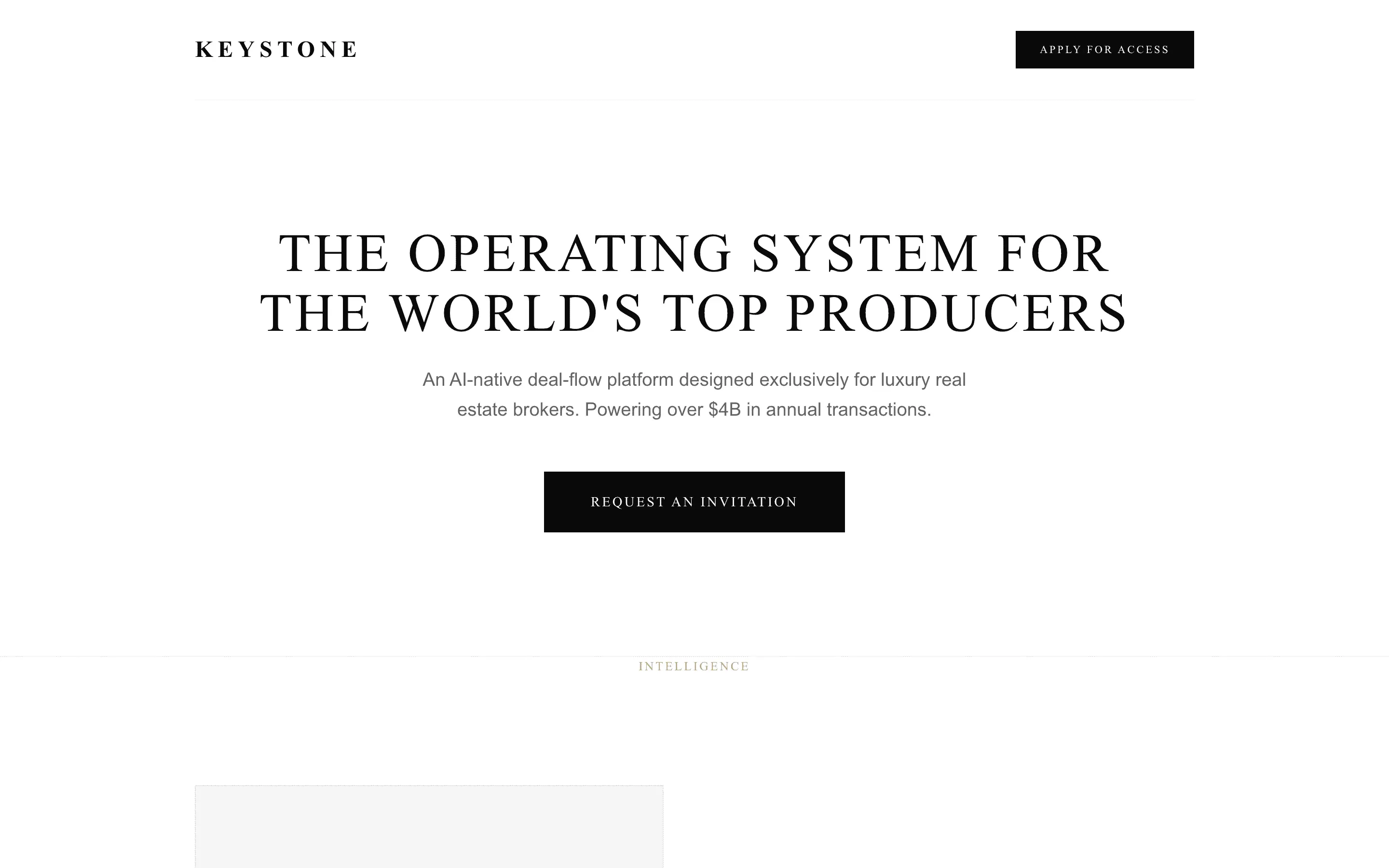
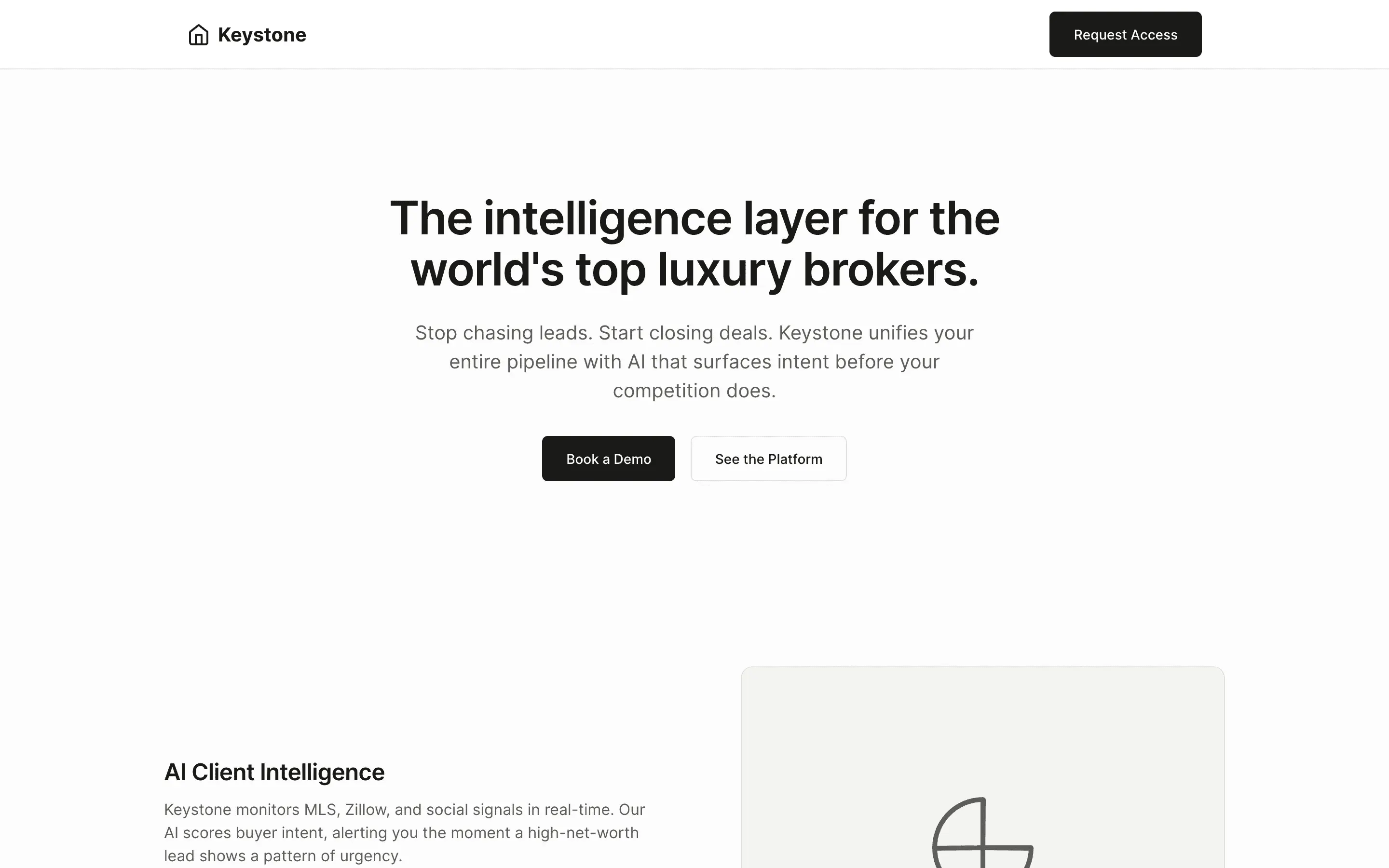
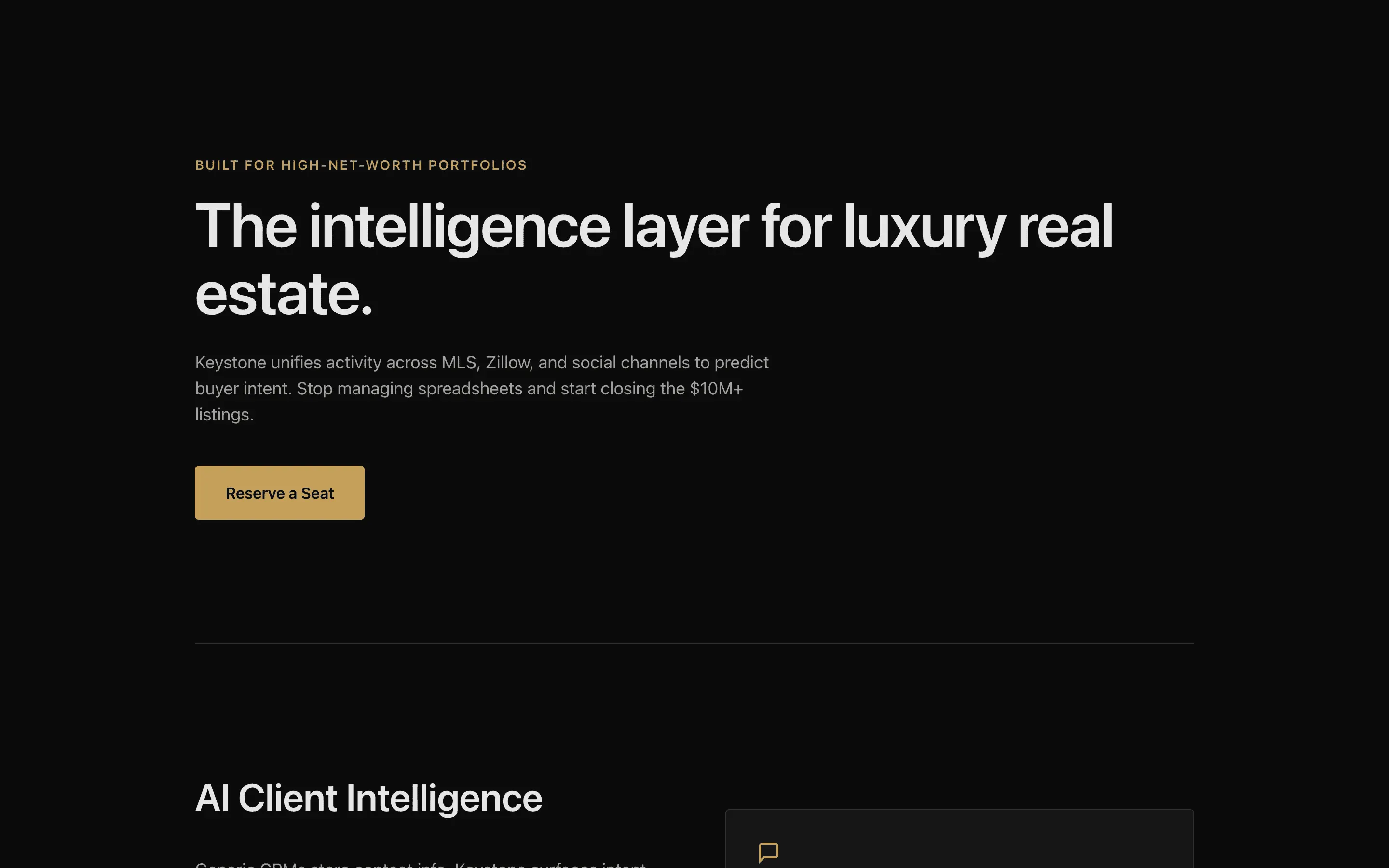
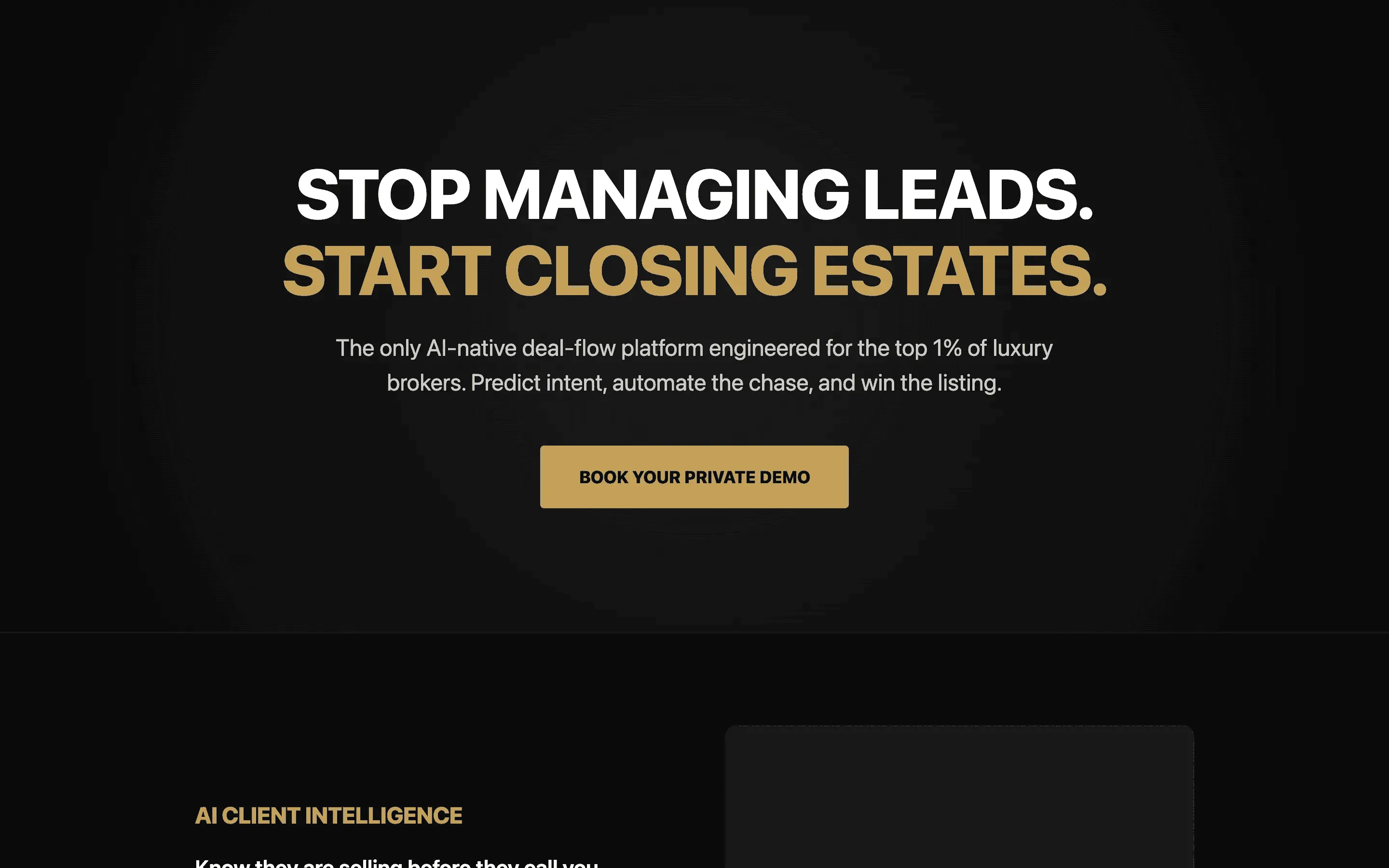

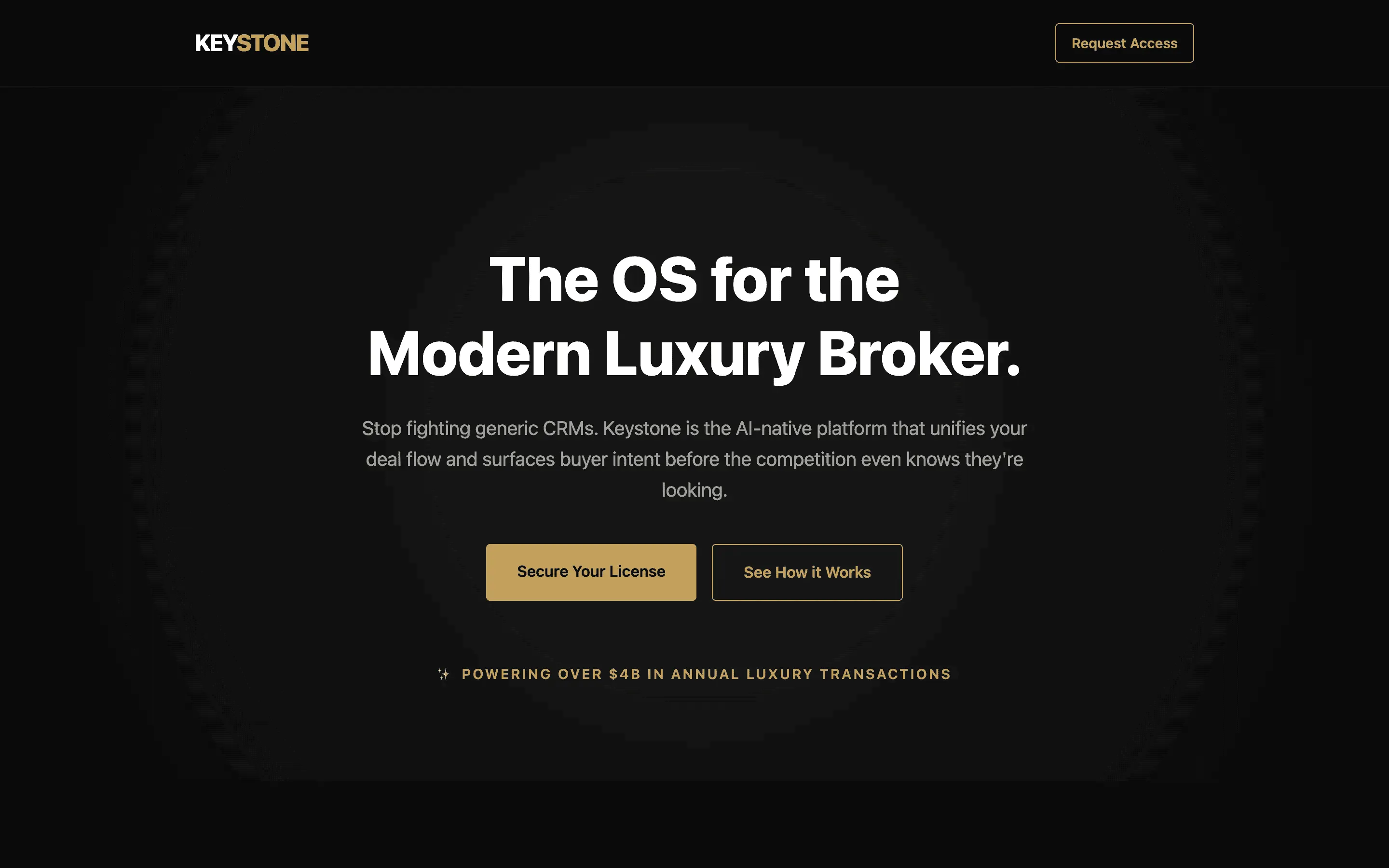
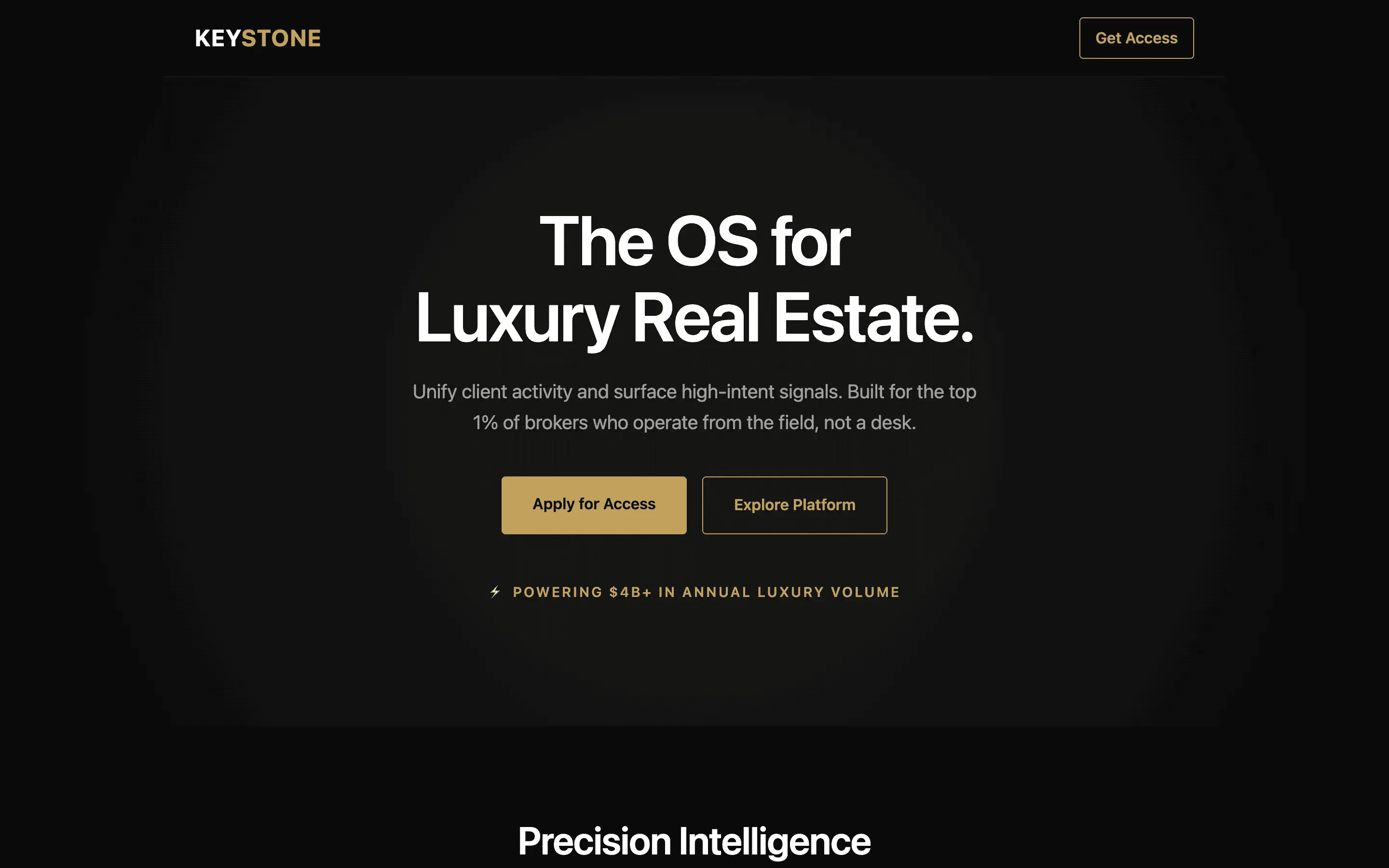
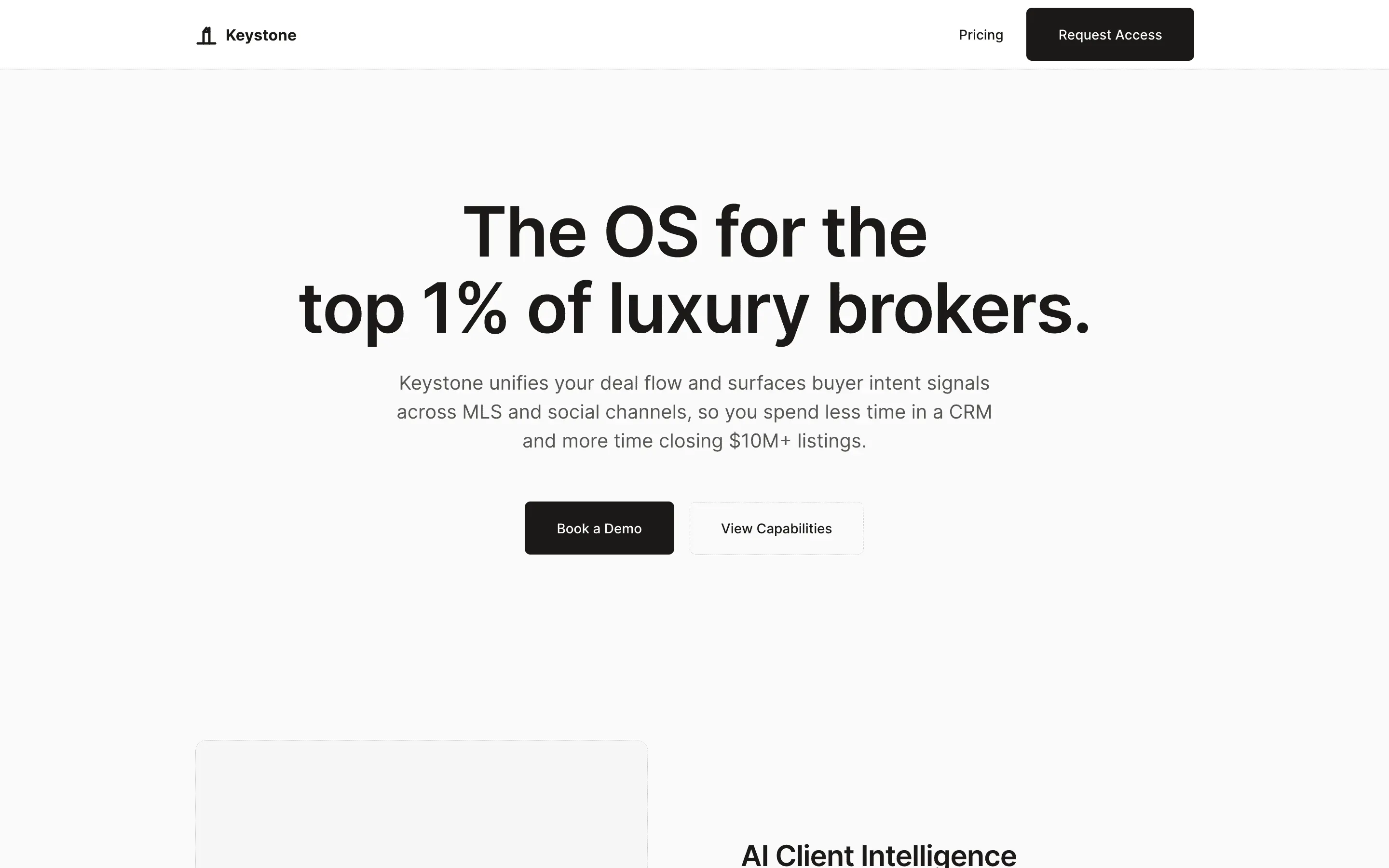
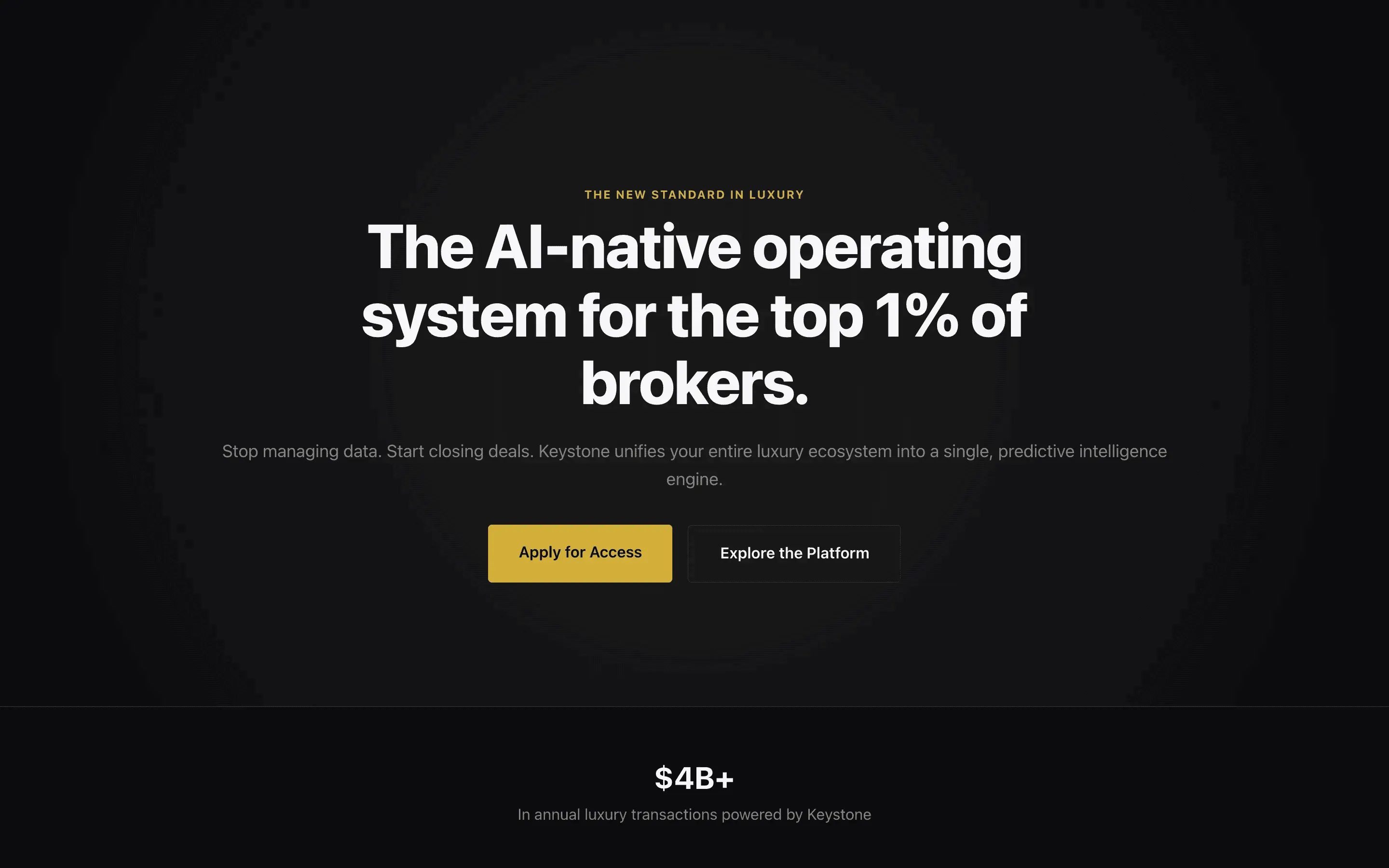
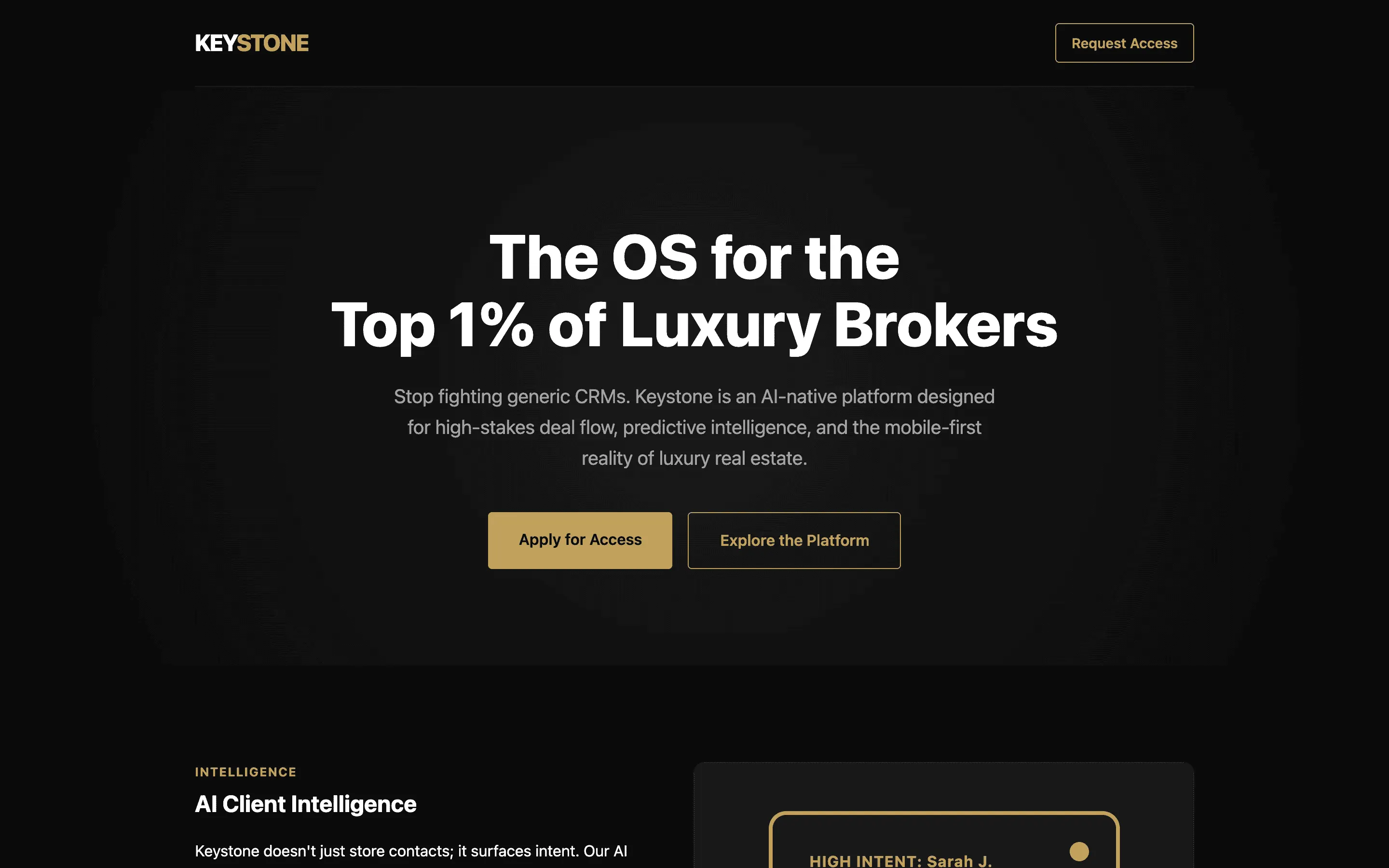
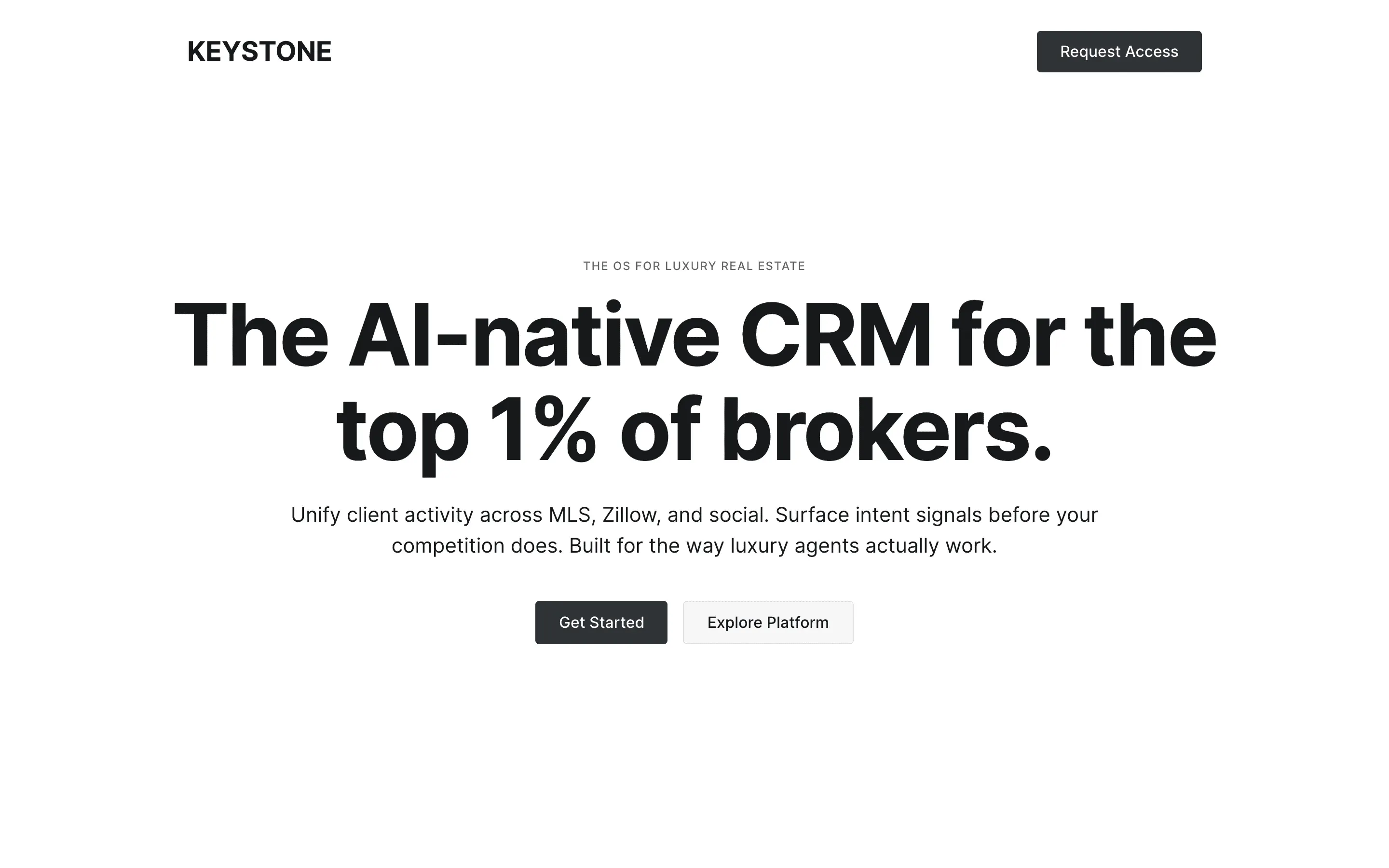

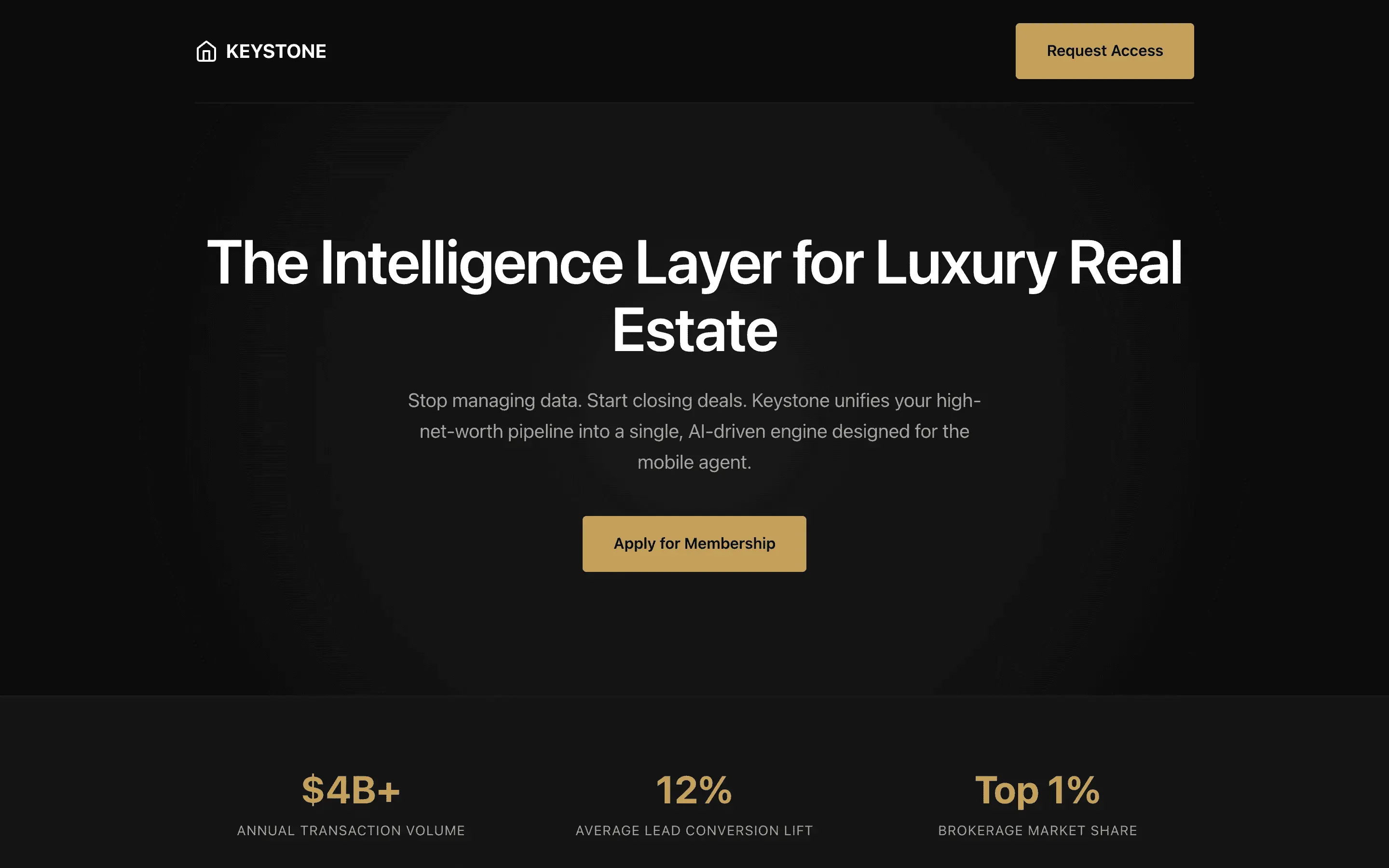
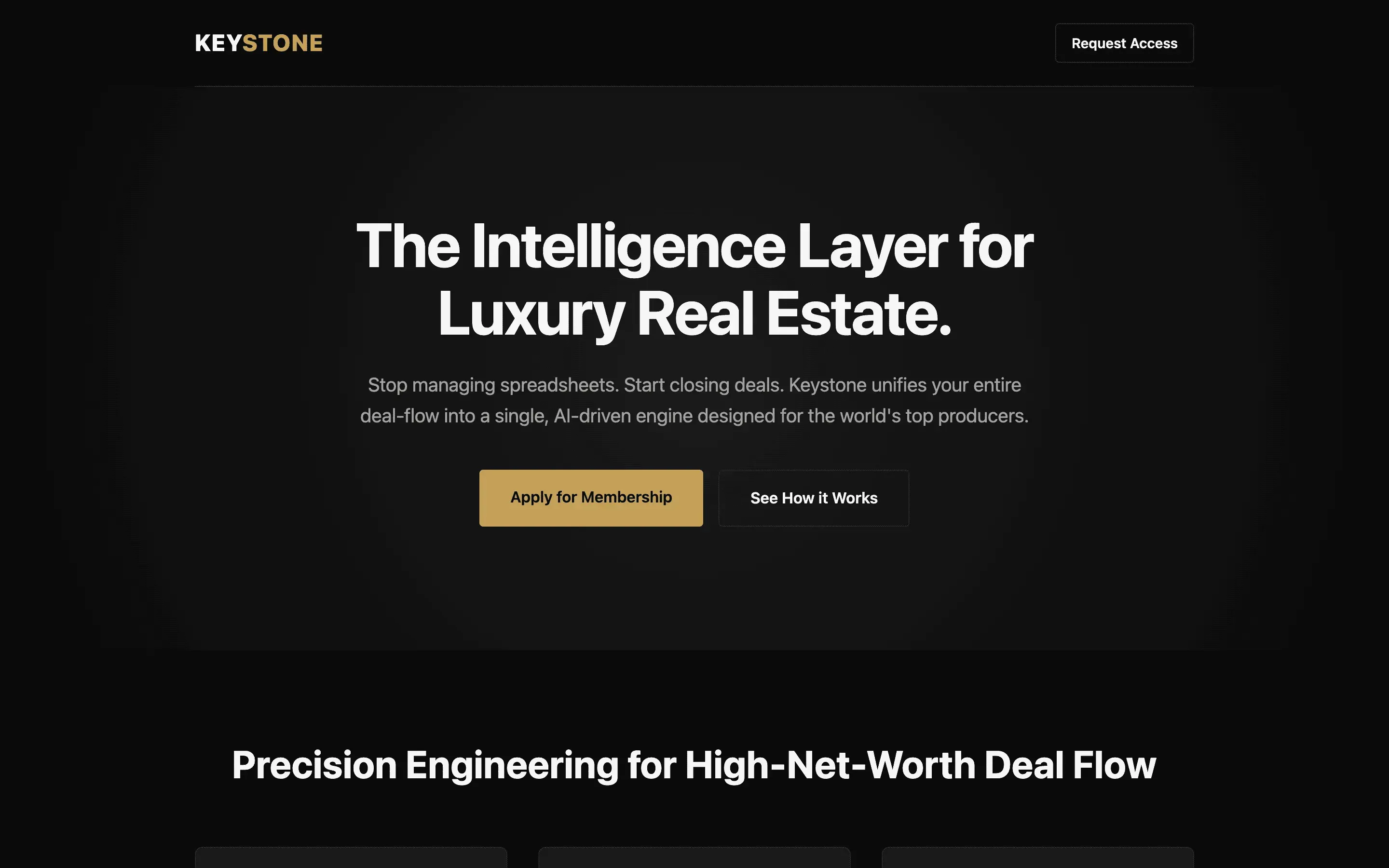
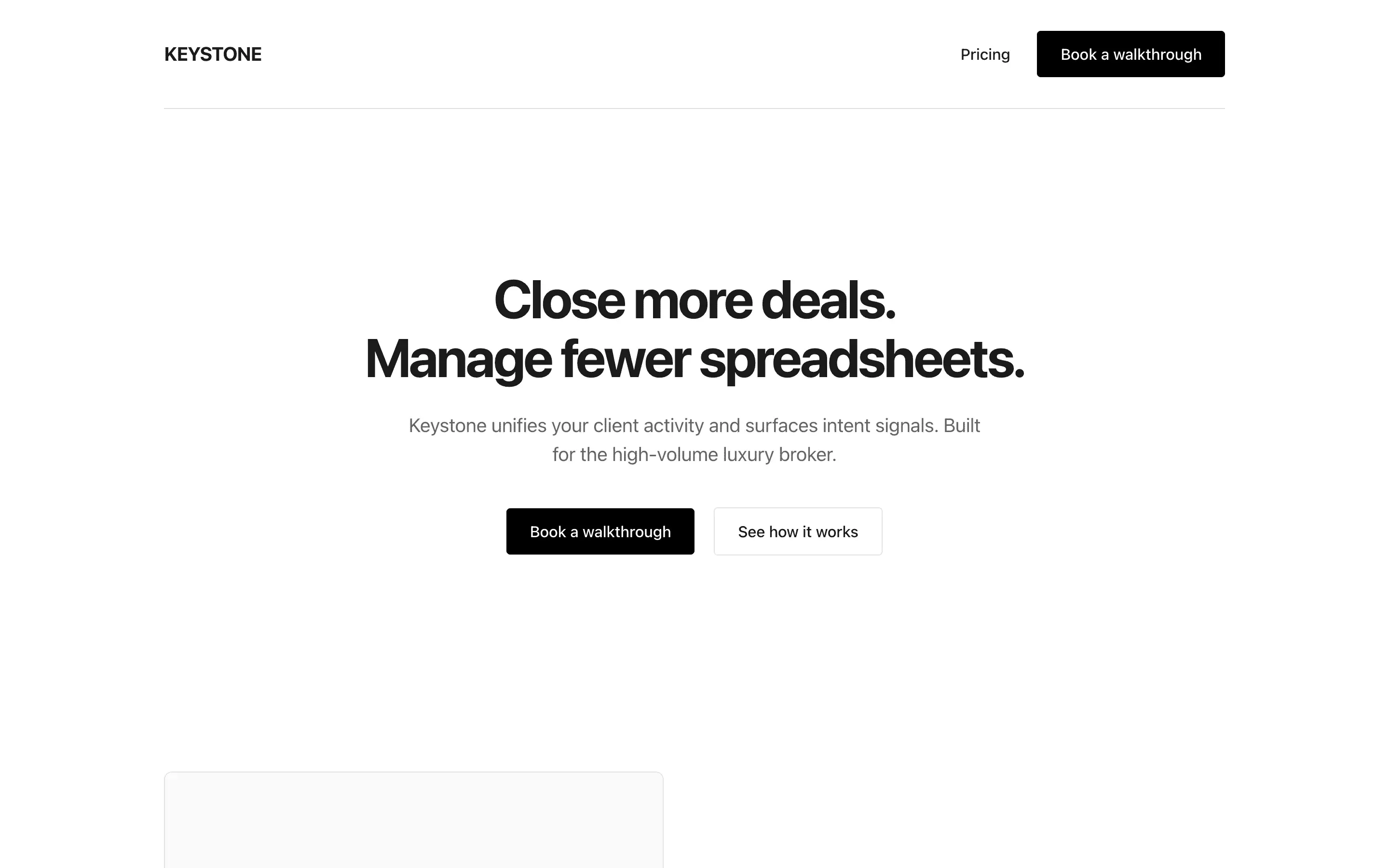

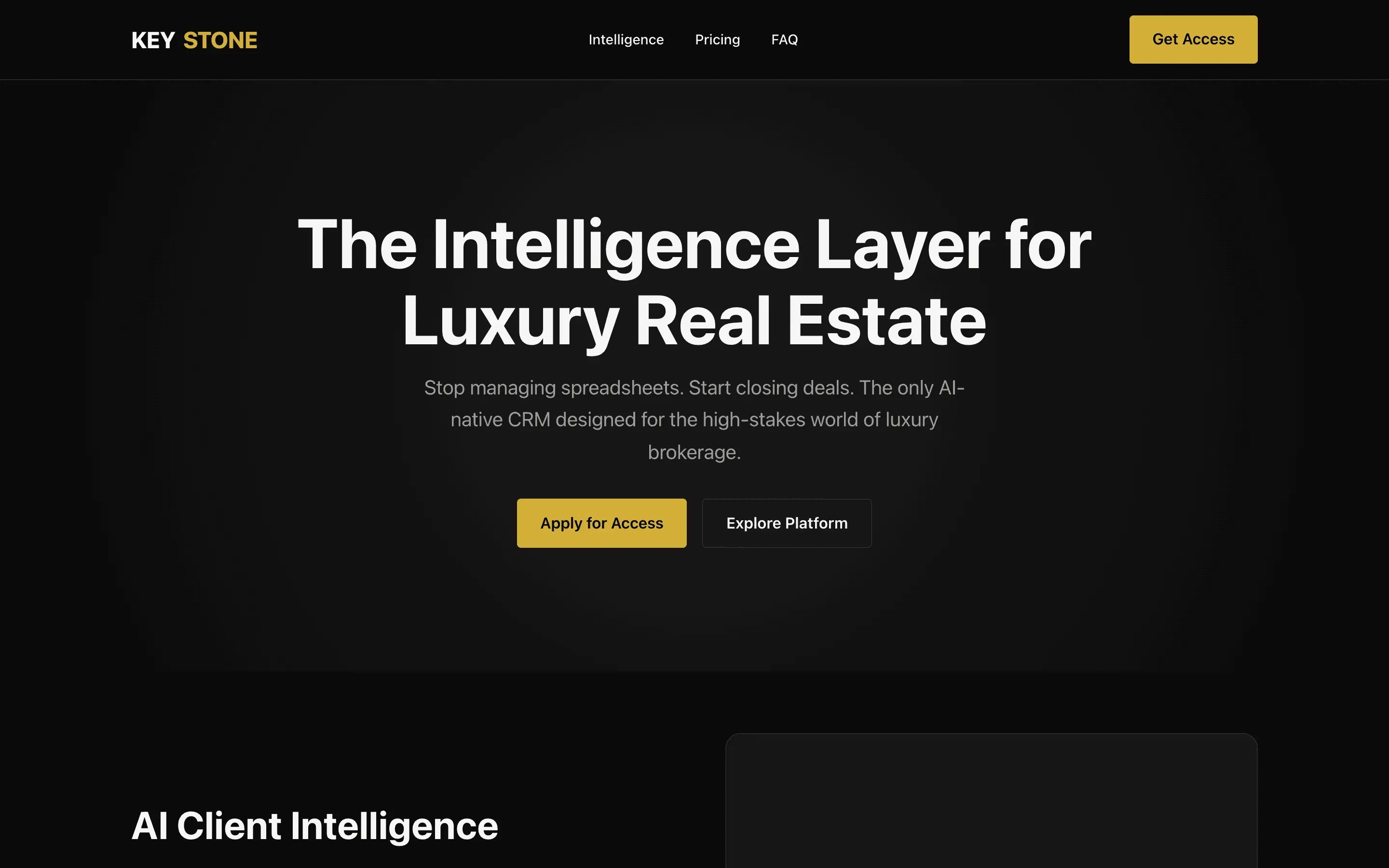
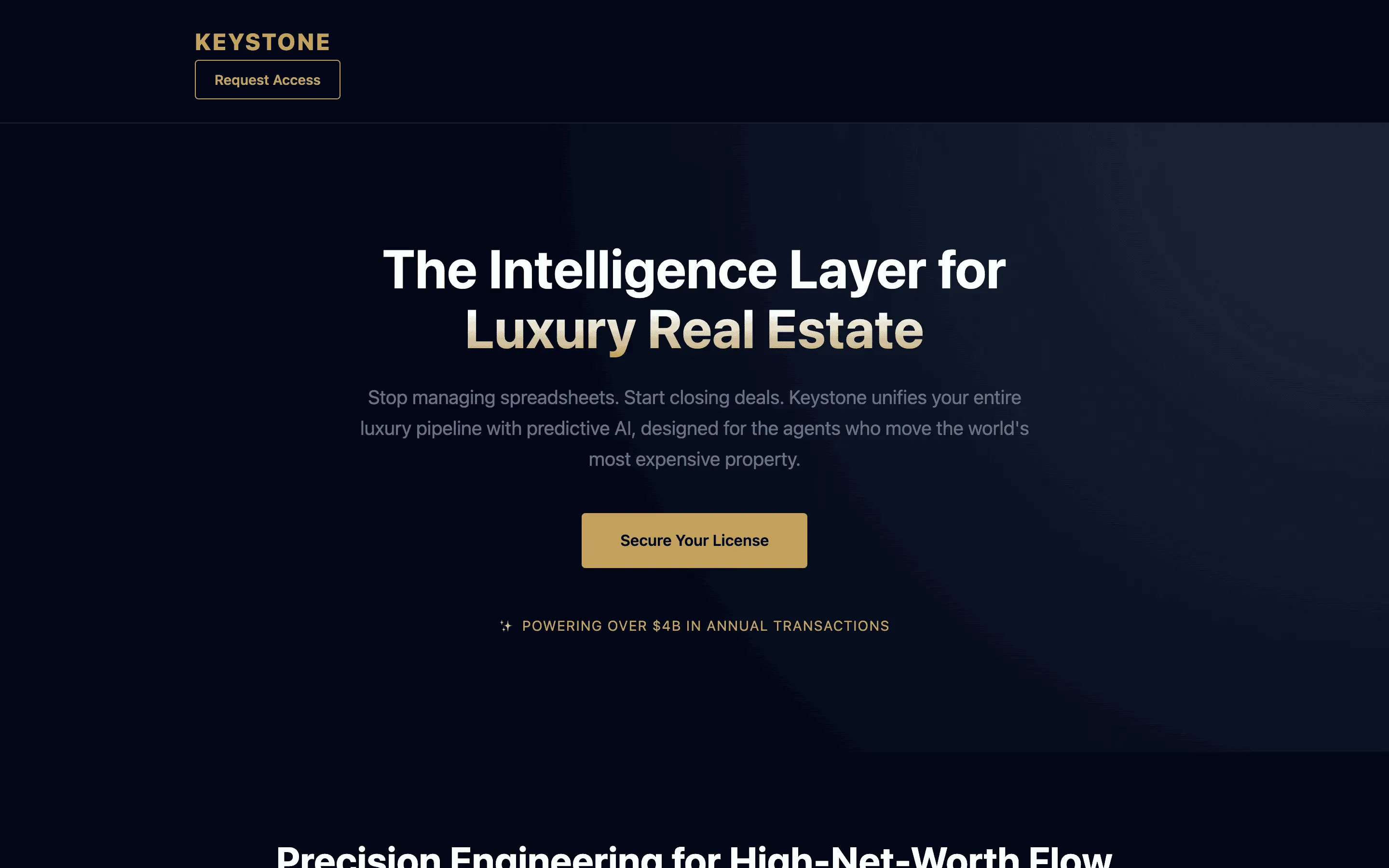
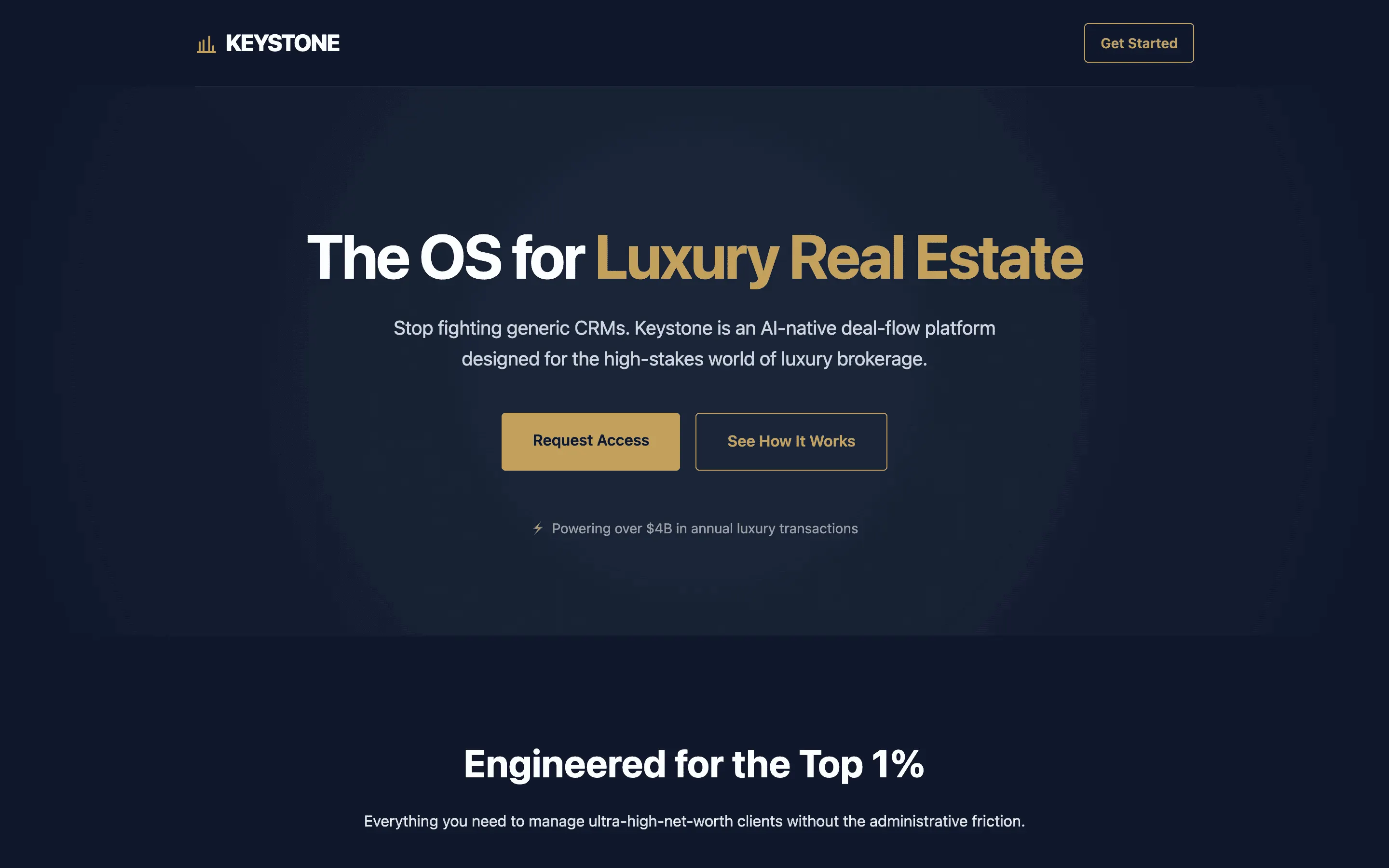
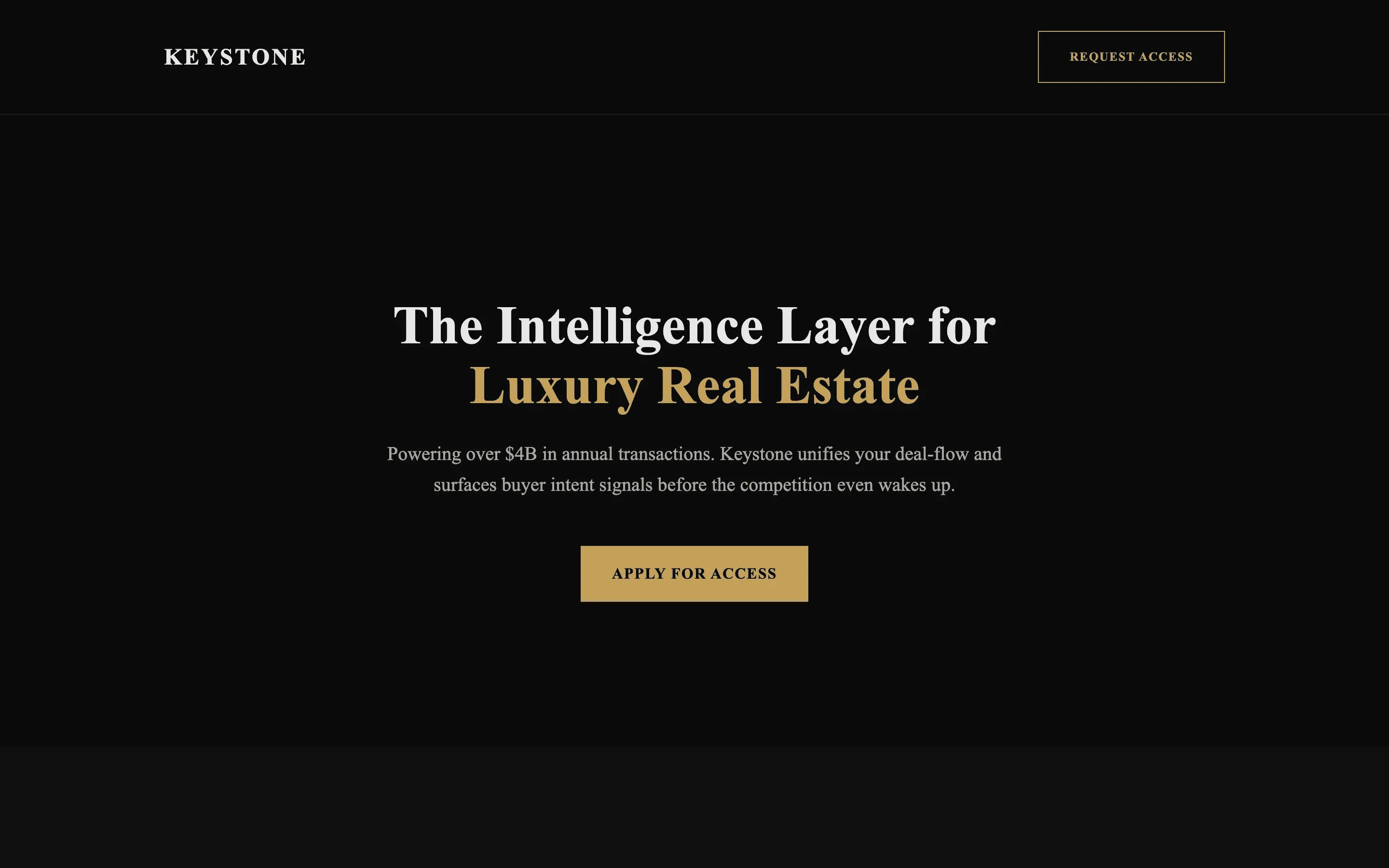
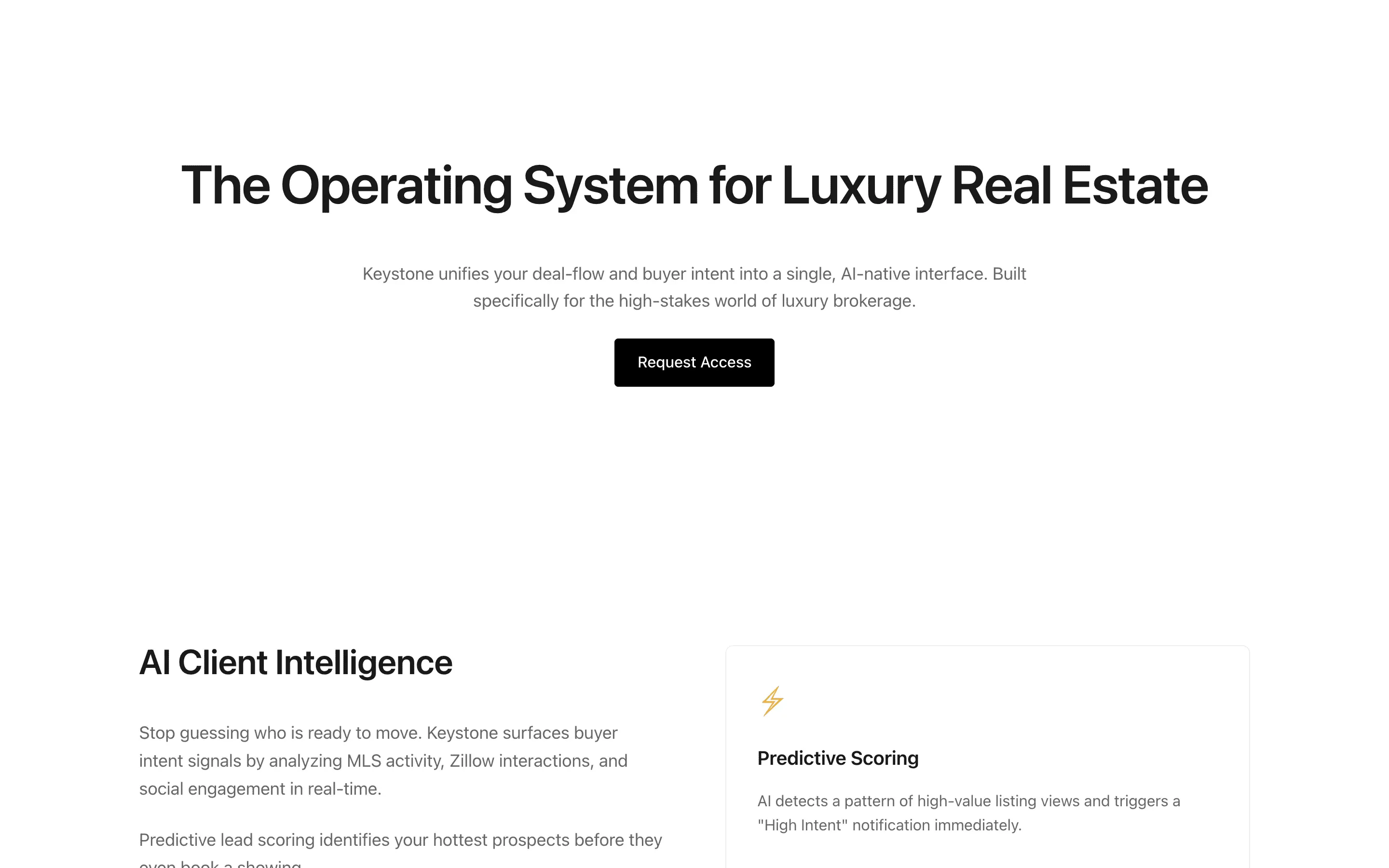
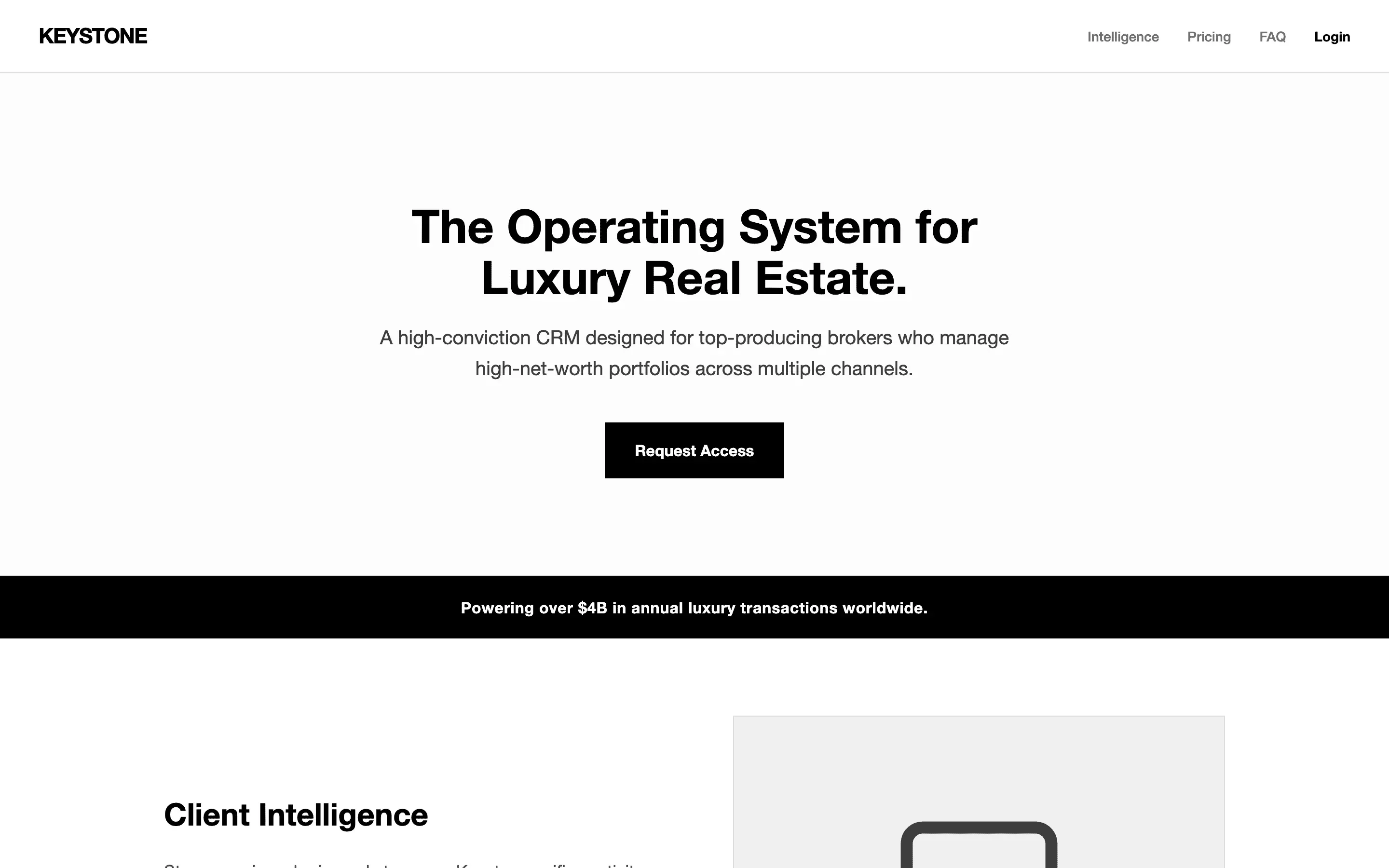
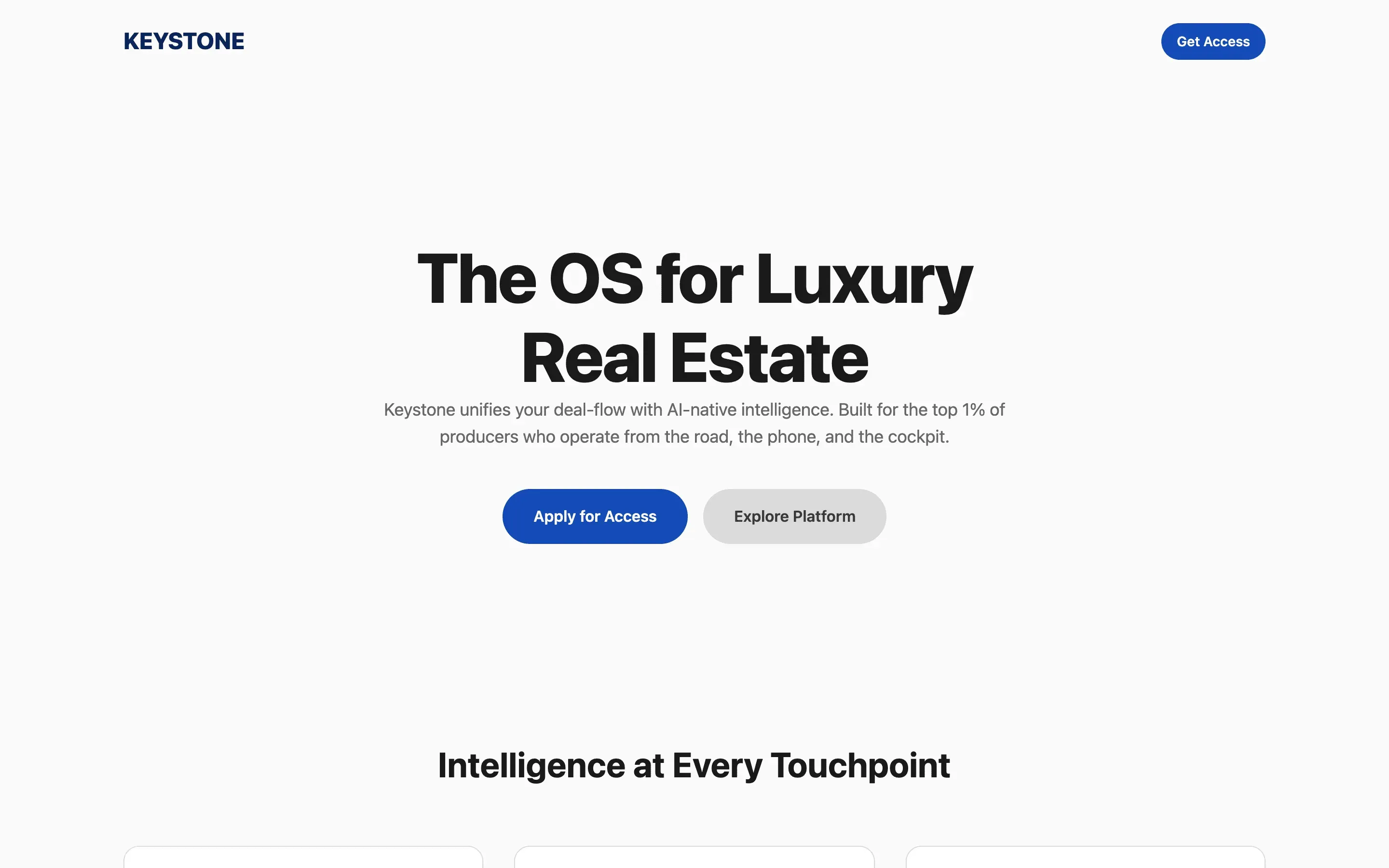
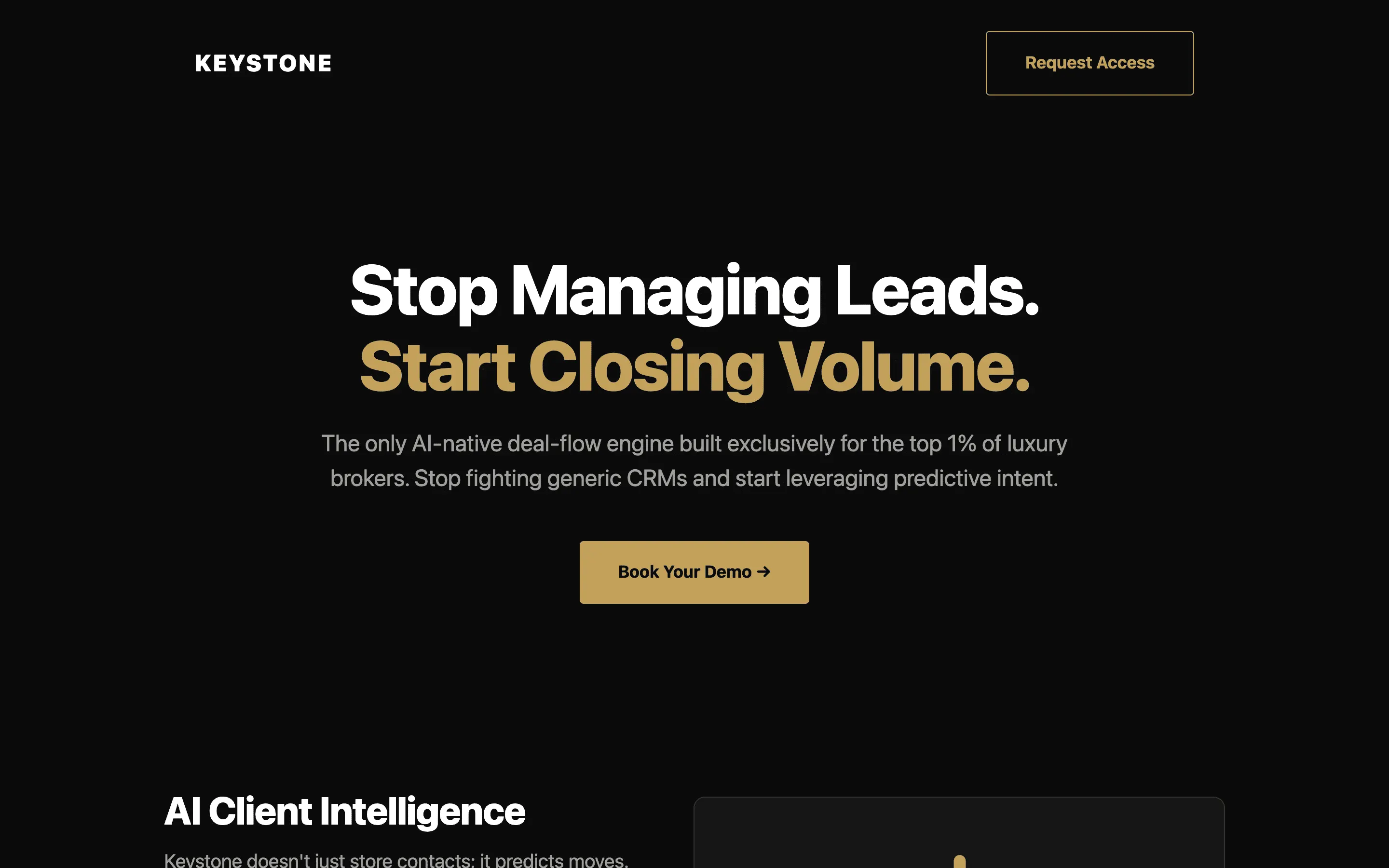
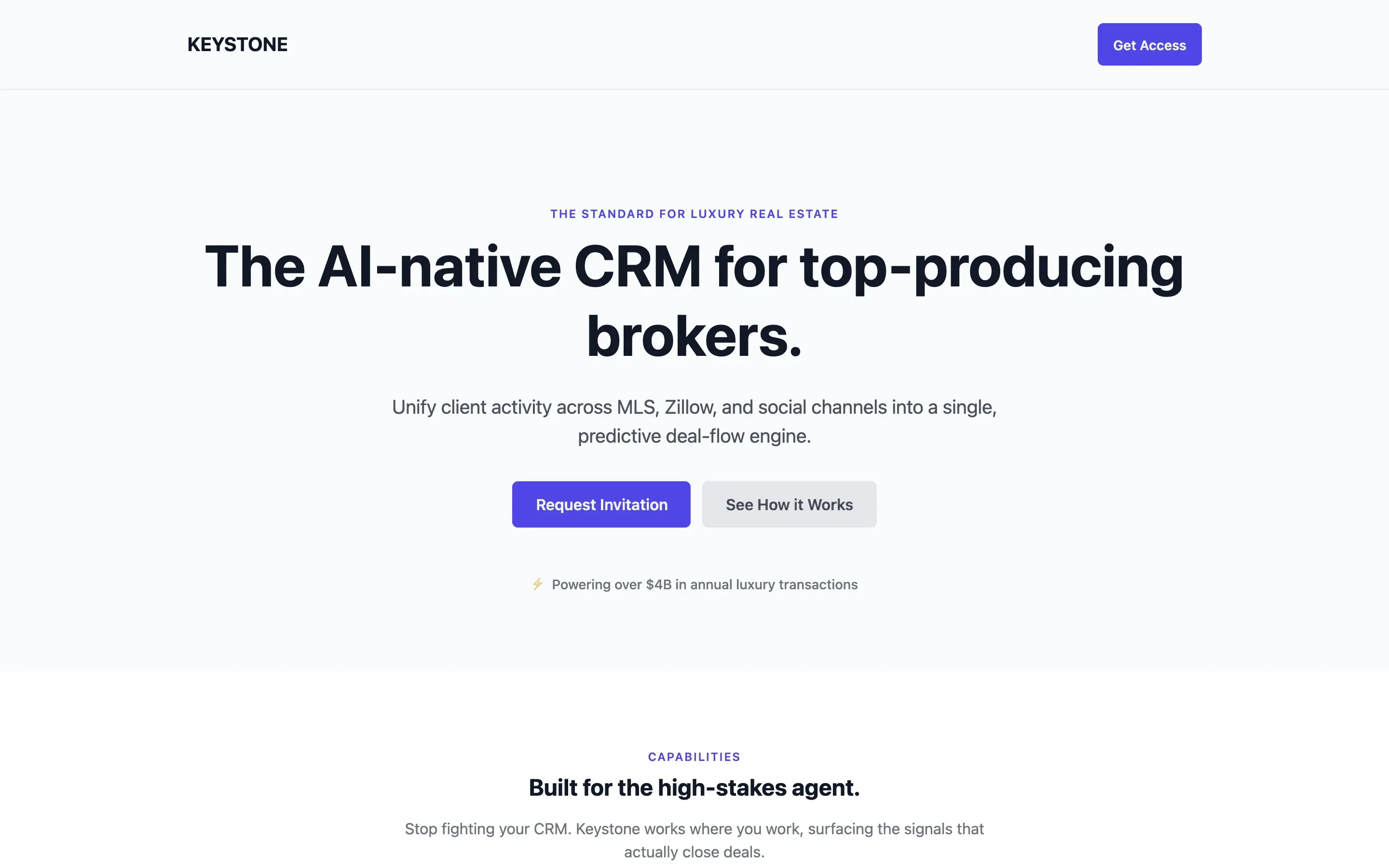
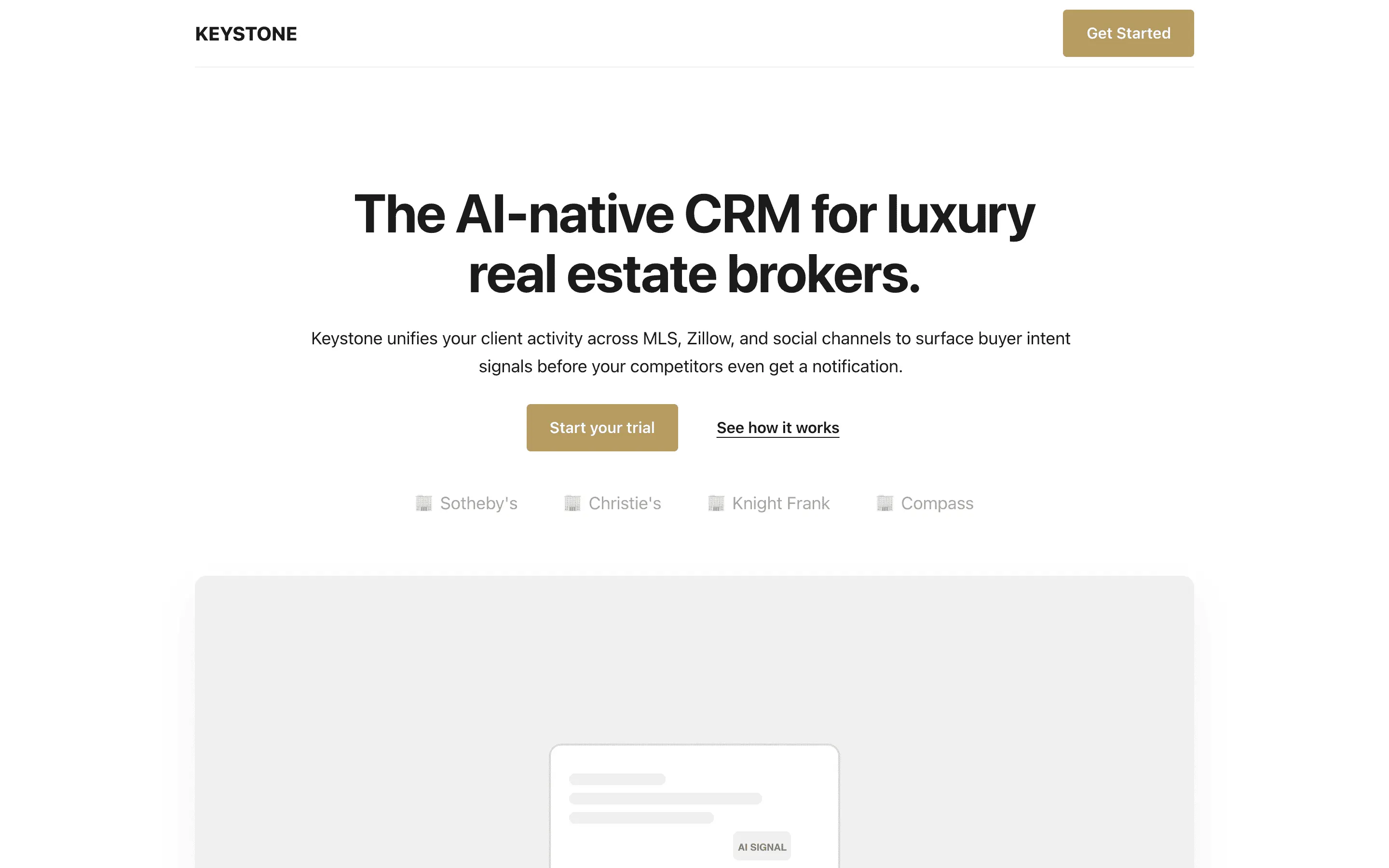
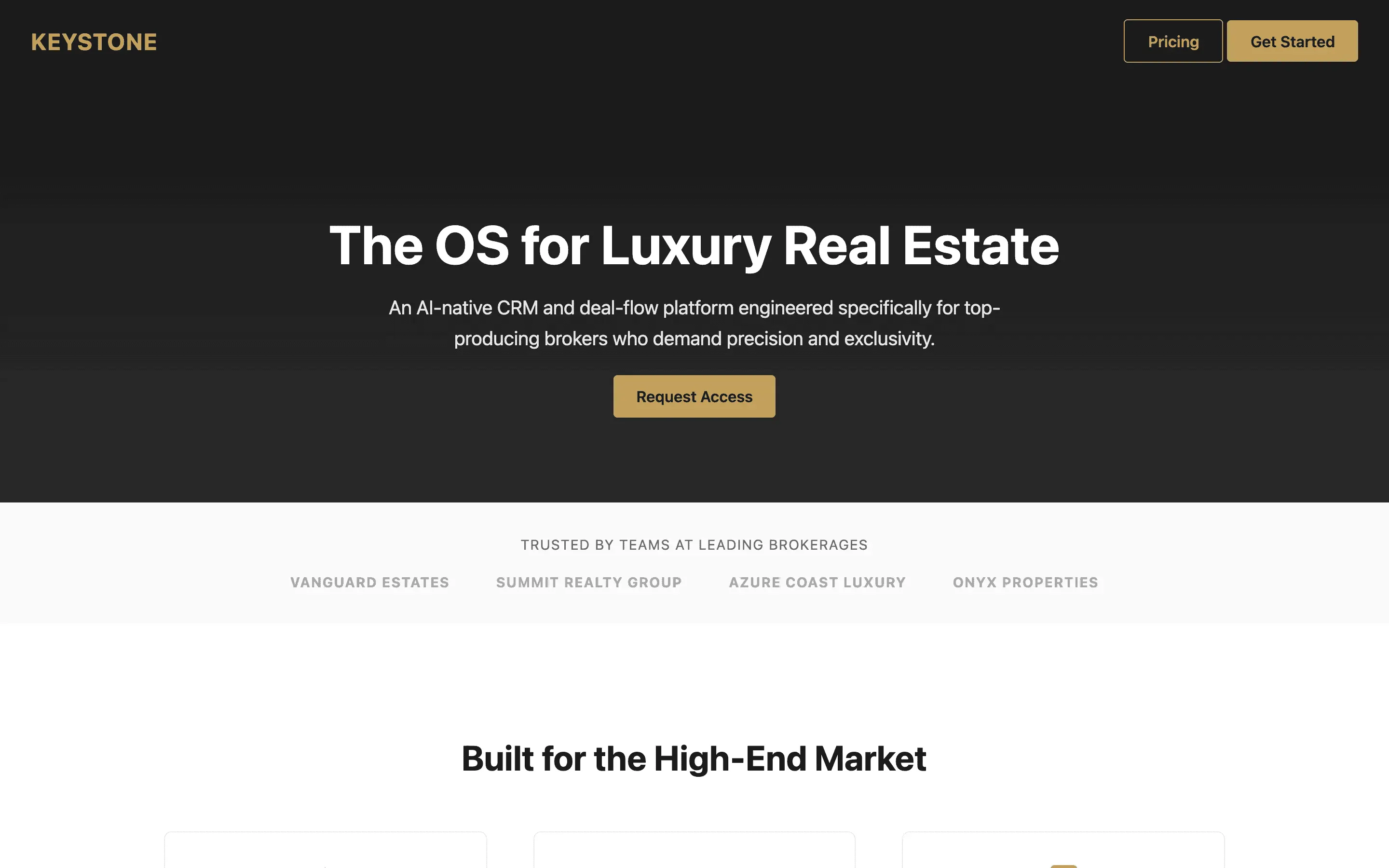

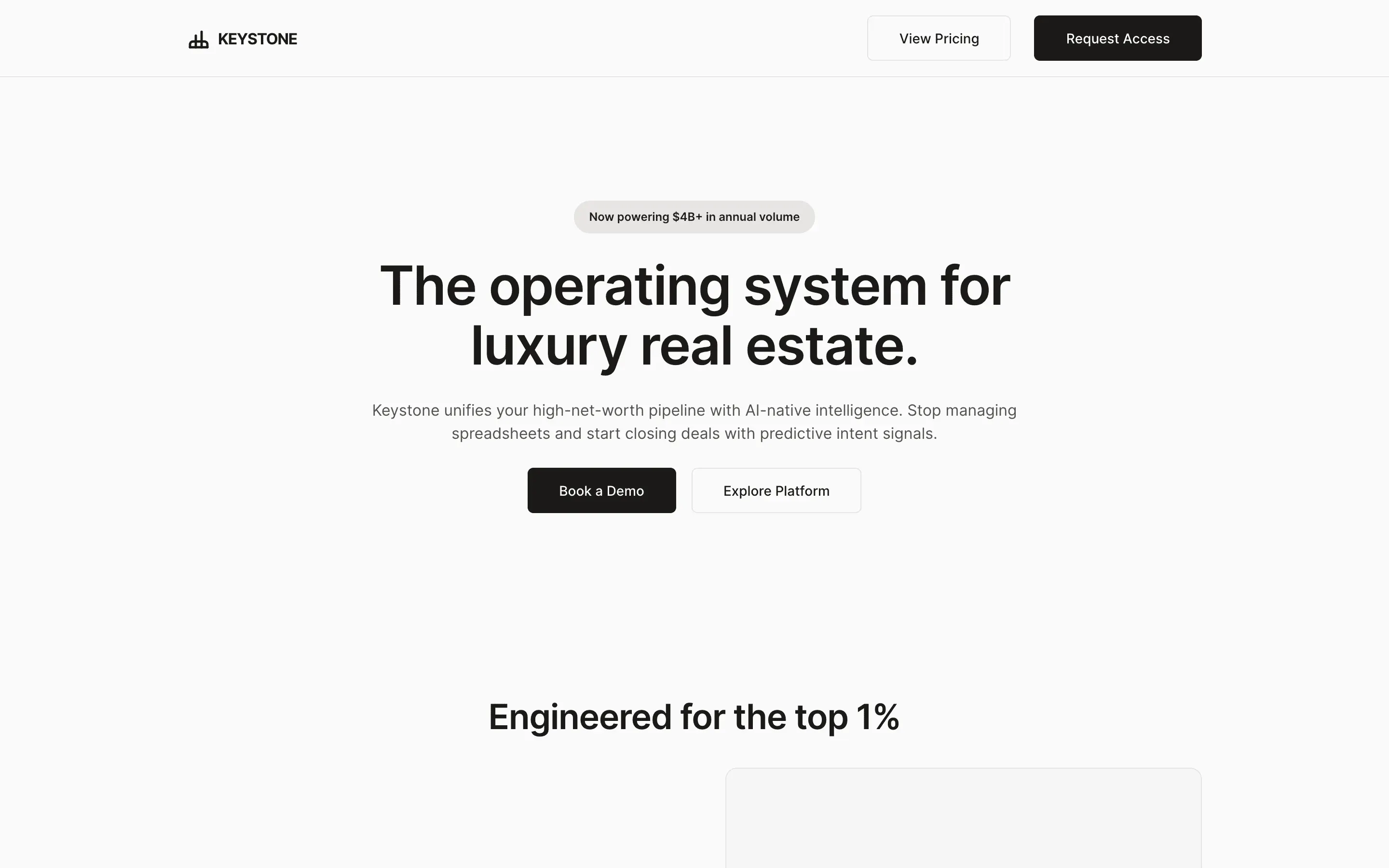
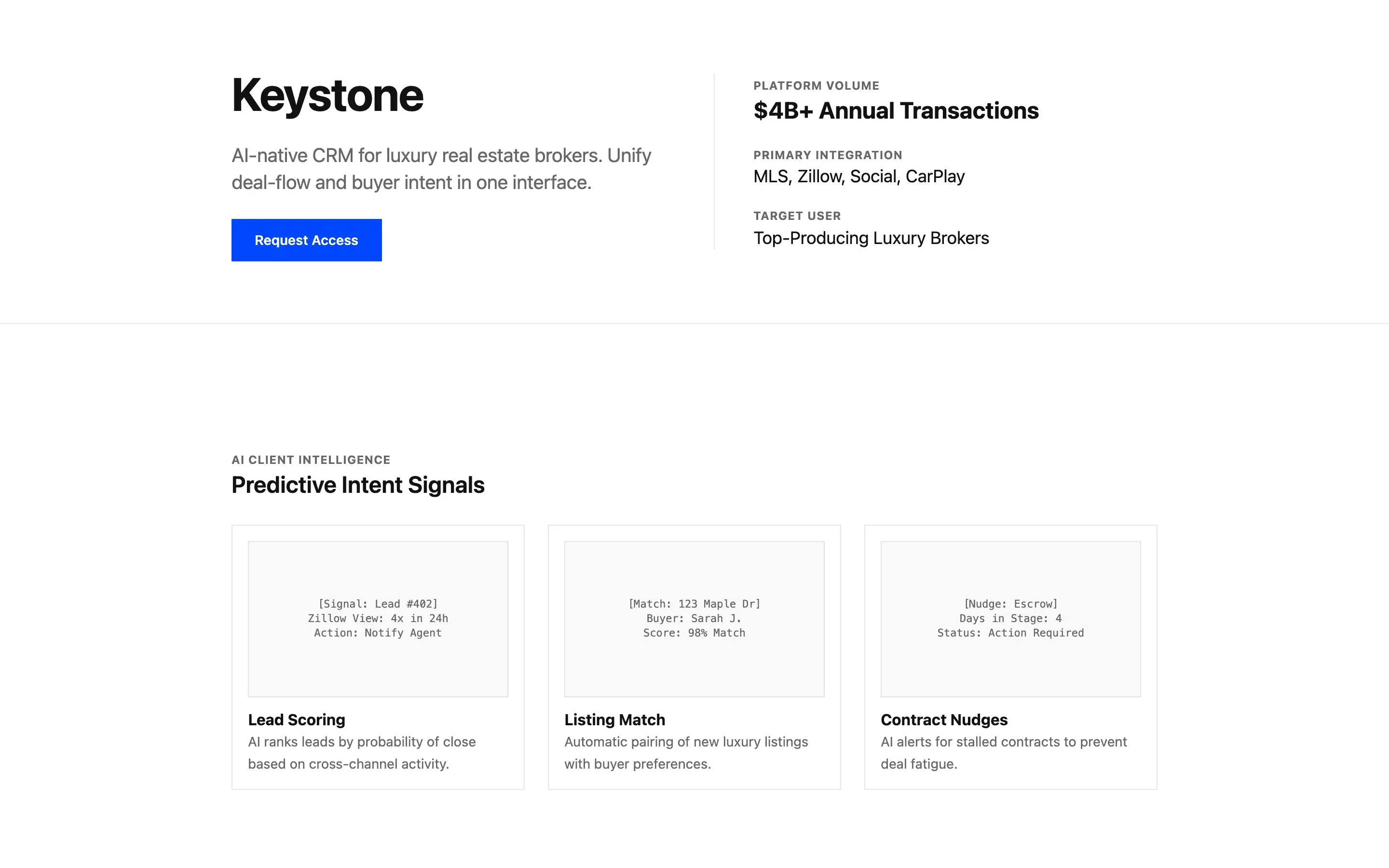
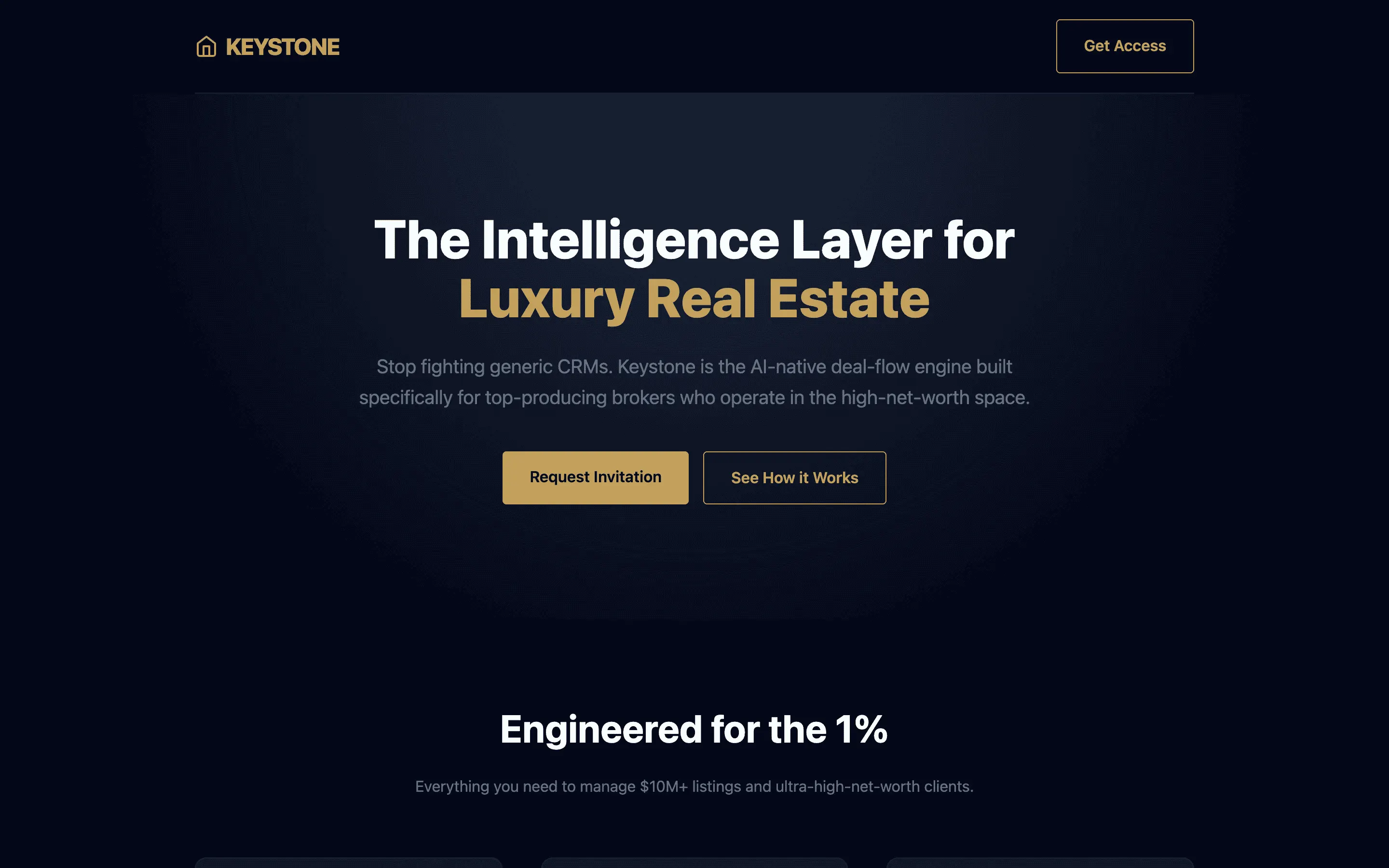

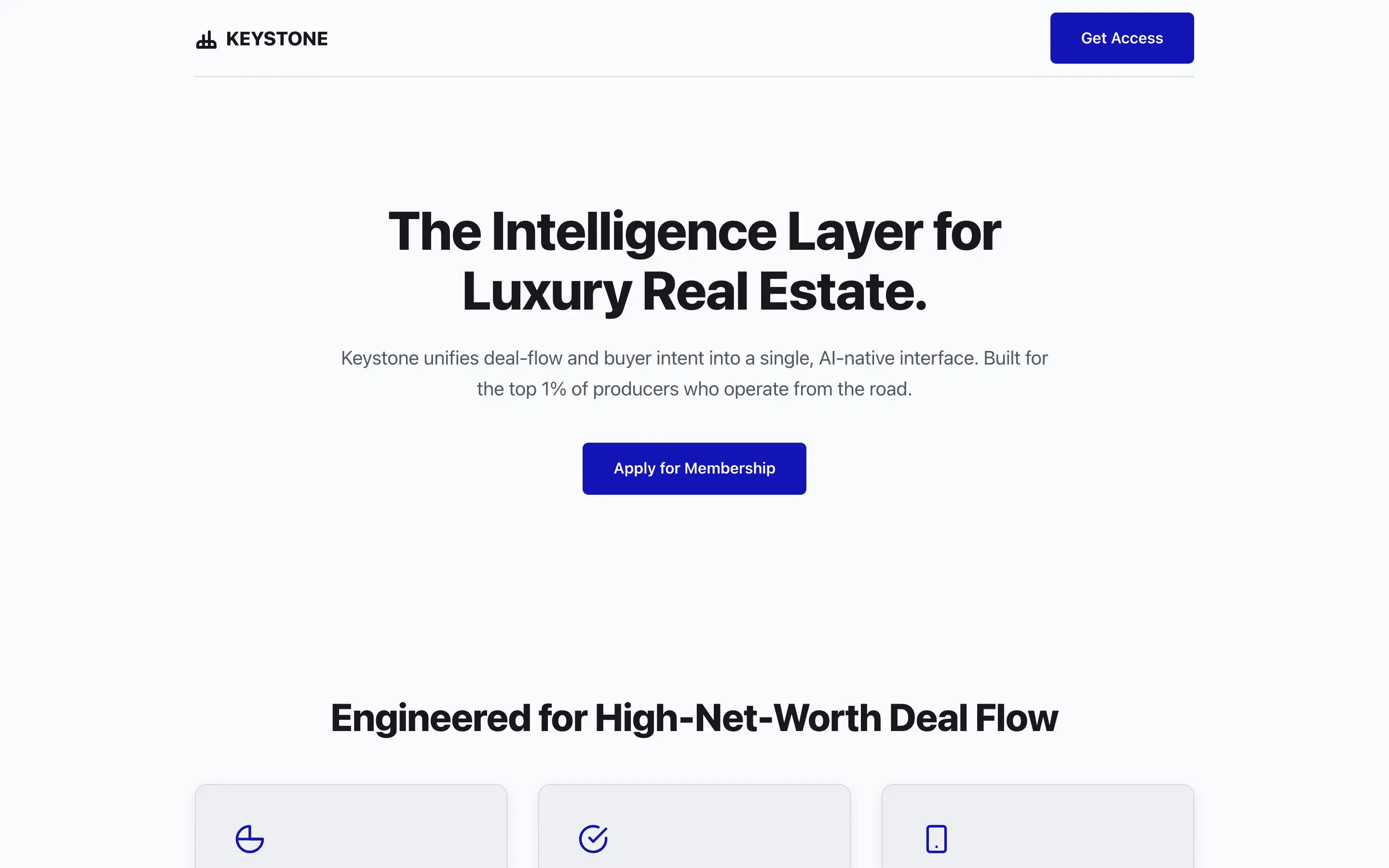
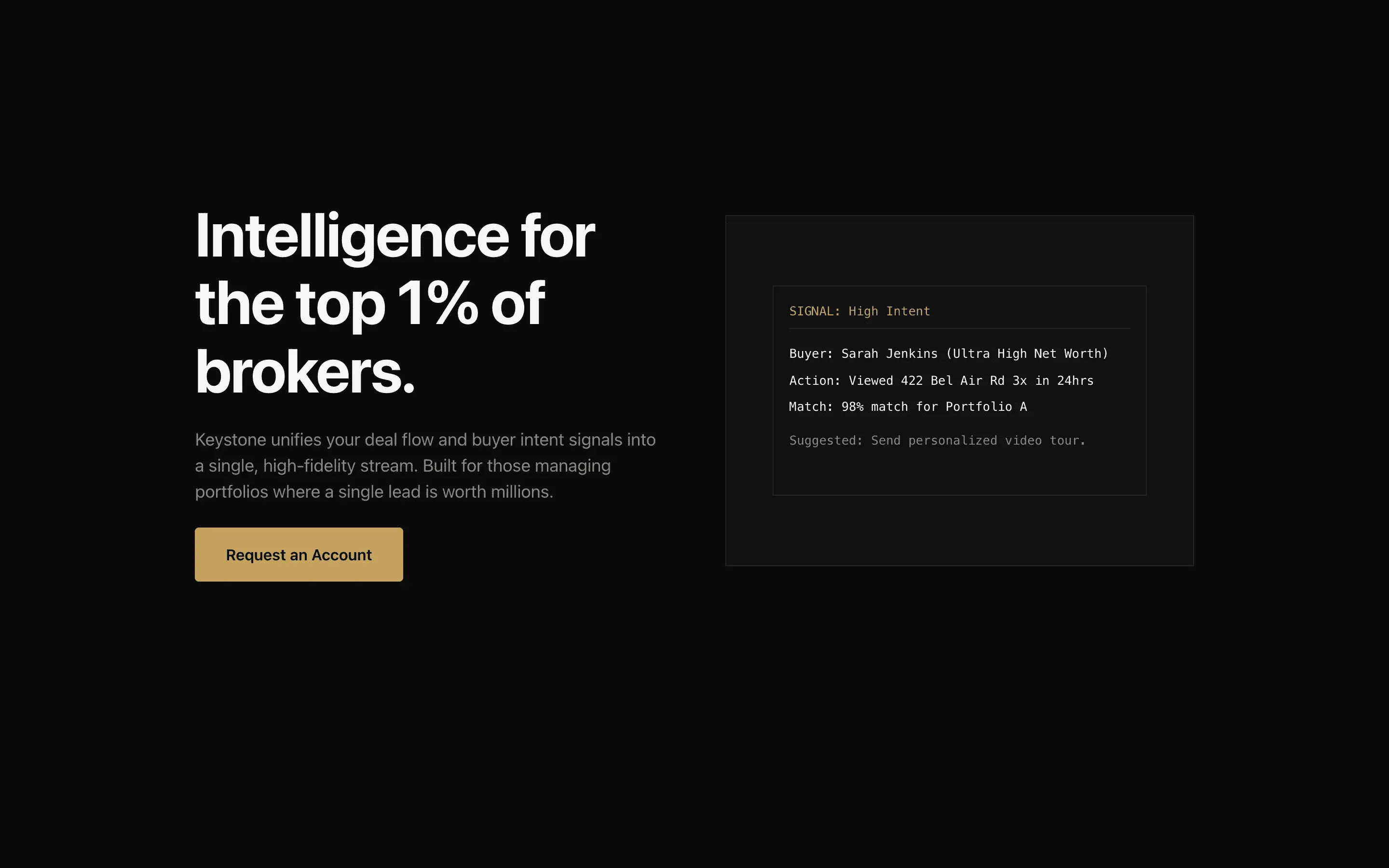
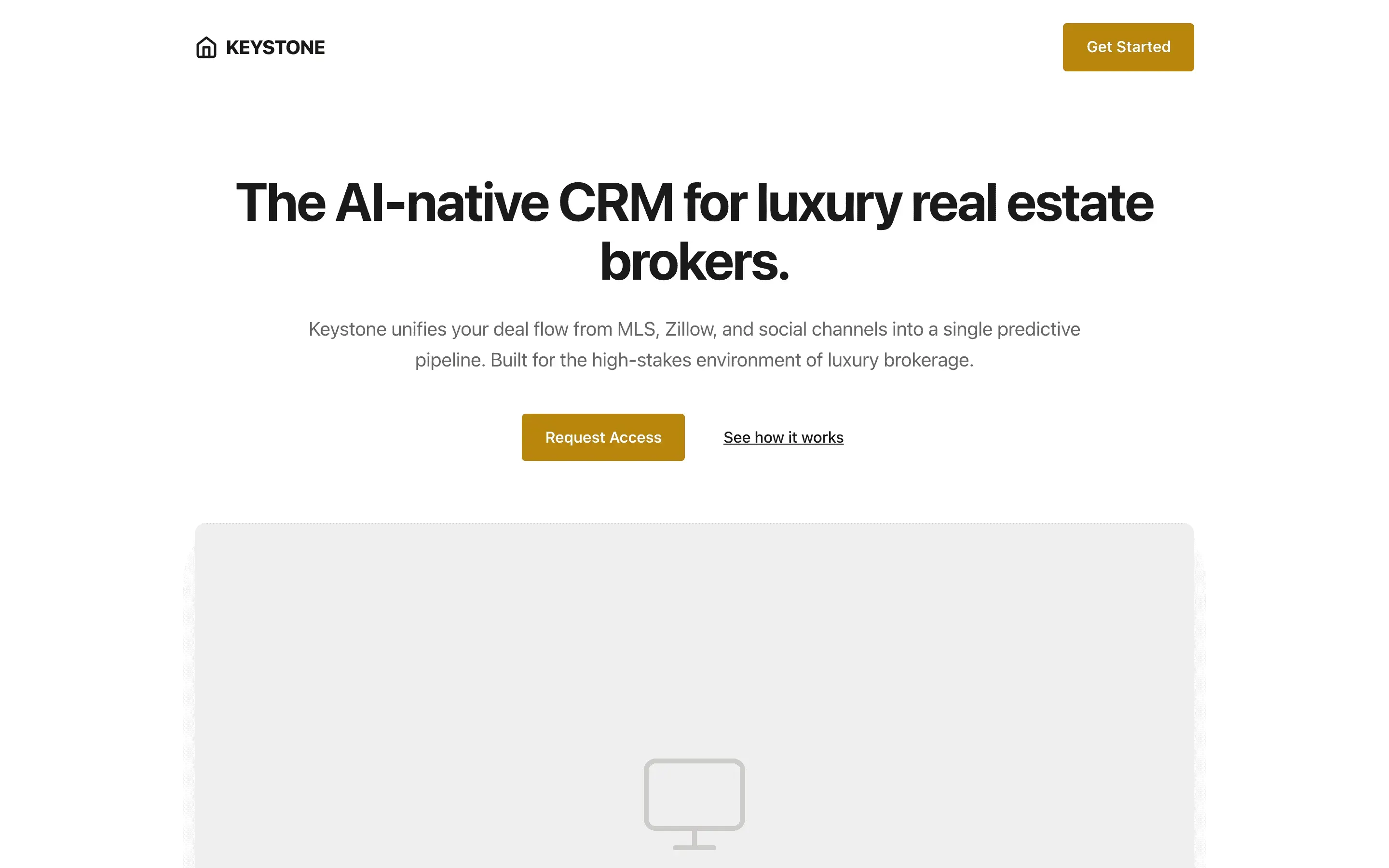
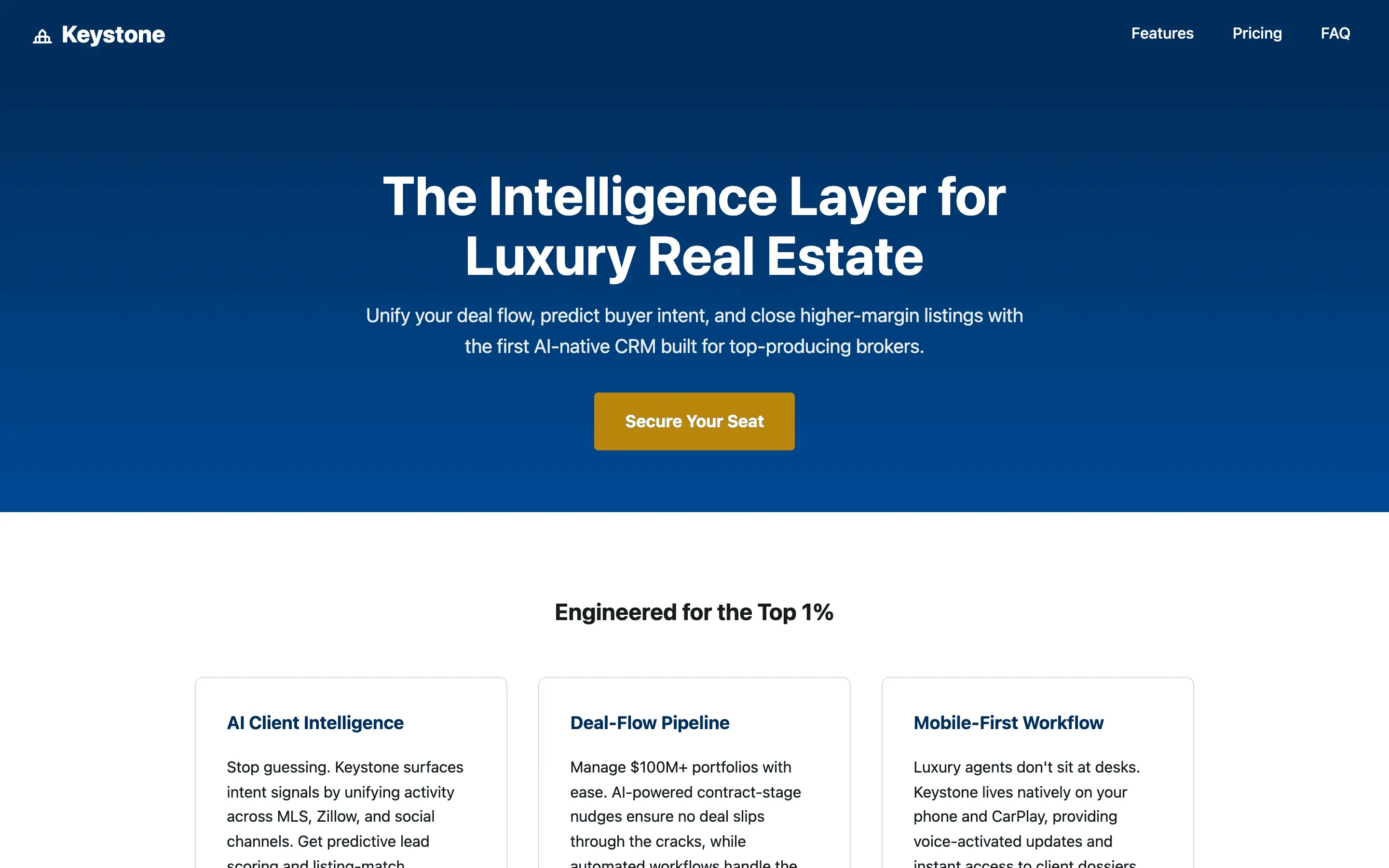
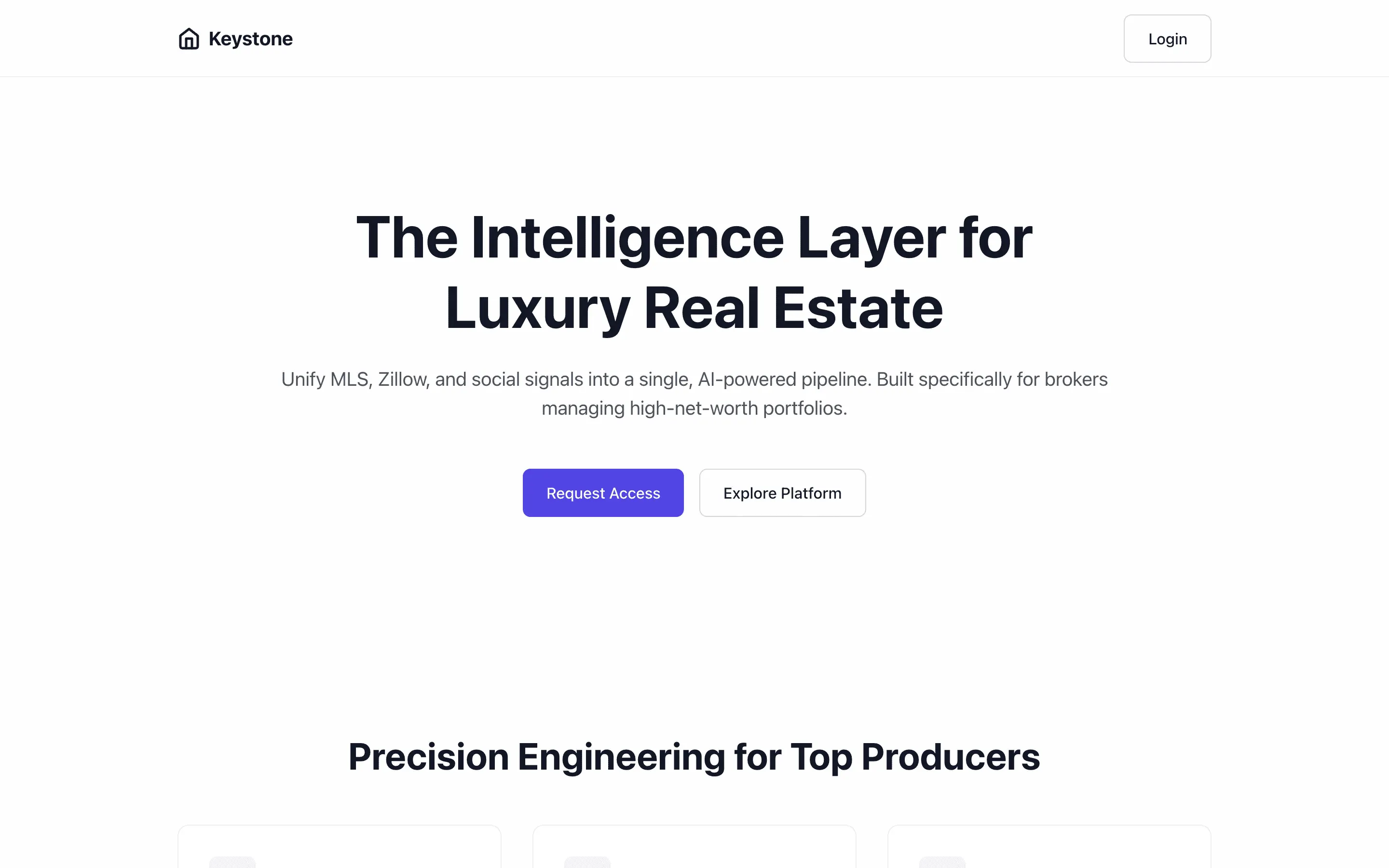
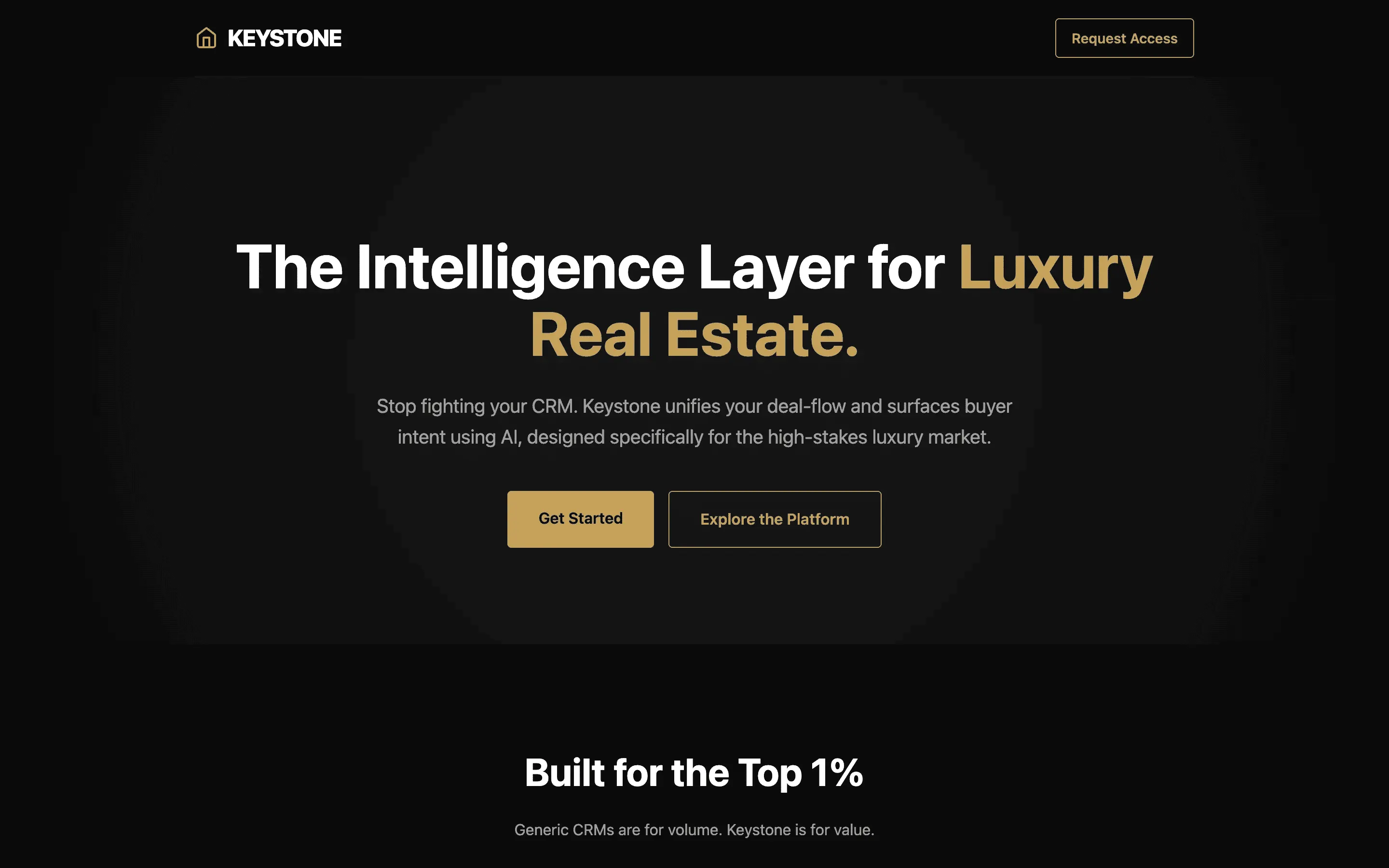



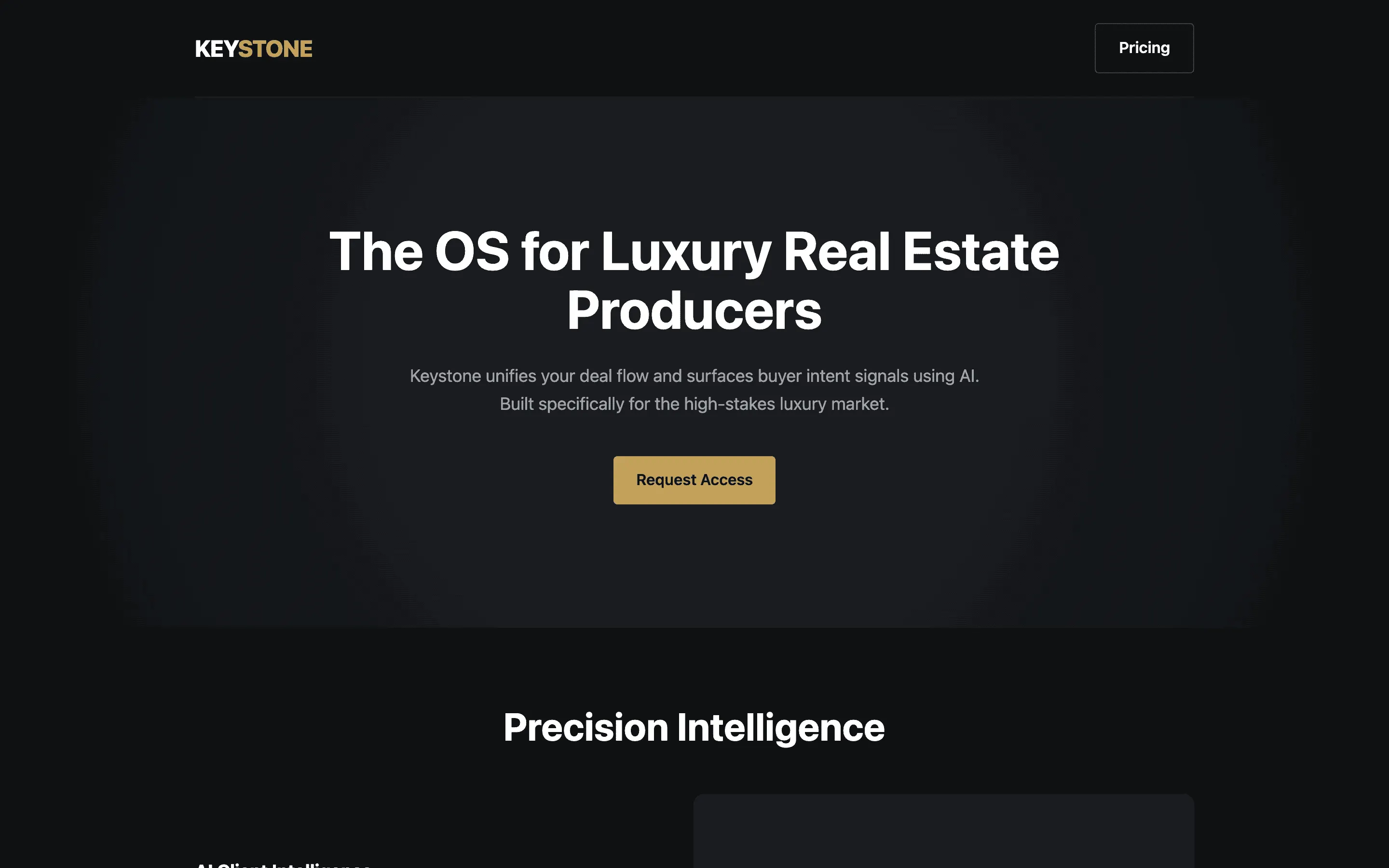

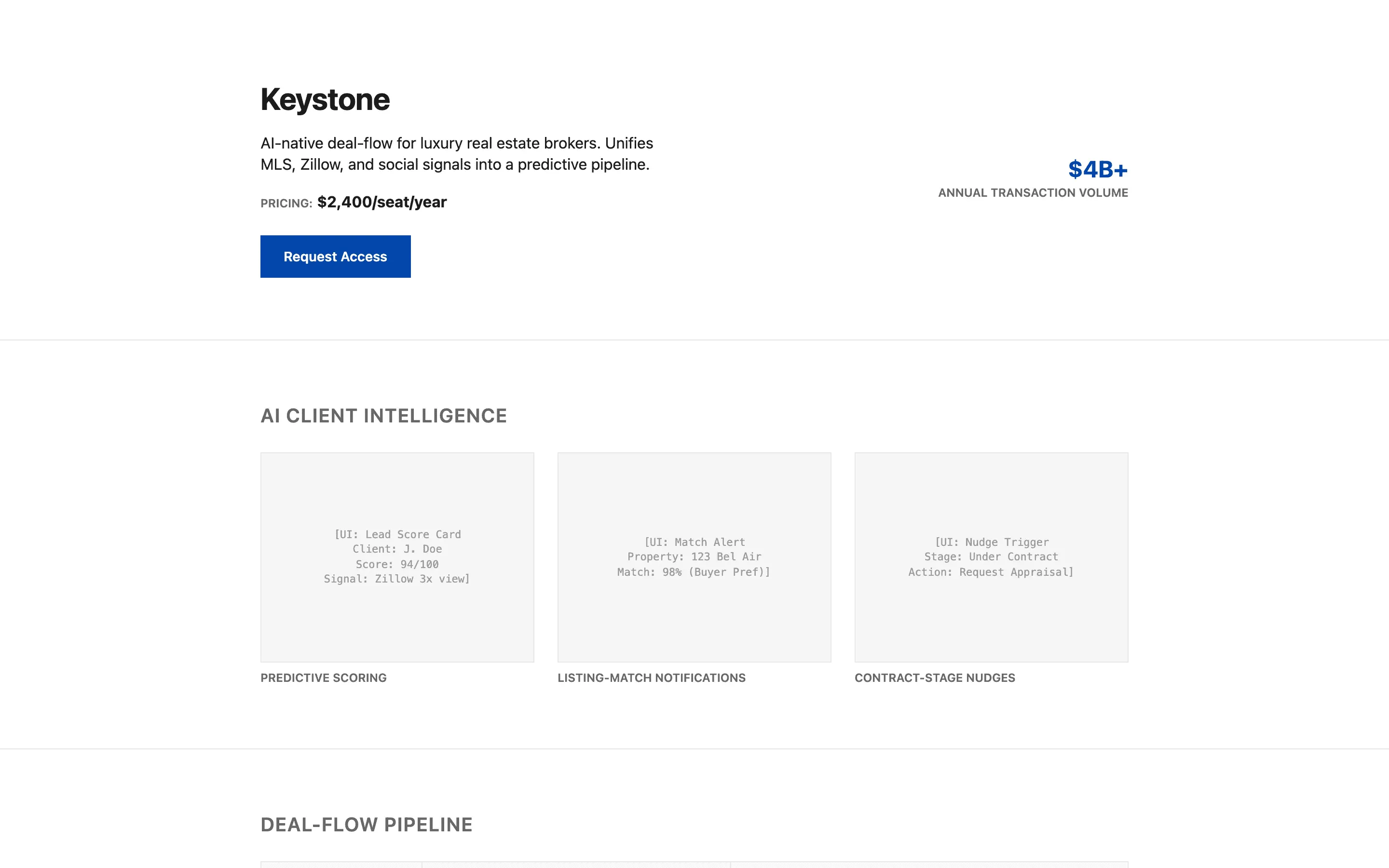

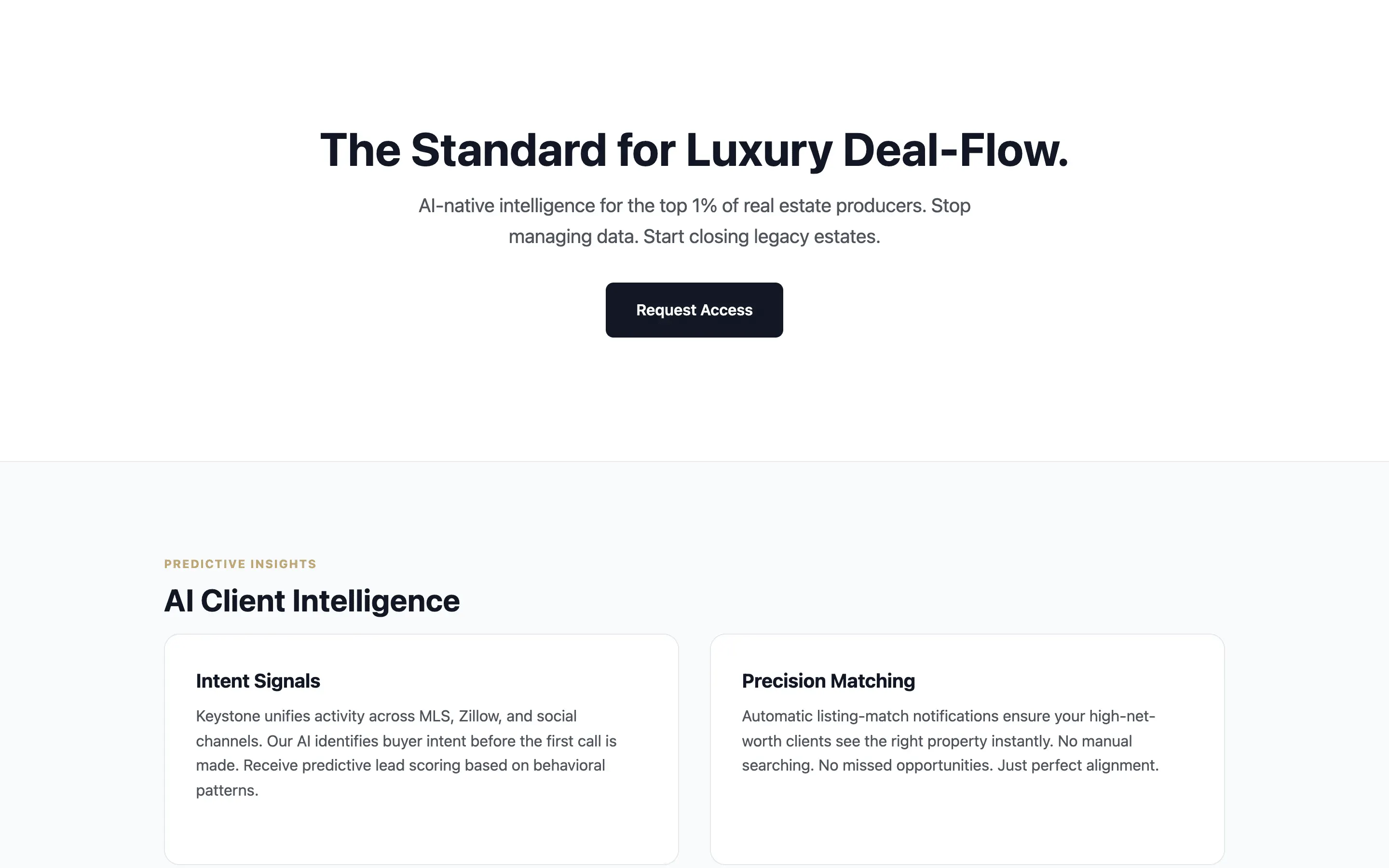
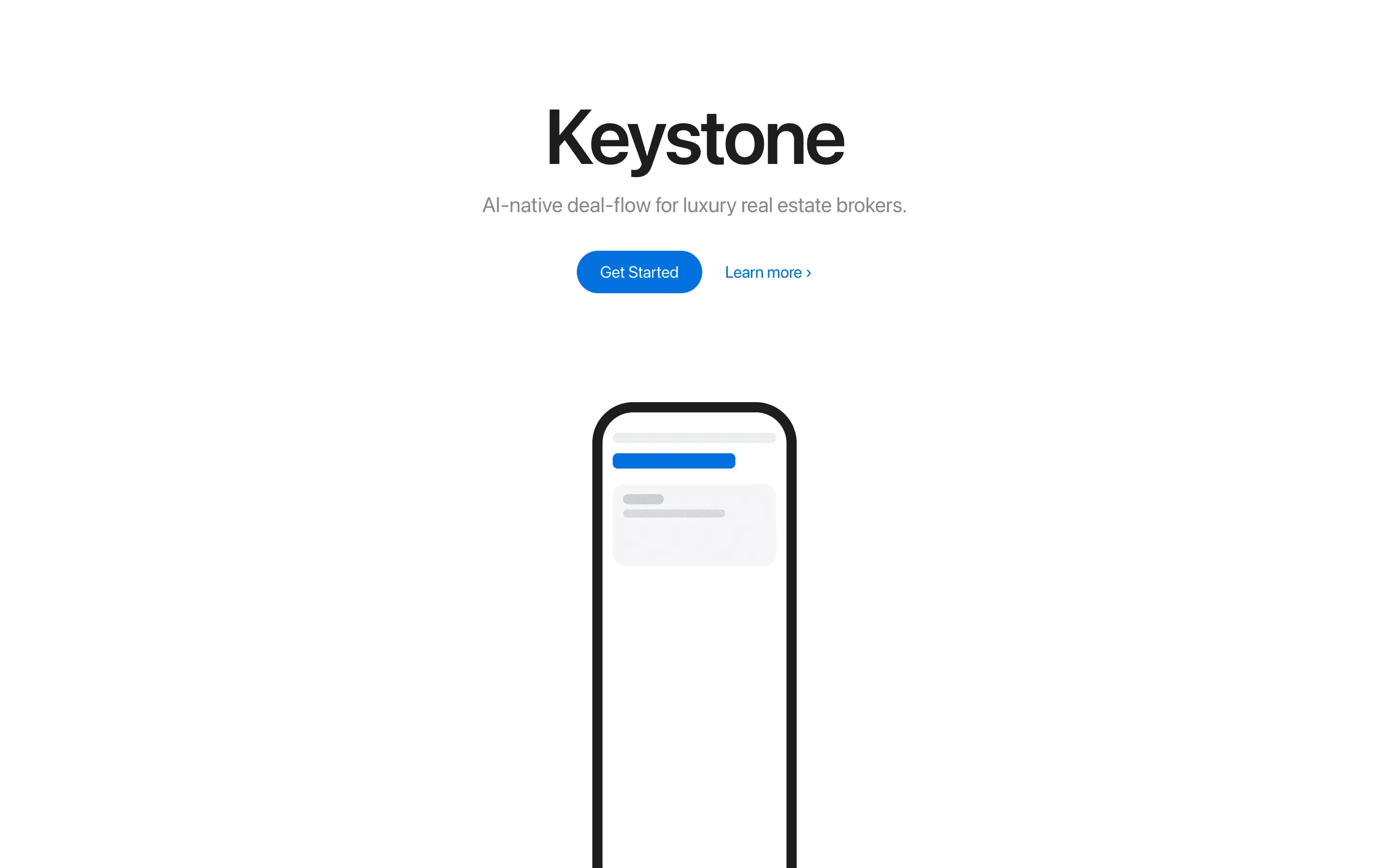
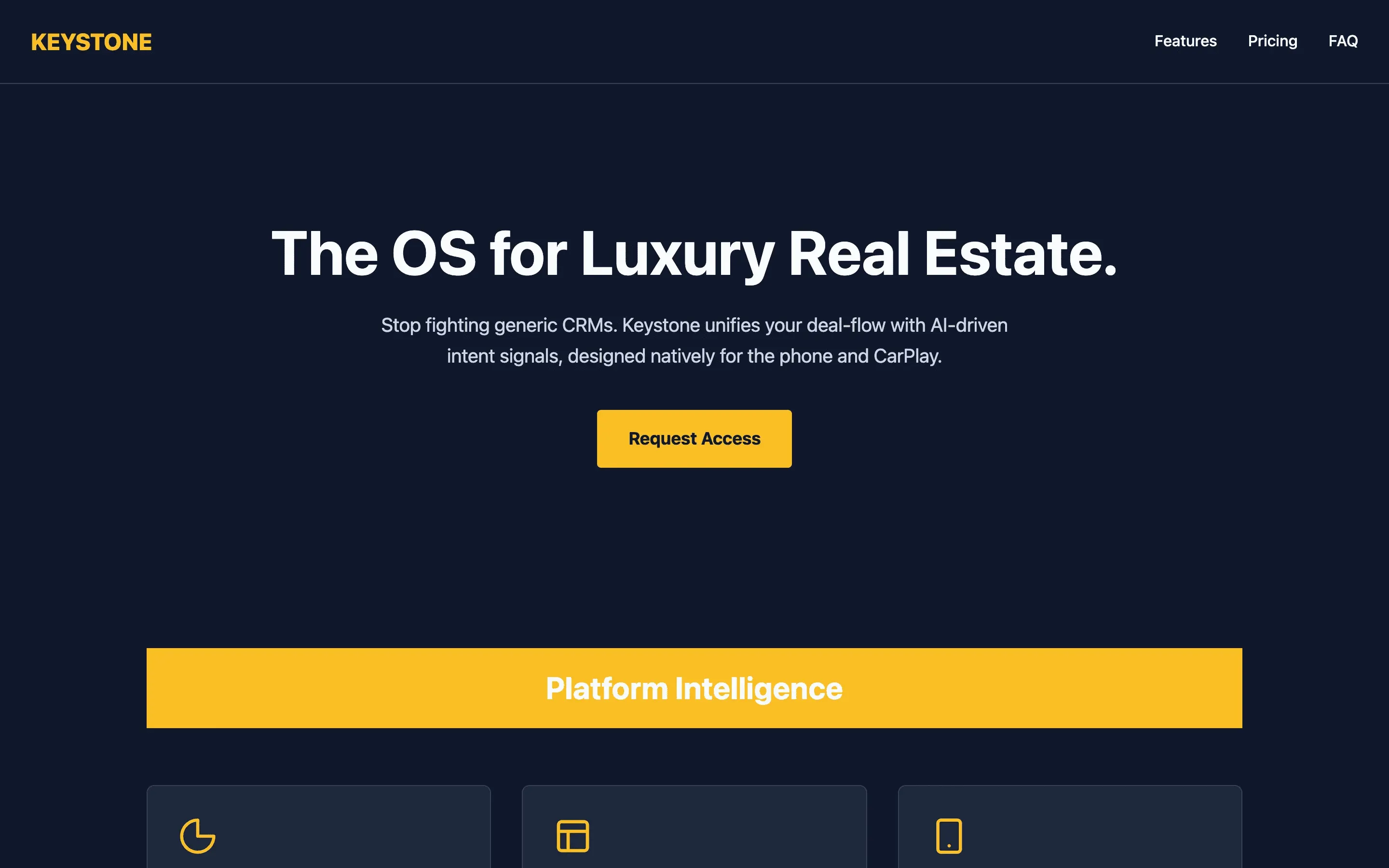

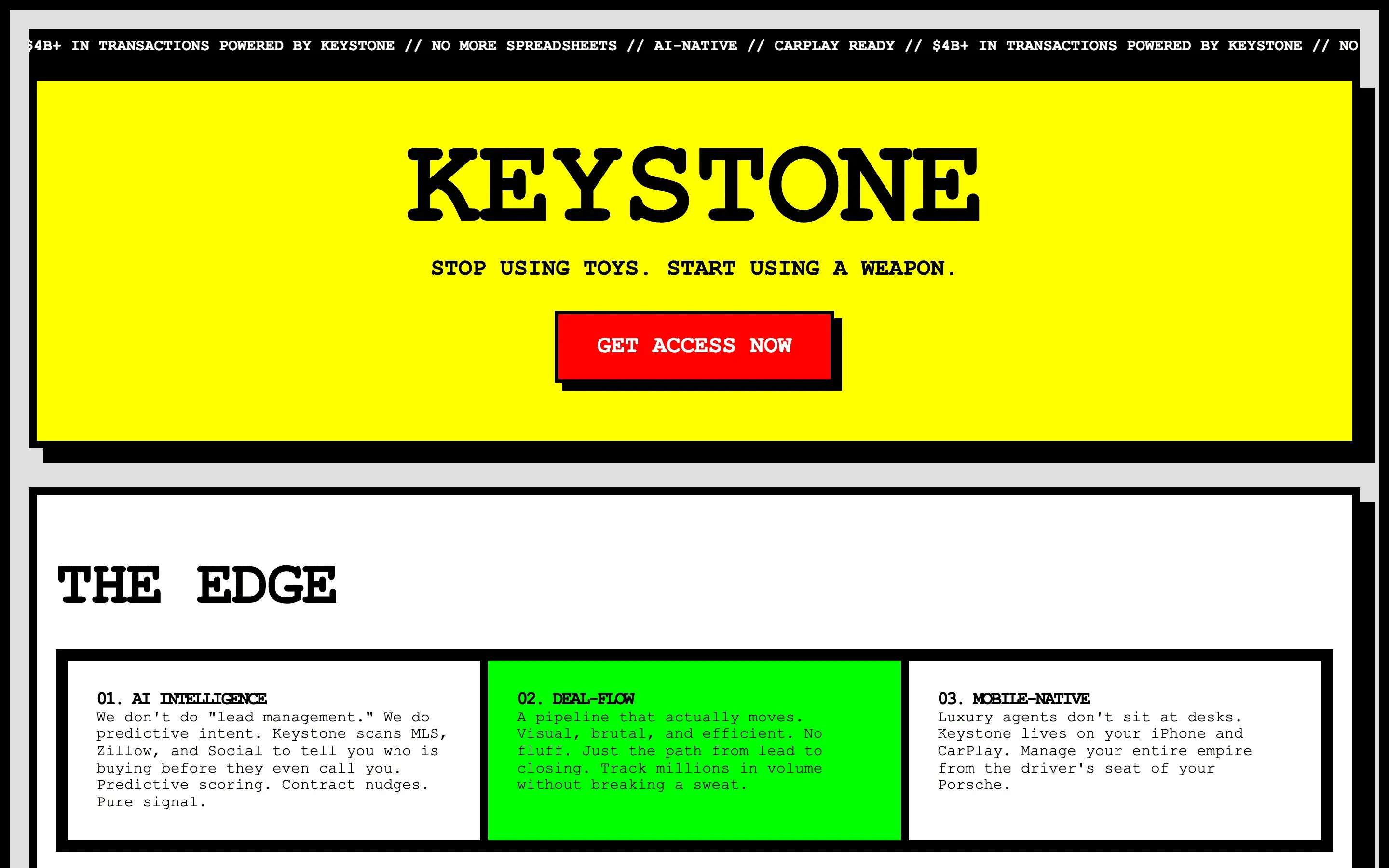



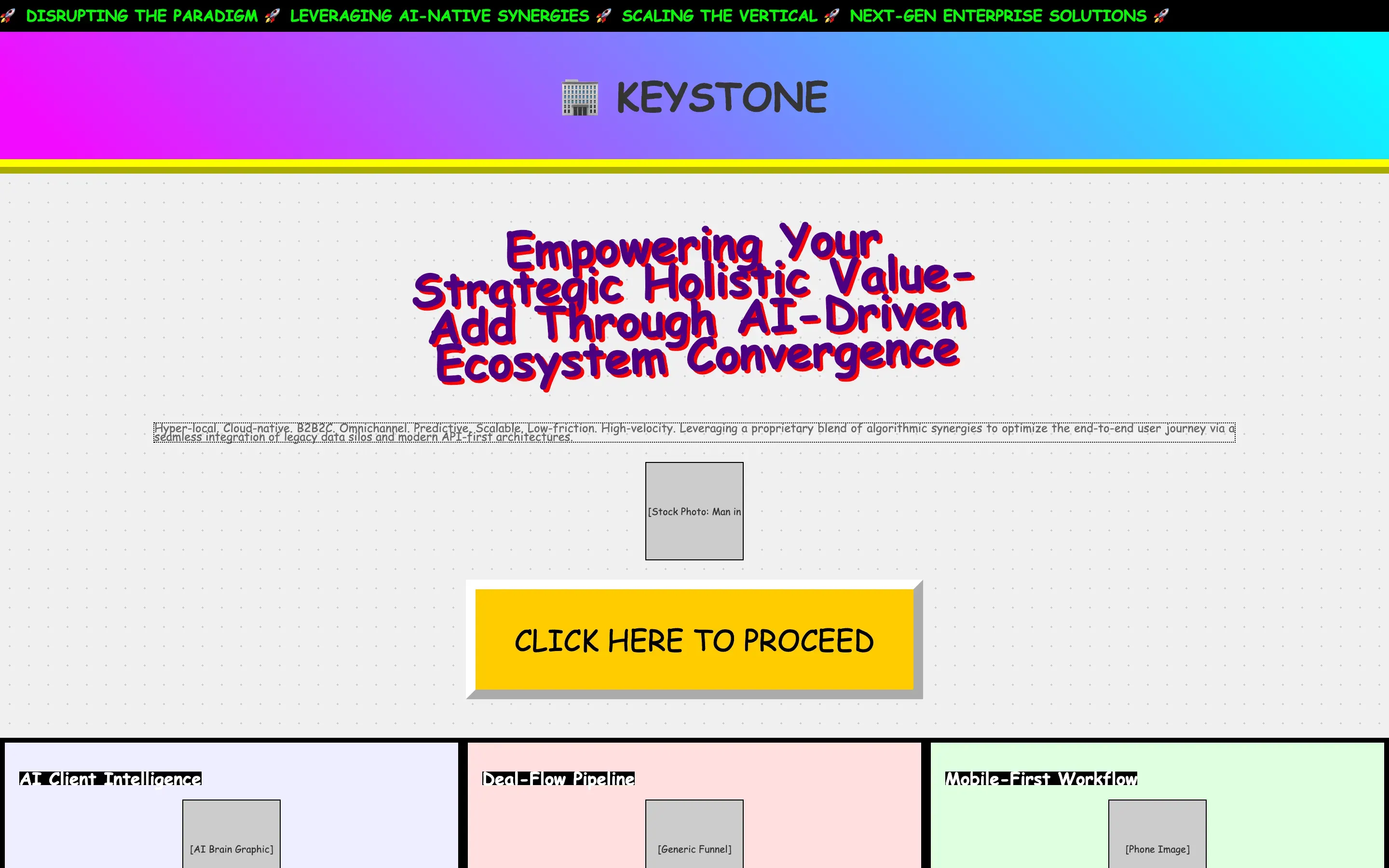

FAQ
Method
Gemma 4 31B Instruct via OpenRouter (paid primary, free fallback), temperature 0.7, max 8192 tokens. One fixed brief: a single-file HTML landing page for a fictional luxury-real-estate CRM called Keystone, 8 required sections, inline styles only.
The only independent variable is the persona. 52 personas across 8 buckets, 3 samples each, for 156 total generations. Everything else is held constant.
Cite this
Rival (2026). The Persona Impact Study: how much a system-prompt persona actually changes a small model's design output. 52 personas, 156 generations, 3 blinded judge waves. rival.tips/research/persona-impact
The full report
The full editorial deck (the long version), plus the JSONL dataset of all 156 generations and the raw HTML responses for every run.
Secure checkout via Lemon Squeezy. Instant download.
Read the free 8-page sample (PDF)
The first 8 pages, free. The full deck is the paid version above.
Rival Research · Prompt Engineering
On a small model (Gemma 4 31B), the right system prompt scored 8.77/10 versus 7.07 with no prompt at all (+1.70). The worst prompt dragged it down to 2.42 (-4.65). Across 52 personas, terse roles and reference-pinned prompts beat rule-dense design-cheat prompts, which scored 6.93, below the 7.00 no-prompt baseline.
Isolating the system-prompt effect
Same model, same brief, same rubric. The only variable is the system prompt. We chose Gemma 4 31B on purpose: a frontier model would mask the signal, the small model's headroom is what makes the effect visible.
By the numbers
The persona explains a meaningful slice of the variance, and three independent judge waves agreed. This is not noise.
Headline finding
Eight personas loaded with design heuristics (Refactoring UI, Tufte, WCAG AA, the Tailwind scale) averaged 6.93. The empty control averaged 7.00. Taste beats rules.
is how far the rule-dense “design-cheat” bucket landed below the blank control. Stuffing the prompt with rules made the output worse.
Design-cheat 6.93 vs baseline 7.00 composite (0–10).
What actually won
The top bucket was meta / structural at 7.70. A one-line reference pin (“build this like vercel.com”) and short role assignments beat every rulebook. The model already knows the rules. It needs a direction and permission to commit.
Each bar is a bucket's mean composite. The faint band is the 95% bootstrap CI, the hairline marks the blank baseline, and lime cleared it.
Several intervals overlap the baseline. The honest read: most persona families do not reliably beat an empty prompt. The real separation is between the worst adversarial personas and everything else.
Every persona by prompt length against composite score. No upward trend. Many of the best results come from prompts under 400 characters. Lime beat the blank baseline.
Persona length vs composite · each dot is one persona
Dots below the dashed baseline are personas that hurt the output. If length were the lever, the cloud would tilt up and to the right. It does not.
Ranked by composite · pulled from the full 52-persona pool
No single prompt shape wins. Terse roles, expansive personas, reasoning scaffolds, and a one-line reference pin all make the top seven.
The full output, nothing hidden. Each tile links to its render, scored by three-judge composite. Lime marks the single best.
FAQ
Method
Gemma 4 31B Instruct via OpenRouter (paid primary, free fallback), temperature 0.7, max 8192 tokens. One fixed brief: a single-file HTML landing page for a fictional luxury-real-estate CRM called Keystone, 8 required sections, inline styles only.
The only independent variable is the persona. 52 personas across 8 buckets, 3 samples each, for 156 total generations. Everything else is held constant.
Cite this
Rival (2026). The Persona Impact Study: how much a system-prompt persona actually changes a small model's design output. 52 personas, 156 generations, 3 blinded judge waves. rival.tips/research/persona-impact
The full report
The full editorial deck (the long version), plus the JSONL dataset of all 156 generations and the raw HTML responses for every run.
Secure checkout via Lemon Squeezy. Instant download.
Read the free 8-page sample (PDF)
The first 8 pages, free. The full deck is the paid version above.